Proxy 和 Reflect
一个 Proxy 对象包装另一个对象并拦截诸如读取/写入属性和其他操作,可以选择自行处理它们,或者透明地允许该对象处理它们。
Proxy 被用于了许多库和某些浏览器框架。在本文中,我们将看到许多实际应用。
Proxy
语法:
let proxy = new Proxy(target, handler)
target—— 是要包装的对象,可以是任何东西,包括函数。handler—— 代理配置:带有“捕捉器”(“traps”,即拦截操作的方法)的对象。比如get捕捉器用于读取target的属性,set捕捉器用于写入target的属性,等等。
对proxy进行操作,如果在handler中存在相应的捕捉器,则它将运行,并且 Proxy 有机会对其进行处理,否则将直接对 target 进行处理。
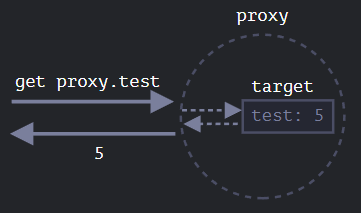
首先,让我们创建一个没有任何捕捉器的代理(Proxy):
let target = {};
let proxy = new Proxy(target, {}); // 空的 handler 对象
proxy.test = 5; // 写入 proxy 对象 (1)
alert(target.test); // 5,test 属性出现在了 target 中!
alert(proxy.test); // 5,我们也可以从 proxy 对象读取它 (2)
for(let key in proxy) alert(key); // test,迭代也正常工作 (3)
由于没有捕捉器,所有对 proxy 的操作都直接转发给了 target。
- 写入操作
proxy.test=会将值写入target。 - 读取操作
proxy.test会从target返回对应的值。 - 迭代
proxy会从target返回对应的值。
我们可以看到,没有任何捕捉器,proxy是一个target的透明包装器(wrapper)。

Proxy是一种特殊的“奇异对象(exotic object)”。它没有自己的属性。如果handler为空,则透明地将操作转发给target。
要激活更多功能,让我们添加捕捉器。
我们可以用它们拦截什么?
对于对象的大多数操作,JavaScript 规范中有一个所谓的“内部方法”,它描述了最底层的工作方式。例如[[Get]],用于读取属性的内部方法,[[Set]],用于写入属性的内部方法,等等。这些方法仅在规范中使用,我们不能直接通过方法名调用它们。
Proxy 捕捉器会拦截这些方法的调用。它们在 proxy 规范 和下表中被列出。
对于每个内部方法,此表中都有一个捕捉器:可用于添加到new Proxy的handler参数中以拦截操作的方法名称:
| 内部方法 | Handler 方法 | 何时触发 |
|---|---|---|
[[Get]] |
get |
读取属性 |
[[Set]] |
set |
写入属性 |
[[HasProperty]] |
has |
in 操作符 |
[[Delete]] |
deleteProperty |
delete 操作符 |
[[Call]] |
apply |
函数调用 |
[[Construct]] |
construct |
new 操作符 |
[[GetPrototypeOf]] |
getPrototypeOf |
Object.getPrototypeOf |
[[SetPrototypeOf]] |
setPrototypeOf |
Object.setPrototypeOf |
[[IsExtensible]] |
isExtensible |
Object.isExtensible |
[[PreventExtensions]] |
preventExtensions |
Object.preventExtensions |
[[DefineOwnProperty]] |
defineProperty |
Object.defineProperty |
| Object.defineProperties | ||
[[GetOwnProperty]] |
getOwnPropertyDescriptor |
Object.getOwnPropertyDescriptor |
for..in |
||
Object.keys/values/entries |
||
[[OwnPropertyKeys]] |
ownKeys |
Object.getOwnPropertyNames |
| Object.getOwnPropertySymbols | ||
for..in |
||
Object.keys/values/entries |
不变量(Invariant)
JavaScript 强制执行某些不变量 —— 内部方法和捕捉器必须满足的条件。
其中大多数用于返回值:
[[Set]]如果值已成功写入,则必须返回true,否则返回false。[[Delete]]如果已成功删除该值,则必须返回true,否则返回false。- ……依此类推,我们将在下面的示例中看到更多内容。
还有其他一些不变量,例如:- 应用于代理(proxy)对象的
[[GetPrototypeOf]],必须返回与应用于被代理对象的[[GetPrototypeOf]]相同的值。换句话说,读取代理对象的原型必须始终返回被代理对象的原型。
捕捉器可以拦截这些操作,但是必须遵循上面这些规则。
不变量确保语言功能的正确和一致的行为。完整的不变量列表在 规范 中。如果你不做奇怪的事情,你可能就不会违反它们。
带有 get 捕捉器的默认值
最常见的捕捉器是用于读取/写入的属性。
要拦截读取操作,handler 应该有 get(target, property, receiver) 方法。
读取属性时触发该方法,参数如下:
target—— 是目标对象,该对象被作为第一个参数传递给new Proxy,property—— 目标属性名,receiver—— 如果目标属性是一个 getter 访问器属性,则receiver就是本次读取属性所在的this对象。通常,这就是proxy对象本身(或者,如果我们从 proxy 继承,则是从该 proxy 继承的对象)。现在我们不需要此参数,因此稍后我们将对其进行详细介绍。
让我们用get来实现一个对象的默认值。
我们将创建一个对不存在的数组项返回0的数组。
通常,当人们尝试获取不存在的数组项时,他们会得到undefined,但是我们在这将常规数组包装到代理(proxy)中,以捕获读取操作,并在没有要读取的属性的时返回0:
let numbers = [0, 1, 2];
numbers = new Proxy(numbers, {
get(target, prop) {
if (prop in target) {
return target[prop];
} else {
return 0; // 默认值
}
}
});
alert( numbers[1] ); // 1
alert( numbers[123] ); // 0(没有这个数组项)
正如我们所看到的,使用 get 捕捉器很容易实现。
我们可以用 Proxy 来实现“默认”值的任何逻辑。
想象一下,我们有一本词典,上面有短语及其翻译:
let dictionary = {
'Hello': 'Hola',
'Bye': 'Adiós'
};
alert( dictionary['Hello'] ); // Hola
alert( dictionary['Welcome'] ); // undefined
现在,如果没有我们要读取的短语,那么从 dictionary 读取它将返回 undefined。但实际上,返回一个未翻译的短语通常比 undefined 要好。因此,让我们在这种情况下返回一个未翻译的短语来替代 undefined。
为此,我们将把 dictionary 包装进一个拦截读取操作的代理:
let dictionary = {
'Hello': 'Hola',
'Bye': 'Adiós'
};
dictionary = new Proxy(dictionary, {
get(target, phrase) { // 拦截读取属性操作
if (phrase in target) { //如果词典中有该短语
return target[phrase]; // 返回其翻译
} else {
// 否则返回未翻译的短语
return phrase;
}
}
});
// 在词典中查找任意短语!
// 最坏的情况也只是它们没有被翻译。
alert( dictionary['Hello'] ); // Hola
alert( dictionary['Welcome to Proxy']); // Welcome to Proxy(没有被翻译)
请注意:
请注意代理如何覆盖变量:
dictionary = new Proxy(dictionary, ...);
代理应该在所有地方都完全替代目标对象。目标对象被代理后,任何人都不应该再引用目标对象。否则很容易搞砸。
使用 set 捕捉器进行验证
假设我们想要一个专门用于数字的数组。如果添加了其他类型的值,则应该抛出一个错误。
当写入属性时 set 捕捉器被触发。
set(target, property, value, receiver):
target—— 是目标对象,该对象被作为第一个参数传递给new Proxy,property—— 目标属性名称,value—— 目标属性的值,receiver—— 与get捕捉器类似,仅与 setter 访问器属性相关。
如果写入操作(setting)成功,set捕捉器应该返回true,否则返回false(触发TypeError)。
让我们用它来验证新值:
let numbers = [];
numbers = new Proxy(numbers, { // (*)
set(target, prop, val) { // 拦截写入属性操作
if (typeof val == 'number') {
target[prop] = val;
return true;
} else {
return false;
}
}
});
numbers.push(1); // 添加成功
numbers.push(2); // 添加成功
alert("Length is: " + numbers.length); // 2
numbers.push("test"); // TypeError(proxy 的 'set' 返回 false)
alert("This line is never reached (error in the line above)");
请注意:数组的内建方法依然有效!值被使用 push 方法添加到数组。当值被添加到数组后,数组的 length 属性会自动增加。我们的代理对象 proxy 不会破坏任何东西。
我们不必重写诸如 push 和 unshift 等添加元素的数组方法,就可以在其中添加检查,因为在内部它们使用代理所拦截的 [[Set]] 操作。
因此,代码简洁明了。
别忘了返回
true
如上所述,要保持不变量。
对于set操作,它必须在成功写入时返回true。
如果我们忘记这样做,或返回任何假(falsy)值,则该操作将触发TypeError。
使用 ownKeys 和 getOwnPropertyDescriptor 进行迭代
Object.keys,for..in 循环和大多数其他遍历对象属性的方法都使用内部方法 [[OwnPropertyKeys]](由 ownKeys 捕捉器拦截) 来获取属性列表。
这些方法在细节上有所不同:
Object.getOwnPropertyNames(obj)返回非 symbol 键。Object.getOwnPropertySymbols(obj)返回 symbol 键。Object.keys/values()返回带有enumerable标志的非 symbol 键/值(属性标志在 属性标志和属性描述符 一章有详细讲解)。for..in循环遍历所有带有enumerable标志的非 symbol 键,以及原型对象的键。
……但是所有这些都从该列表开始。
在下面这个示例中,我们使用ownKeys捕捉器拦截for..in对user的遍历,并使用Object.keys和Object.values来跳过以下划线_开头的属性:
let user = {
name: "John",
age: 30,
_password: "***"
};
user = new Proxy(user, {
ownKeys(target) {
return Object.keys(target).filter(key => !key.startsWith('_'));
}
});
// "ownKeys" 过滤掉了 _password
for(let key in user) alert(key); // name,然后是 age
// 对这些方法的效果相同:
alert( Object.keys(user) ); // name,age
alert( Object.values(user) ); // John,30
到目前为止,它仍然有效。
尽管如此,但如果我们返回对象中不存在的键,Object.keys 并不会列出这些键:
let user = { };
user = new Proxy(user, {
ownKeys(target) {
return ['a', 'b', 'c'];
}
});
alert( Object.keys(user) ); // <empty>
为什么?原因很简单:Object.keys 仅返回带有 enumerable 标志的属性。为了检查它,该方法会对每个属性调用内部方法 [[GetOwnProperty]] 来获取 它的描述符(descriptor)。在这里,由于没有属性,其描述符为空,没有 enumerable 标志,因此它被略过。
为了让 Object.keys 返回一个属性,我们需要它要么存在于带有 enumerable 标志的对象,要么我们可以拦截对 [[GetOwnProperty]] 的调用(捕捉器 getOwnPropertyDescriptor 可以做到这一点),并返回带有 enumerable: true 的描述符。
这是关于此的一个例子:
let user = { };
user = new Proxy(user, {
ownKeys(target) { // 一旦要获取属性列表就会被调用
return ['a', 'b', 'c'];
},
getOwnPropertyDescriptor(target, prop) { // 被每个属性调用
return {
enumerable: true,
configurable: true
/* ...其他标志,可能是 "value:..." */
};
}
});
alert( Object.keys(user) ); // a, b, c
让我们再次注意:如果该属性在对象中不存在,那么我们只需要拦截 [[GetOwnProperty]]。
具有 deleteProperty 和其他捕捉器的受保护属性
有一个普遍的约定,即以下划线 _ 开头的属性和方法是内部的。不应从对象外部访问它们。
从技术上讲,我们也是能访问到这样的属性的:
let user = {
name: "John",
_password: "secret"
};
alert(user._password); // secret
让我们使用代理来防止对以 _ 开头的属性的任何访问。
我们将需要以下捕捉器:
get读取此类属性时抛出错误,set写入属性时抛出错误,deleteProperty删除属性时抛出错误,ownKeys在使用for..in和像Object.keys这样的方法时排除以_开头的属性。
代码如下:
let user = {
name: "John",
_password: "***"
};
user = new Proxy(user, {
get(target, prop) {
if (prop.startsWith('_')) {
throw new Error("Access denied");
}
let value = target[prop];
return (typeof value === 'function') ? value.bind(target) : value; // (*)
},
set(target, prop, val) { // 拦截属性写入
if (prop.startsWith('_')) {
throw new Error("Access denied");
} else {
target[prop] = val;
return true;
}
},
deleteProperty(target, prop) { // 拦截属性删除
if (prop.startsWith('_')) {
throw new Error("Access denied");
} else {
delete target[prop];
return true;
}
},
ownKeys(target) { // 拦截读取属性列表
return Object.keys(target).filter(key => !key.startsWith('_'));
}
});
// "get" 不允许读取 _password
try {
alert(user._password); // Error: Access denied
} catch(e) { alert(e.message); }
// "set" 不允许写入 _password
try {
user._password = "test"; // Error: Access denied
} catch(e) { alert(e.message); }
// "deleteProperty" 不允许删除 _password
try {
delete user._password; // Error: Access denied
} catch(e) { alert(e.message); }
// "ownKeys" 将 _password 过滤出去
for(let key in user) alert(key); // name
请注意在 (*) 行中 get 捕捉器的重要细节:
get(target, prop) {
// ...
let value = target[prop];
return (typeof value === 'function') ? value.bind(target) : value; // (*)
}
为什么我们需要一个函数去调用 value.bind(target)?
原因是对象方法(例如 user.checkPassword())必须能够访问 _password:
user = {
// ...
checkPassword(value) {
//对象方法必须能读取 _password
return value === this._password;
}
}
对 user.checkPassword() 的调用会将被代理的对象 user 作为 this(点符号之前的对象会成为 this),因此,当它尝试访问 this._password 时,get 捕捉器将激活(在任何属性读取时,它都会被触发)并抛出错误。
因此,我们在 (*) 行中将对象方法的上下文绑定到原始对象 target。然后,它们将来的调用将使用 target 作为 this,不会触发任何捕捉器。
该解决方案通常可行,但并不理想,因为一个方法可能会将未被代理的对象传递到其他地方,然后我们就会陷入困境:原始对象在哪里,被代理的对象在哪里?
此外,一个对象可能会被代理多次(多个代理可能会对该对象添加不同的“调整”),并且如果我们将未包装的对象传递给方法,则可能会产生意想不到的后果。
因此,在任何地方都不应使用这种代理。
类的私有属性
现代 JavaScript 引擎原生支持 class 中的私有属性,这些私有属性以#为前缀。它们在 私有的和受保护的属性和方法 一章中有详细描述。无需代理(proxy)。
但是,此类属性有其自身的问题。特别是,它们是不可继承的。
带有 has 捕捉器的 in range
让我们来看更多示例。
我们有一个 range 对象:
let range = {
start: 1,
end: 10
};
我们想使用 in 操作符来检查一个数字是否在 range 范围内。
has 捕捉器会拦截 in 调用。
has(target, property)
target—— 是目标对象,被作为第一个参数传递给new Proxy,property—— 属性名称。
let range = {
start: 1,
end: 10
};
range = new Proxy(range, {
has(target, prop) {
return prop >= target.start && prop <= target.end;
}
});
alert(5 in range); // true
alert(50 in range); // false
漂亮的语法糖,不是吗?而且实现起来非常简单。
包装函数 apply
我们也可以将代理(proxy)包装在函数周围。
apply(target, thisArg, args) 捕捉器能使代理以函数的方式被调用:
target是目标对象(在 JavaScript 中,函数就是一个对象),thisArg是this的值。args是参数列表。
例如,让我们回忆一下我们在 装饰器模式和转发,call/apply 一章中所讲的delay(f, ms)装饰器。
在该章中,我们没有用 proxy 来实现它。调用delay(f, ms)会返回一个函数,该函数会在ms毫秒后把所有调用转发给f。
这是以前的基于函数的实现:
function delay(f, ms) {
// 返回一个包装器(wrapper),该包装器将在时间到了的时候将调用转发给函数 f
return function() { // (*)
setTimeout(() => f.apply(this, arguments), ms);
};
}
function sayHi(user) {
alert(`Hello, ${user}!`);
}
// 在进行这个包装后,sayHi 函数会被延迟 3 秒后被调用
sayHi = delay(sayHi, 3000);
sayHi("John"); // Hello, John! (after 3 seconds)
正如我们所看到的那样,大多数情况下它都是可行的。包装函数 (*) 在到达延迟的时间后后执行调用。
但是包装函数不会转发属性读取/写入操作或者任何其他操作。进行包装后,就失去了对原始函数属性的访问,例如 name,length 和其他属性:
function delay(f, ms) {
return function() {
setTimeout(() => f.apply(this, arguments), ms);
};
}
function sayHi(user) {
alert(`Hello, ${user}!`);
}
alert(sayHi.length); // 1(函数的 length 是函数声明中的参数个数)
sayHi = delay(sayHi, 3000);
alert(sayHi.length); // 0(在包装器声明中,参数个数为 0)
Proxy 的功能要强大得多,因为它可以将所有东西转发到目标对象。
让我们使用 Proxy 来替换掉包装函数:
function delay(f, ms) {
return new Proxy(f, {
apply(target, thisArg, args) {
setTimeout(() => target.apply(thisArg, args), ms);
}
});
}
function sayHi(user) {
alert(`Hello, ${user}!`);
}
sayHi = delay(sayHi, 3000);
alert(sayHi.length); // 1 (*) proxy 将“获取 length”的操作转发给目标对象
sayHi("John"); // Hello, John!(3 秒后)
结果是相同的,但现在不仅仅调用,而且代理上的所有操作都能被转发到原始函数。所以在 (*) 行包装后的 sayHi.length 会返回正确的结果。
我们得到了一个“更丰富”的包装器。
还存在其他捕捉器:完整列表在本文的开头。它们的使用模式与上述类似。
Reflect
Reflect 是一个内建对象,可简化 Proxy 的创建。
前面所讲过的内部方法,例如 [[Get]] 和 [[Set]] 等,都只是规范性的,不能直接调用。
Reflect 对象使调用这些内部方法成为了可能。它的方法是内部方法的最小包装。
以下是执行相同操作和 Reflect 调用的示例:
| 操作 | Reflect 调用 |
内部方法 |
|---|---|---|
obj[prop] |
Reflect.get(obj, prop) |
[[Get]] |
obj[prop] = value |
Reflect.set(obj, prop, value) |
[[Set]] |
delete obj[prop] |
Reflect.deleteProperty(obj, prop) |
[[Delete]] |
new F(value) |
Reflect.construct(F, value) |
[[Construct]] |
| … | … | … |
例如
let user = {};
Reflect.set(user, 'name', 'John');
alert(user.name); // John
尤其是,Reflect 允许我们将操作符(new,delete,……)作为函数(Reflect.construct,Reflect.deleteProperty,……)执行调用。这是一个有趣的功能,但是这里还有一点很重要。
对于每个可被 Proxy 捕获的内部方法,在 Reflect 中都有一个对应的方法,其名称和参数与 Proxy 捕捉器相同。
所以,我们可以使用 Reflect 来将操作转发给原始对象。
在下面这个示例中,捕捉器 get 和 set 均透明地(好像它们都不存在一样)将读取/写入操作转发到对象,并显示一条消息:
let user = {
name: "John",
};
user = new Proxy(user, {
get(target, prop, receiver) {
alert(`GET ${prop}`);
return Reflect.get(target, prop, receiver); // (1)
},
set(target, prop, val, receiver) {
alert(`SET ${prop}=${val}`);
return Reflect.set(target, prop, val, receiver); // (2)
}
});
let name = user.name; // 显示 "GET name"
user.name = "Pete"; // 显示 "SET name=Pete"
这里:
Reflect.get读取一个对象属性。Reflect.set写入一个对象属性,如果写入成功则返回true,否则返回false。
这样,一切都很简单:如果一个捕捉器想要将调用转发给对象,则只需使用相同的参数调用Reflect.<method>就足够了。
在大多数情况下,我们可以不使用Reflect完成相同的事情,例如,用于读取属性的Reflect.get(target, prop, receiver)可以被替换为target[prop]。尽管有一些细微的差别。
代理一个 getter
让我们看一个示例,来说明为什么 Reflect.get 更好。此外,我们还将看到为什么 get/set 有第三个参数 receiver,而且我们之前从来没有使用过它。
我们有一个带有 _name 属性和 getter 的对象 user。
这是对 user 对象的一个代理:
let user = {
_name: "Guest",
get name() {
return this._name;
}
};
let userProxy = new Proxy(user, {
get(target, prop, receiver) {
return target[prop];
}
});
alert(userProxy.name); // Guest
其 get 捕捉器在这里是“透明的”,它返回原来的属性,不会做任何其他的事。这对于我们的示例而言就足够了。
一切似乎都很好。但是让我们将示例变得稍微复杂一点。
另一个对象 admin 从 user 继承后,我们可以观察到错误的行为:
let user = {
_name: "Guest",
get name() {
return this._name;
}
};
let userProxy = new Proxy(user, {
get(target, prop, receiver) {
return target[prop]; // (*) target = user
}
});
let admin = {
__proto__: userProxy,
_name: "Admin"
};
// 期望输出:Admin
alert(admin.name); // 输出:Guest (?!?)
读取 admin.name 应该返回 "Admin",而不是 "Guest"!
发生了什么?或许我们在继承方面做错了什么?
但是,如果我们移除代理,那么一切都会按预期进行。
问题实际上出在代理中,在 (*) 行。
- 当我们读取
admin.name时,由于admin对象自身没有对应的属性,搜索将转到其原型。 - 原型是
userProxy。 - 从代理读取
name属性时,get捕捉器会被触发,并从原始对象返回target[prop]属性,在(*)行。
当调用target[prop]时,若prop是一个 getter,它将在this=target上下文中运行其代码。因此,结果是来自原始对象target的this._name,即来自user。
为了解决这种情况,我们需要get捕捉器的第三个参数receiver。它保证将正确的this传递给 getter。在我们的例子中是admin。
如何把上下文传递给 getter?对于一个常规函数,我们可以使用call/apply,但这是一个 getter,它不能“被调用”,只能被访问。
Reflect.get可以做到。如果我们使用它,一切都会正常运行。
这是更正后的变体:
let user = {
_name: "Guest",
get name() {
return this._name;
}
};
let userProxy = new Proxy(user, {
get(target, prop, receiver) { // receiver = admin
return Reflect.get(target, prop, receiver); // (*)
}
});
let admin = {
__proto__: userProxy,
_name: "Admin"
};
alert(admin.name); // Admin
现在 receiver 保留了对正确 this 的引用(即 admin),该引用是在 (*) 行中被通过 Reflect.get 传递给 getter 的。
我们可以把捕捉器重写得更短:
get(target, prop, receiver) {
return Reflect.get(...arguments);
}
Reflect 调用的命名与捕捉器的命名完全相同,并且接受相同的参数。它们是以这种方式专门设计的。
因此,return Reflect... 提供了一个安全的方式,可以轻松地转发操作,并确保我们不会忘记与此相关的任何内容。
Proxy 的局限性
代理提供了一种独特的方法,可以在最底层更改或调整现有对象的行为。但是,它并不完美。有局限性。
内建对象,内部插槽 Internal slot
许多内建对象,例如 Map,Set,Date,Promise 等,都使用了所谓的“内部插槽”。
它们类似于属性,但仅限于内部使用,仅用于规范目的。例如,Map 将项目(item)存储在 [[MapData]] 中。内建方法可以直接访问它们,而不通过 [[Get]]/[[Set]] 内部方法。所以 Proxy 无法拦截它们。
为什么要在意这些呢?毕竟它们是内部的!
好吧,问题在这儿。在类似这样的内建对象被代理后,代理对象没有这些内部插槽,因此内建方法将会失败。
例如:
let map = new Map();
let proxy = new Proxy(map, {});
proxy.set('test', 1); // Error
在内部,一个 Map 将所有数据存储在其 [[MapData]] 内部插槽中。代理对象没有这样的插槽。内建方法 Map.prototype.set 方法试图访问内部属性 this.[[MapData]],但由于 this=proxy,在 proxy 中无法找到它,只能失败。
幸运的是,这有一种解决方法:
let map = new Map();
let proxy = new Proxy(map, {
get(target, prop, receiver) {
let value = Reflect.get(...arguments);
return typeof value == 'function' ? value.bind(target) : value;
}
});
proxy.set('test', 1);
alert(proxy.get('test')); // 1(工作了!)
现在它正常工作了,因为 get 捕捉器将函数属性(例如 map.set)绑定到了目标对象(map)本身。
与前面的示例不同,proxy.set(...) 内部 this 的值并不是 proxy,而是原始的 map。因此,当set 捕捉器的内部实现尝试访问 this.[[MapData]] 内部插槽时,它会成功。
Array没有内部插槽
一个值得注意的例外:内建Array没有使用内部插槽。那是出于历史原因,因为它出现于很久以前。
所以,代理数组时没有这种问题。
私有字段
类的私有字段也会发生类似的情况。
例如,getName() 方法访问私有的 #name 属性,并在代理后中断:
class User {
#name = "Guest";
getName() {
return this.#name;
}
}
let user = new User();
user = new Proxy(user, {});
alert(user.getName()); // Error
原因是私有字段是通过内部插槽实现的。JavaScript 在访问它们时不使用 [[Get]]/[[Set]]。
在调用 getName() 时,this 的值是代理后的 user,它没有带有私有字段的插槽。
再次,带有 bind 方法的解决方案使它恢复正常:
class User {
#name = "Guest";
getName() {
return this.#name;
}
}
let user = new User();
user = new Proxy(user, {
get(target, prop, receiver) {
let value = Reflect.get(...arguments);
return typeof value == 'function' ? value.bind(target) : value;
}
});
alert(user.getName()); // Guest
如前所述,该解决方案也有缺点:它将原始对象暴露给该方法,可能使其进一步传递并破坏其他代理功能。
Proxy != target
代理和原始对象是不同的对象。这很自然,对吧?
所以,如果我们使用原始对象作为键,然后对其进行代理,之后却无法找到代理了:
let allUsers = new Set();
class User {
constructor(name) {
this.name = name;
allUsers.add(this);
}
}
let user = new User("John");
alert(allUsers.has(user)); // true
user = new Proxy(user, {});
alert(allUsers.has(user)); // false
如我们所见,进行代理后,我们在 allUsers 中找不到 user,因为代理是一个不同的对象。
Proxy 无法拦截严格相等性检查
===
Proxy 可以拦截许多操作符,例如new(使用construct),in(使用has),delete(使用deleteProperty)等。
但是没有办法拦截对于对象的严格相等性检查。一个对象只严格等于其自身,没有其他值。
因此,比较对象是否相等的所有操作和内建类都会区分对象和代理。这里没有透明的替代品。
可撤销 Proxy
一个 可撤销 的代理是可以被禁用的代理。
假设我们有一个资源,并且想随时关闭对该资源的访问。
我们可以做的是将它包装成可一个撤销的代理,没有任何捕捉器。这样的代理会将操作转发给对象,并且我们可以随时将其禁用。
语法为:
let {proxy, revoke} = Proxy.revocable(target, handler)
该调用返回一个带有 proxy 和 revoke 函数的对象以将其禁用。
这是一个例子:
let object = {
data: "Valuable data"
};
let {proxy, revoke} = Proxy.revocable(object, {});
// 将 proxy 传递到其他某处,而不是对象...
alert(proxy.data); // Valuable data
// 稍后,在我们的代码中
revoke();
// proxy 不再工作(revoked)
alert(proxy.data); // Error
对 revoke() 的调用会从代理中删除对目标对象的所有内部引用,因此它们之间再无连接。
最初,revoke 与 proxy 是分开的,因此我们可以传递 proxy,同时将 revoke 留在当前范围内。
我们也可以通过设置 proxy.revoke = revoke 来将 revoke 绑定到 proxy。
另一种选择是创建一个 WeakMap,其中 proxy 作为键,相应的 revoke 作为值,这样可以轻松找到 proxy 所对应的 revoke:
let revokes = new WeakMap();
let object = {
data: "Valuable data"
};
let {proxy, revoke} = Proxy.revocable(object, {});
revokes.set(proxy, revoke);
// ...我们代码中的其他位置...
revoke = revokes.get(proxy);
revoke();
alert(proxy.data); // Error(revoked)
此处我们使用 WeakMap 而不是 Map,因为它不会阻止垃圾回收。如果一个代理对象变得“不可访问”(例如,没有变量再引用它),则 WeakMap 允许将其与它的 revoke 一起从内存中清除,因为我们不再需要它了。
MORE
Eval:执行代码字符串
内建函数 eval 允许执行一个代码字符串。
语法如下:
let result = eval(code);
例如:
let code = 'alert("Hello")';
eval(code); // Hello
代码字符串可能会比较长,包含换行符、函数声明和变量等。
eval 的结果是最后一条语句的结果。
例如:
let value = eval('1+1');
alert(value); // 2
let value = eval('let i = 0; ++i');
alert(value); // 1
eval 内的代码在当前词法环境(lexical environment)中执行,因此它能访问外部变量:
let a = 1;
function f() {
let a = 2;
eval('alert(a)'); // 2
}
f();
它也可以更改外部变量:
let x = 5;
eval("x = 10");
alert(x); // 10,值被更改了
严格模式下,eval 有属于自己的词法环境。因此我们不能从外部访问在 eval 中声明的函数和变量:
// 提示:本教程所有可运行的示例都默认启用了严格模式 'use strict'
eval("let x = 5; function f() {}");
alert(typeof x); // undefined(没有这个变量)
// 函数 f 也不可从外部进行访问
如果不启用严格模式,eval 没有属于自己的词法环境,因此我们可以从外部访问变量 x 和函数 f。
使用 eval
现代编程中,已经很少使用 eval 了。人们经常说“eval 是魔鬼”。
原因很简单:很久很久以前,JavaScript 是一种非常弱的语言,很多东西只能通过 eval 来完成。不过那已经是十年前的事了。
如今几乎找不到使用 eval 的理由了。如果有人在使用它,那这是一个很好的使用现代语言结构或 JavaScript Module 来替换它们的机会。
请注意,eval 访问外部变量的能力会产生副作用。
代码压缩工具(在把 JS 投入生产环境前对其进行压缩的工具)将局部变量重命名为更短的变量(例如 a 和 b 等),以使代码体积更小。这通常是安全的,但在使用了 eval 的情况下就不一样了,因为局部变量可能会被 eval 中的代码访问到。因此压缩工具不会对所有可能会被从 eval 中访问的变量进行重命名。这样会导致代码压缩率降低。
在 eval 中使用外部局部变量也被认为是一个坏的编程习惯,因为这会使代码维护变得更加困难。
有两种方法可以完全避免此类问题。
如果 eval 中的代码没有使用外部变量,请以 window.eval(...) 的形式调用 eval:
通过这种方式,该代码便会在全局作用域内执行:
let x = 1;
{
let x = 5;
window.eval('alert(x)'); // 1(全局变量)
}
如果 eval 中的代码需要访问局部变量,我们可以使用 new Function 替代 eval,并将它们作为参数传递:
let f = new Function('a', 'alert(a)');
f(5); // 5
我们在 "new Function" 语法 一章中对 new Function 构造器进行了详细说明。new Function 从字符串创建一个函数,并且也是在全局作用域中的。所以它无法访问局部变量。但是,正如上面的示例一样,将它们作为参数进行显式传递要清晰得多。
柯里化 Currying
柯里化(Currying)是一种关于函数的高阶技术。它不仅被用于 JavaScript,还被用于其他编程语言。
柯里化是一种函数的转换,它是指将一个函数从可调用的 f(a, b, c) 转换为可调用的 f(a)(b)(c)。
柯里化不会调用函数。它只是对函数进行转换。
让我们先来看一个例子,以更好地理解我们正在讲的内容,然后再进行一个实际应用。
我们将创建一个辅助函数 curry(f),该函数将对两个参数的函数 f 执行柯里化。换句话说,对于两个参数的函数 f(a, b) 执行 curry(f) 会将其转换为以 f(a)(b) 形式运行的函数:
function curry(f) { // curry(f) 执行柯里化转换
return function(a) {
return function(b) {
return f(a, b);
};
};
}
// 用法
function sum(a, b) {
return a + b;
}
let curriedSum = curry(sum);
alert( curriedSum(1)(2) ); // 3
正如你所看到的,实现非常简单:只有两个包装器(wrapper)。
curry(func)的结果就是一个包装器function(a)。- 当它被像
curriedSum(1)这样调用时,它的参数会被保存在词法环境中,然后返回一个新的包装器function(b)。 - 然后这个包装器被以
2为参数调用,并且,它将该调用传递给原始的sum函数。
柯里化更高级的实现,例如 lodash 库的 _.curry,会返回一个包装器,该包装器允许函数被正常调用或者以部分应用函数(partial)的方式调用:
function sum(a, b) {
return a + b;
}
let curriedSum = _.curry(sum); // 使用来自 lodash 库的 _.curry
alert( curriedSum(1, 2) ); // 3,仍可正常调用
alert( curriedSum(1)(2) ); // 3,以部分应用函数的方式调用
柯里化?目的是什么?
要了解它的好处,我们需要一个实际中的例子。
例如,我们有一个用于格式化和输出信息的日志(logging)函数 log(date, importance, message)。在实际项目中,此类函数具有很多有用的功能,例如通过网络发送日志(log),在这儿我们仅使用 alert:
function log(date, importance, message) {
alert(`[${date.getHours()}:${date.getMinutes()}] [${importance}] ${message}`);
}
让我们将它柯里化!
log = _.curry(log);
柯里化之后,log 仍正常运行:
log(new Date(), "DEBUG", "some debug"); // log(a, b, c)
……但是也可以以柯里化形式运行:
log(new Date())("DEBUG")("some debug"); // log(a)(b)(c)
现在,我们可以轻松地为当前日志创建便捷函数:
// logNow 会是带有固定第一个参数的日志的部分应用函数
let logNow = log(new Date());
// 使用它
logNow("INFO", "message"); // [HH:mm] INFO message
现在,logNow 是具有固定第一个参数的 log,换句话说,就是更简短的“部分应用函数(partially applied function)”或“部分函数(partial)”。
我们可以更进一步,为当前的调试日志(debug log)提供便捷函数:
let debugNow = logNow("DEBUG");
debugNow("message"); // [HH:mm] DEBUG message
所以:
- 柯里化之后,我们没有丢失任何东西:
log依然可以被正常调用。 - 我们可以轻松地生成部分应用函数,例如用于生成今天的日志的部分应用函数。
高级柯里化实现
如果你想了解更多细节,下面是用于多参数函数的“高级”柯里化实现,我们也可以把它用于上面的示例。
它非常短:
function curry(func) {
return function curried(...args) {
if (args.length >= func.length) {
return func.apply(this, args);
} else {
return function(...args2) {
return curried.apply(this, args.concat(args2));
}
}
};
}
用例:
function sum(a, b, c) {
return a + b + c;
}
let curriedSum = curry(sum);
alert( curriedSum(1, 2, 3) ); // 6,仍然可以被正常调用
alert( curriedSum(1)(2,3) ); // 6,对第一个参数的柯里化
alert( curriedSum(1)(2)(3) ); // 6,全柯里化
新的 curry 可能看上去有点复杂,但是它很容易理解。
curry(func) 调用的结果是如下所示的包装器 curried:
// func 是要转换的函数
function curried(...args) {
if (args.length >= func.length) { // (1)
return func.apply(this, args);
} else {
return function(...args2) { // (2)
return curried.apply(this, args.concat(args2));
}
}
};
当我们运行它时,这里有两个 if 执行分支:
- 如果传入的
args长度与原始函数所定义的(func.length)相同或者更长,那么只需要使用func.apply将调用传递给它即可。 - 否则,获取一个部分应用函数:我们目前还没调用
func。取而代之的是,返回另一个包装器pass,它将重新应用curried,将之前传入的参数与新的参数一起传入。
然后,如果我们再次调用它,我们将得到一个新的部分应用函数(如果没有足够的参数),或者最终的结果。
只允许确定参数长度的函数
柯里化要求函数具有固定数量的参数。
使用 rest 参数的函数,例如f(...args),不能以这种方式进行柯里化。
比柯里化多一点
根据定义,柯里化应该将sum(a, b, c)转换为sum(a)(b)(c)。
但是,如前所述,JavaScript 中大多数的柯里化实现都是高级版的:它们使得函数可以被多参数变体调用。
Reference Type
深入的语言特性
本文所讲的是一个高阶主题,能帮你更好地理解一些边缘情况。
这仅是锦上添花。许多经验丰富的开发者不甚了了也过得不错。如果你想了解代码运行的本质,那就继续读下去吧。
一个动态执行的方法调用可能会丢失 this。
例如:
let user = {
name: "John",
hi() { alert(this.name); },
bye() { alert("Bye"); }
};
user.hi(); // 正常运行
// 现在让我们基于 name 来选择调用 user.hi 或 user.bye
(user.name == "John" ? user.hi : user.bye)(); // Error!
在最后一行有个在 user.hi 和 user.bye 中做选择的条件(三元)运算符。当前情形下的结果是 user.hi。
接着该方法被通过 () 立刻调用。但是并不能正常工作!
如你所见,此处调用导致了一个错误,因为在该调用中 "this" 的值变成了 undefined。
这样是能工作的(对象.方法):
user.hi();
这就无法工作了(被评估的方法):
(user.name == "John" ? user.hi : user.bye)(); // Error!
为什么呢?欲知缘何,且让我们深入 obj.method() 调用运行的本质。
Reference type 解读
仔细看的话,我们可能注意到 obj.method() 语句中的两个操作:
- 首先,点
'.'取了属性obj.method的值。 - 接着
()执行了它。
那么,this的信息是怎么从第一部分传递到第二部分的呢?
如果我们将这些操作放在不同的行,this必定是会丢失的:
let user = {
name: "John",
hi() { alert(this.name); }
};
// 把获取方法和调用方法拆成两行
let hi = user.hi;
hi(); // 报错了,因为 this 的值是 undefined
这里 hi = user.hi 把函数赋值给了一个变量,接下来在最后一行它是完全独立的,所以这里没有 this。
为确保 user.hi() 调用正常运行,JavaScript 玩了个小把戏 —— 点 '.' 返回的不是一个函数,而是一个特殊的 Reference Type 的值。
Reference Type 是 ECMA 中的一个“规范类型”。我们不能直接使用它,但它被用在 JavaScript 语言内部。
Reference Type 的值是一个三个值的组合 (base, name, strict),其中:
base是对象。name是属性名。strict在use strict模式下为 true。
对属性user.hi访问的结果不是一个函数,而是一个 Reference Type 的值。对于user.hi,在严格模式下是:
// Reference Type 的值
(user, "hi", true)
当 () 被在 Reference Type 上调用时,它们会接收到关于对象和对象的方法的完整信息,然后可以设置正确的 this(在此处 =user)。
Reference Type 是一个特殊的“中间人”内部类型,目的是从 . 传递信息给 () 调用。
任何例如赋值 hi = user.hi 等其他的操作,都会将 Reference Type 作为一个整体丢弃掉,而会取 user.hi(一个函数)的值并继续传递。所以任何后续操作都“丢失”了 this。
因此,this 的值仅在函数直接被通过点符号 obj.method() 或方括号 obj['method']() 语法(此处它们作用相同)调用时才被正确传递。还有很多种解决这个问题的方式,例如 func.bind()。
BigInt
最近新增的特性
这是一个最近添加到 JavaScript 的特性。 你能在 https://caniuse.com/#feat=bigint 找到当前支持状态。
BigInt 是一种特殊的数字类型,它提供了对任意长度整数的支持。
创建 bigint 的方式有两种:在一个整数字面量后面加 n 或者调用 BigInt 函数,该函数从字符串、数字等中生成 bigint。
const bigint = 1234567890123456789012345678901234567890n;
const sameBigint = BigInt("1234567890123456789012345678901234567890");
const bigintFromNumber = BigInt(10); // 与 10n 相同
数学运算符
BigInt 大多数情况下可以像常规数字类型一样使用,例如:
alert(1n + 2n); // 3
alert(5n / 2n); // 2
请注意:除法 5/2 的结果向零进行舍入,舍入后得到的结果没有了小数部分。对 bigint 的所有操作,返回的结果也是 bigint。
我们不可以把 bigint 和常规数字类型混合使用:
alert(1n + 2); // Error: Cannot mix BigInt and other types
如果有需要,我们应该显式地转换它们:使用 BigInt() 或者 Number(),像这样:
let bigint = 1n;
let number = 2;
// 将 number 转换为 bigint
alert(bigint + BigInt(number)); // 3
// 将 bigint 转换为 number
alert(Number(bigint) + number); // 3
转换操作始终是静默的,绝不会报错,但是如果 bigint 太大而数字类型无法容纳,则会截断多余的位,因此我们应该谨慎进行此类转换。
BigInt 不支持一元加法
一元加法运算符+value,是大家熟知的将value转换成数字类型的方法。
为了避免混淆,在 bigint 中不支持一元加法:
let bigint = 1n;
alert( +bigint ); // error
所以我们应该用
Number()来将一个 bigint 转换成一个数字类型。
比较运算符
比较运算符,例如 < 和 >,使用它们来对 bigint 和 number 类型的数字进行比较没有问题:
alert( 2n > 1n ); // true
alert( 2n > 1 ); // true
但是请注意,由于 number 和 bigint 属于不同类型,它们可能在进行 == 比较时相等,但在进行 ===(严格相等)比较时不相等:
alert( 1 == 1n ); // true
alert( 1 === 1n ); // false
布尔运算
当在 if 或其他布尔运算中时,bigint 的行为类似于 number。
例如,在 if 中,bigint 0n 为假,其他值为 true:
if (0n) {
// 永远不会执行
}
布尔运算符,例如 ||,&& 和其他运算符,处理 bigint 的方式也类似于 number:
alert( 1n || 2 ); // 1(1n 被认为是真)
alert( 0n || 2 ); // 2(0n 被认为是假)
Polyfill
Polyfilling bigint 比较棘手。原因是许多 JavaScript 运算符,比如 + 和 - 等,在对待 bigint 的行为上与常规 number 相比有所不同。
例如,bigint 的除法总是返回 bigint(如果需要,会进行舍入)。
想要模拟这种行为,polyfill 需要分析代码,并用其函数替换所有此类运算符。但是这样做很麻烦,并且会耗费很多性能。
所以,目前并没有一个众所周知的好用的 polyfill。
不过,JSBI 库的开发者提出了另一种解决方案。
该库使用自己的方法实现了大的数字。我们可以使用它们替代原生的 bigint:
| 运算 | 原生 BigInt |
JSBI |
|---|---|---|
| 从 Number 创建 | a = BigInt(789) |
a = JSBI.BigInt(789) |
| 加法 | c = a + b |
c = JSBI.add(a, b) |
| 减法 | c = a - b |
c = JSBI.subtract(a, b) |
| … | … | … |
……然后,对于那些支持 bigint 的浏览器,可以使用 polyfill(Babel 插件)将 JSBI 调用转换为原生的 bigint。
换句话说,这个方法建议我们在写代码时使用 JSBI 替代原生的 bigint。但是 JSBI 在内部像使用 bigint 一样使用 number,并最大程度按照规范进行模拟,所以代码已经是准备好转换成 bigint 的了(bigint-ready)。
对于不支持 bigint 的引擎,我们可以“按原样”使用此类 JSBI 代码,对于那些支持 bigint 的引擎 —— polyfill 会将调用转换为原生的 bigint。
MORE
Unicode 字符串内幕
进阶知识
本节将更深入地介绍字符串的内部原理。如果你打算处理表情符号(emoji)、罕见的数学或象形文字字符,或其他罕见字符,这些知识将对你很有用。
正如我们所知,JavaScript 的字符串是基于 Unicode 的:每个字符由 1-4 个字节的字节序列表示。
JavaScript 允许我们通过下述三种表示方式之一将一个字符以其十六进制 Unicode 编码的方式插入到字符串中:
\xXX
XX必须是介于00与FF之间的两位十六进制数,\xXX表示 Unicode 编码为XX的字符。
因为\xXX符号只支持两位十六进制数,所以它只能用于前 256 个 Unicode 字符。
这前 256 个字符包括拉丁字母、最基本的语法字符和其他一些字符。例如,"\x7A"表示"z"(Unicode 编码为U+007A)。
alert( "\x7A" ); // z
alert( "\xA9" ); // © (版权符号)
\uXXXXXXXX必须是 4 位十六进制数,值介于0000和FFFF之间。此时,\uXXXX便表示 Unicode 编码为XXXX的字符。
Unicode 值大于U+FFFF的字符也可以用这种方法来表示,但在这种情况下,我们要用到代理对(我们将在本章的后面讨论它)。
alert( "\u00A9" ); // ©, 等同于 \xA9,只是使用了四位十六进制数表示而已
alert( "\u044F" ); // я(西里尔字母)
alert( "\u2191" ); // ↑(上箭头符号)
\u{X…XXXXXX}
X…XXXXXX必须是介于0和10FFFF(Unicode 定义的最高码位)之间的 1 到 6 个字节的十六进制值。这种表示方式让我们能够轻松地表示所有现有的 Unicode 字符。
alert( "\u{20331}" ); // 佫, 一个不常见的中文字符(长 Unicode)
alert( "\u{1F60D}" ); // 😍, 一个微笑符号(另一个长 Unicode)
代理对
所有常用字符都有对应的 2 字节长度的编码(4 位十六进制数)。大多数欧洲语言的字母、数字、以及基本统一的 CJK 表意文字集(CJK —— 来自中文、日文和韩文书写系统)中的字母,均有对应的 2 字节长度的 Unicode 编码。
最初,JavaScript 是基于 UTF-16 编码的,只允许每个字符占 2 个字节长度。但 2 个字节只允许 65536 种组合,这对于表示 Unicode 里每个可能符的号来说,是不够的。
因此,需要使用超过 2 个字节长度来表示的稀有符号,我们则使用一对 2 字节长度的字符编码,它被称为“代理对”(surrogate pair)。
这种做也有副作用 —— 这些符号的长度为 2:
alert( '𝒳'.length ); // 2, 大写的数学符号 X
alert( '😂'.length ); // 2, 笑哭的表情
alert( '𩷶'.length ); // 2, 一个少见的中文字符
这是因为在 JavaScript 被创造出来的时候,代理对这个概念并不存在,因此语言并没有正确处理它们!
虽然上面的每个字符串都只有一个字符,但其 length 属性显示其长度为 2。
如何获取这些符号,也是一个棘手的问题:因为编程语言的大部分功能都将代理对当作两个字符对待。
举个例子,我们可以在输出中看到两个奇怪的字符:
alert( '𝒳'[0] ); // 显示出了一个奇怪的符号...
alert( '𝒳'[1] ); // ...代理对的片段
代理对的片段失去彼此就没有意义。所以上面示例中 alert() 打印出的内容其实就是没有任何意义的垃圾信息。
从技术上讲,可以通过代理对的编码来检测代理对:如果一个字符的编码在 0xd800..0xdbff 这个范围中,那么它就是代理对的前一个部分。下一个字符(第二部分)的编码必须在 0xdc00..0xdfff 范围中。这两个范围中的编码是规范中专为代理对预留的。
基于此,JavaScript 新增了 String.fromCodePoint 和 str.codePointAt 这两个方法来处理代理对。
它们本质上与 String.fromCharCode 和 str.charCodeAt 相同,但它们可以正确地处理代理对。
在这里可以看出它们的区别:
// charCodeAt 不会考虑代理对,所以返回了 𝒳 前半部分的编码:
alert( '𝒳'.charCodeAt(0).toString(16) ); // d835
// codePointAt 可以正确处理代理对
alert( '𝒳'.codePointAt(0).toString(16) ); // 1d4b3,读取到了完整的代理对
也就是说,如果我们从 𝒳 的位置 1 开始获取对应的编码(这么做是不对的),那么这两个方法都只会返回此代理对的后半部分:
alert( '𝒳'.charCodeAt(1).toString(16) ); // dcb3
alert( '𝒳'.codePointAt(1).toString(16) ); // dcb3
// 无意义的代理对后半部分
你稍后可以在 Iterable object(可迭代对象) 一章中找到更多处理代理对的方式。可能也有专门处理代理对的库,但没有足够流行到可以让我们在这里推荐的库。
注意:在任意点拆分字符串是很危险的
我们不能随意在任意位置对字符串进行拆分,例如通过str.slice(0, 4)获取一个字符串,并期待它是一个有效的字符串:
alert( 'hi 😂'.slice(0, 4) ); // hi [?]
在这里,我们看到一个没有意义的垃圾字符被打印了出来(笑哭表情代理对的前半部分)。
如果你期望可靠地使用代理对,请注意这一点。这可能并不是什么大问题,但至少你应该知道发生了什么。
变音符号和规范化
很多语言都有由基础字符及其上方/下方的标记所组成的符号。
举个例子,字母 a 就是这些字符 àáâäãåā 的基础字符。
大多数常见的“复合”字符在 Unicode 表中都有自己的编码。但不是所有这些字符都有自己的编码,因为可能的组合形式太多了。
为了支持任意的组合,Unicode 标准允许我们使用多个 Unicode 字符:基础字符后跟着一个或多个“装饰”它的“标记”字符。
例如,如果我们在 S 后附加上特殊的“上方的点”字符(编码为 \u0307),则显示为 Ṡ。
alert( 'S\u0307' ); // Ṡ
如果我们需要在字母上方(或下方)添加一个额外的标记 —— 很简单,只需添加必要的标记字符即可。
例如,如果我们继续在后面附加一个“下方的点”符号(编码 \u0323),那么我们将得到一个“上下都有一个点符号的 S”:Ṩ。
就像这样:
alert( 'S\u0307\u0323' ); // Ṩ
这提供了极大的灵活性,但也带来了一个有趣的问题:两个字符可能在视觉上看起来相同,但却使用的是不同的 Unicode 组合。
举个例子:
let s1 = 'S\u0307\u0323'; // Ṩ, S + 上方点符号 + 下方点符号
let s2 = 'S\u0323\u0307'; // Ṩ, S + 下方点符号 + 上方点符号
alert( `s1: ${s1}, s2: ${s2}` );
alert( s1 == s2 ); // 尽管这两个字符在我们看来是相通的,但结果却是 false
“Unicode 规范化”算法可以解决这个问题,该算法将每个字符串转换为单一的“规范的”形式。
可以借助 str.normalize() 实现这一点。
alert( "S\u0307\u0323".normalize() == "S\u0323\u0307".normalize() ); // true
有意思的是,在我们这个例子中,normalize() 将 3 个字符的序列合并为了一个字符:\u1e68(带有上下两个点的 S)。
alert( "S\u0307\u0323".normalize().length ); // 1
alert( "S\u0307\u0323".normalize() == "\u1e68" ); // true
但实际并非总是如此。出现这种情况的原因是符号 Ṩ 是“足够常见的”,所以 Unicode 创建者将其囊括在了 Unicode 主表中,并为其提供了对应的编码。
如果你想了解关于 Unicode 规范化规则和变体的更多信息,可以参阅 Unicode 标准的附录中的内容:Unicode 规范化形式。但就实用而言,本节中的信息就已经足够了。