ArrayBuffer 二进制文件
在 Web 开发中,当我们处理文件时(创建,上传,下载),经常会遇到二进制数据。另一个典型的应用场景是图像处理。
这些都可以通过 JavaScript 进行处理,而且二进制操作性能更高。
不过,在 JavaScript 中有很多种二进制数据格式,会有点容易混淆。仅举几个例子:
ArrayBuffer,Uint8Array,DataView,Blob,File及其他。
与其他语言相比,JavaScript 中的二进制数据是以非标准方式实现的。但是,当我们理清楚以后,一切就会变得相当简单了。
基本的二进制对象是ArrayBuffer—— 对固定长度的连续内存空间的引用。
我们这样创建它:
let buffer = new ArrayBuffer(16); // 创建一个长度为 16 的 buffer
alert(buffer.byteLength); // 16
它会分配一个 16 字节的连续内存空间,并用 0 进行预填充。
ArrayBuffer不是某种东西的数组
让我们先澄清一个可能的误区。ArrayBuffer与Array没有任何共同之处:
- 它的长度是固定的,我们无法增加或减少它的长度。
- 它正好占用了内存中的那么多空间。
- 要访问单个字节,需要另一个“视图”对象,而不是
buffer[index]。
ArrayBuffer 是一个内存区域。它里面存储了什么?无从判断。只是一个原始的字节序列。
如要操作 ArrayBuffer,我们需要使用“视图”对象。
视图对象本身并不存储任何东西。它是一副“眼镜”,透过它来解释存储在 ArrayBuffer 中的字节。
例如:
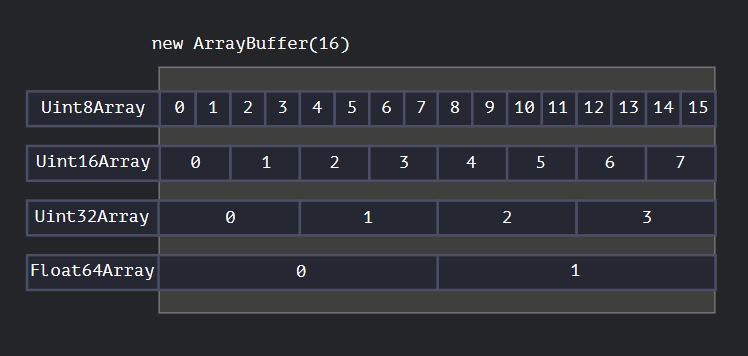
Uint8Array—— 将ArrayBuffer中的每个字节视为 0 到 255 之间的单个数字(每个字节是 8 位,因此只能容纳那么多)。这称为 “8 位无符号整数”。Uint16Array—— 将每 2 个字节视为一个 0 到 65535 之间的整数。这称为 “16 位无符号整数”。Uint32Array—— 将每 4 个字节视为一个 0 到 4294967295 之间的整数。这称为 “32 位无符号整数”。Float64Array—— 将每 8 个字节视为一个5.0x10-324到1.8x10308之间的浮点数。
因此,一个 16 字节ArrayBuffer中的二进制数据可以解释为 16 个“小数字”,或 8 个更大的数字(每个数字 2 个字节),或 4 个更大的数字(每个数字 4 个字节),或 2 个高精度的浮点数(每个数字 8 个字节)。

ArrayBuffer是核心对象,是所有的基础,是原始的二进制数据。
但是,如果我们要写入值或遍历它,基本上几乎所有操作 —— 我们必须使用视图(view),例如:
let buffer = new ArrayBuffer(16); // 创建一个长度为 16 的 buffer
let view = new Uint32Array(buffer); // 将 buffer 视为一个 32 位整数的序列
alert(Uint32Array.BYTES_PER_ELEMENT); // 每个整数 4 个字节
alert(view.length); // 4,它存储了 4 个整数
alert(view.byteLength); // 16,字节中的大小
// 让我们写入一个值
view[0] = 123456;
// 遍历值
for(let num of view) {
alert(num); // 123456,然后 0,0,0(一共 4 个值)
}
TypedArray
所有这些视图(Uint8Array,Uint32Array 等)的通用术语是 TypedArray。它们共享同一方法和属性集。
请注意,没有名为 TypedArray 的构造器,它只是表示 ArrayBuffer 上的视图之一的通用总称术语:Int8Array,Uint8Array 及其他,很快就会有完整列表。
当你看到 new TypedArray 之类的内容时,它表示 new Int8Array、new Uint8Array 及其他中之一。
类型化数组的行为类似于常规数组:具有索引,并且是可迭代的。
一个类型化数组的构造器(无论是 Int8Array 或 Float64Array,都无关紧要),其行为各不相同,并且取决于参数类型。
参数有 5 种变体:
new TypedArray(buffer, [byteOffset], [length]);
new TypedArray(object);
new TypedArray(typedArray);
new TypedArray(length);
new TypedArray();
- 如果给定的是
ArrayBuffer参数,则会在其上创建视图。我们已经用过该语法了。
可选,我们可以给定起始位置byteOffset(默认为 0)以及length(默认至 buffer 的末尾),这样视图将仅涵盖buffer的一部分。 - 如果给定的是
Array,或任何类数组对象,则会创建一个相同长度的类型化数组,并复制其内容。
我们可以使用它来预填充数组的数据:
let arr = new Uint8Array([0, 1, 2, 3]);
alert( arr.length ); // 4,创建了相同长度的二进制数组
alert( arr[1] ); // 1,用给定值填充了 4 个字节(无符号 8 位整数)
- 如果给定的是另一个
TypedArray,也是如此:创建一个相同长度的类型化数组,并复制其内容。如果需要的话,数据在此过程中会被转换为新的类型。
let arr16 = new Uint16Array([1, 1000]);
let arr8 = new Uint8Array(arr16);
alert( arr8[0] ); // 1
alert( arr8[1] ); // 232,试图复制 1000,但无法将 1000 放进 8 位字节中(详述见下文)。
- 对于数字参数
length—— 创建类型化数组以包含这么多元素。它的字节长度将是length乘以单个TypedArray.BYTES_PER_ELEMENT中的字节数: - 不带参数的情况下,创建长度为零的类型化数组。
我们可以直接创建一个TypedArray,而无需提及ArrayBuffer。但是,视图离不开底层的ArrayBuffer,因此,除第一种情况(已提供ArrayBuffer)外,其他所有情况都会自动创建ArrayBuffer。
如要访问底层的ArrayBuffer,那么在TypedArray中有如下的属性:
arr.buffer—— 引用ArrayBuffer。arr.byteLength——ArrayBuffer的长度。
因此,我们总是可以从一个视图转到另一个视图:
let arr8 = new Uint8Array([0, 1, 2, 3]);
// 同一数据的另一个视图
let arr16 = new Uint16Array(arr8.buffer);
下面是类型化数组的列表:
Uint8Array,Uint16Array,Uint32Array—— 用于 8、16 和 32 位的整数。Uint8ClampedArray—— 用于 8 位整数,在赋值时便“固定“其值(见下文)。
Int8Array,Int16Array,Int32Array—— 用于有符号整数(可以为负数)。Float32Array,Float64Array—— 用于 32 位和 64 位的有符号浮点数。
没有
int8或类似的单值类型
请注意,尽管有类似Int8Array这样的名称,但 JavaScript 中并没有像int,或int8这样的单值类型。
这是合乎逻辑的,因为Int8Array不是这些单值的数组,而是ArrayBuffer上的视图。
越界行为
如果我们尝试将越界值写入类型化数组会出现什么情况?不会报错。但是多余的位被切除。
例如,我们尝试将 256 放入 Uint8Array。256 的二进制格式是 100000000(9 位),但 Uint8Array 每个值只有 8 位,因此可用范围为 0 到 255。
对于更大的数字,仅存储最右边的(低位有效)8 位,其余部分被切除:
因此结果是 0。
257 的二进制格式是 100000001(9 位),最右边的 8 位会被存储,因此数组中会有 1:
换句话说,该数字对 2^8 取模的结果被保存了下来。
Uint8ClampedArray 在这方面比较特殊,它的表现不太一样。对于大于 255 的任何数字,它将保存为 255,对于任何负数,它将保存为 0。此行为对于图像处理很有用。
TypedArray 方法
TypedArray 具有常规的 Array 方法,但有个明显的例外。
我们可以遍历(iterate),map,slice,find 和 reduce 等。
但有几件事我们做不了:
- 没有
splice—— 我们无法“删除”一个值,因为类型化数组是缓冲区(buffer)上的视图,并且缓冲区(buffer)是固定的、连续的内存区域。我们所能做的就是分配一个零值。 - 无
concat方法。
还有两种其他方法: arr.set(fromArr, [offset])从offset(默认为 0)开始,将fromArr中的所有元素复制到arr。arr.subarray([begin, end])创建一个从begin到end(不包括)相同类型的新视图。这类似于slice方法(同样也支持),但不复制任何内容 —— 只是创建一个新视图,以对给定片段的数据进行操作。
有了这些方法,我们可以复制、混合类型化数组,从现有数组创建新数组等。
DataView
DataView 是在 ArrayBuffer 上的一种特殊的超灵活“未类型化”视图。它允许以任何格式访问任何偏移量(offset)的数据。
- 对于类型化的数组,构造器决定了其格式。整个数组应该是统一的。第 i 个数字是
arr[i]。 - 通过
DataView,我们可以使用.getUint8(i)或.getUint16(i)之类的方法访问数据。我们在调用方法时选择格式,而不是在构造的时候。
语法:
new DataView(buffer, [byteOffset], [byteLength])
buffer—— 底层的ArrayBuffer。与类型化数组不同,DataView不会自行创建缓冲区(buffer)。我们需要事先准备好。byteOffset—— 视图的起始字节位置(默认为 0)。byteLength—— 视图的字节长度(默认至buffer的末尾)。
例如,这里我们从同一个 buffer 中提取不同格式的数字:
// 4 个字节的二进制数组,每个都是最大值 255
let buffer = new Uint8Array([255, 255, 255, 255]).buffer;
let dataView = new DataView(buffer);
// 在偏移量为 0 处获取 8 位数字
alert( dataView.getUint8(0) ); // 255
// 现在在偏移量为 0 处获取 16 位数字,它由 2 个字节组成,一起解析为 65535
alert( dataView.getUint16(0) ); // 65535(最大的 16 位无符号整数)
// 在偏移量为 0 处获取 32 位数字
alert( dataView.getUint32(0) ); // 4294967295(最大的 32 位无符号整数)
dataView.setUint32(0, 0); // 将 4 个字节的数字设为 0,即将所有字节都设为 0
当我们将混合格式的数据存储在同一缓冲区(buffer)中时,DataView 非常有用。例如,当我们存储一个成对序列(16 位整数,32 位浮点数)时,用 DataView 可以轻松访问它们。
TextDecoder 和 TextEncoder
如果二进制数据实际上是一个字符串怎么办?例如,我们收到了一个包含文本数据的文件。
内建的 TextDecoder 对象在给定缓冲区(buffer)和编码格式(encoding)的情况下,允许将值读取为实际的 JavaScript 字符串。
首先我们需要创建:
let decoder = new TextDecoder(, [options]);
label—— 编码格式,默认为utf-8,但同时也支持big5,windows-1251等许多其他编码格式。options—— 可选对象:fatal—— 布尔值,如果为true则为无效(不可解码)字符抛出异常,否则(默认)用字符\uFFFD替换无效字符。ignoreBOM—— 布尔值,如果为true则忽略 BOM(可选的字节顺序 Unicode 标记),很少需要使用。
……然后解码:
let str = decoder.decode([input], [options]);
input—— 要被解码的BufferSource。options—— 可选对象:stream—— 对于解码流,为 true,则将传入的数据块(chunk)作为参数重复调用decoder。在这种情况下,多字节的字符可能偶尔会在块与块之间被分割。这个选项告诉TextDecoder记住“未完成”的字符,并在下一个数据块来的时候进行解码。
例如:
let uint8Array = new Uint8Array([72, 101, 108, 108, 111]);
alert( new TextDecoder().decode(uint8Array) ); // Hello
let uint8Array = new Uint8Array([228, 189, 160, 229, 165, 189]);
alert( new TextDecoder().decode(uint8Array) ); // 你好
我们可以通过为其创建子数组视图来解码部分缓冲区:
let uint8Array = new Uint8Array([0, 72, 101, 108, 108, 111, 0]);
// 该字符串位于中间
// 在不复制任何内容的前提下,创建一个新的视图
let binaryString = uint8Array.subarray(1, -1);
alert( new TextDecoder().decode(binaryString) ); // Hello
TextEncoder
TextEncoder 做相反的事情 —— 将字符串转换为字节。
语法为:
let encoder = new TextEncoder();
只支持 utf-8 编码。
它有两种方法:
encode(str)—— 从字符串返回Uint8Array。encodeInto(str, destination)—— 将str编码到destination中,该目标必须为Uint8Array。
let encoder = new TextEncoder();
let uint8Array = encoder.encode("Hello");
alert(uint8Array); // 72,101,108,108,111
Blob
arrayBuffer 和视图(view)都是 ECMA 标准的一部分,是 JavaScript 的一部分。
在浏览器中,还有其他更高级的对象,特别是 Blob,在 File API 中有相关描述。
Blob 由一个可选的字符串 type(通常是 MIME 类型)和 blobParts 组成 —— 一系列其他 Blob 对象,字符串和 BufferSource。

构造函数的语法为:
new Blob(blobParts, options);
blobParts是Blob/BufferSource/String类型的值的数组。options可选对象:type——Blob类型,通常是 MIME 类型,例如image/png,endings—— 是否转换换行符,使Blob对应于当前操作系统的换行符(\r\n或\n)。默认为"transparent"(啥也不做),不过也可以是"native"(转换)。
例如:
// 从字符串创建 Blob
let blob = new Blob(["<html>…</html>"], {type: 'text/html'});
// 请注意:第一个参数必须是一个数组 [...]
// 从类型化数组(typed array)和字符串创建 Blob
let hello = new Uint8Array([72, 101, 108, 108, 111]); // 二进制格式的 "hello"
let blob = new Blob([hello, ' ', 'world'], {type: 'text/plain'});
我们可以用 slice 方法来提取 Blob 片段:
blob.slice([byteStart], [byteEnd], [contentType]);
byteStart—— 起始字节,默认为 0。byteEnd—— 最后一个字节(不包括,默认为最后)。contentType—— 新 blob 的type,默认与源 blob 相同。
参数值类似于array.slice,也允许是负数。
Blob对象是不可改变的
我们无法直接在Blob中更改数据,但我们可以通过slice获得Blob的多个部分,从这些部分创建新的Blob对象,将它们组成新的Blob,等。
这种行为类似于 JavaScript 字符串:我们无法更改字符串中的字符,但可以生成一个新的改动过的字符串。
Blob 用作 URL
Blob 可以很容易用作 <a>、<img> 或其他标签的 URL,来显示它们的内容。
多亏了 type,让我们也可以下载/上传 Blob 对象,而在网络请求中,type 自然地变成了 Content-Type。
让我们从一个简单的例子开始。通过点击链接,你可以下载一个具有动态生成的内容为 hello world 的 Blob 的文件:
<!-- download 特性(attribute)强制浏览器下载而不是导航 -->
<a download="hello.txt" href='#' id="link">Download</a>
<script>
let blob = new Blob(["Hello, world!"], {type: 'text/plain'});
link.href = URL.createObjectURL(blob);
</script>
我们也可以在 Javascript 中动态创建一个链接,通过 link.click() 模拟一个点击,然后便自动下载了。
下面是类似的代码,此代码可以让用户无需任何 HTML 即可下载动态生成的 Blob(译注:也就是通过代码模拟用户点击,从而自动下载):
let link = document.createElement('a');
link.download = 'hello.txt';
let blob = new Blob(['Hello, world!'], {type: 'text/plain'});
link.href = URL.createObjectURL(blob);
link.click();
URL.revokeObjectURL(link.href);
URL.createObjectURL 取一个 Blob,并为其创建一个唯一的 URL,形式为 blob:<origin>/<uuid>。
也就是 link.href 的值的样子:
blob:https://javascript.info/1e67e00e-860d-40a5-89ae-6ab0cbee6273
浏览器内部为每个通过 URL.createObjectURL 生成的 URL 存储了一个 URL → Blob 映射。因此,此类 URL 很短,但可以访问 Blob。
生成的 URL(即其链接)仅在当前文档打开的状态下才有效。它允许引用 <img>、<a> 中的 Blob,以及基本上任何其他期望 URL 的对象。
不过它有个副作用。虽然这里有 Blob 的映射,但 Blob 本身只保存在内存中的。浏览器无法释放它。
在文档退出时(unload),该映射会被自动清除,因此 Blob 也相应被释放了。但是,如果应用程序寿命很长,那这个释放就不会很快发生。
因此,如果我们创建一个 URL,那么即使我们不再需要该 Blob 了,它也会被挂在内存中。
URL.revokeObjectURL(url) 从内部映射中移除引用,因此允许 Blob 被删除(如果没有其他引用的话),并释放内存。
在上面最后一个示例中,我们打算仅使用一次 Blob,来进行即时下载,因此我们立即调用 URL.revokeObjectURL(link.href)。
而在前一个带有可点击的 HTML 链接的示例中,我们不调用 URL.revokeObjectURL(link.href),因为那样会使 Blob URL 无效。在调用该方法后,由于映射被删除了,因此该 URL 也就不再起作用了。
Blob 转换为 base64
URL.createObjectURL 的一个替代方法是,将 Blob 转换为 base64-编码的字符串。
这种编码将二进制数据表示为一个由 0 到 64 的 ASCII 码组成的字符串,非常安全且“可读“。更重要的是 —— 我们可以在 “data-url” 中使用此编码。
“data-url” 的形式为 data:[<mediatype>][;base64],<data>。我们可以在任何地方使用这种 url,和使用“常规” url 一样。
例如,这是一个笑脸:
<img src="data:image/png;base64,R0lGODlhDAAMAKIFAF5LAP/zxAAAANyuAP/gaP///wAAAAAAACH5BAEAAAUALAAAAAAMAAwAAAMlWLPcGjDKFYi9lxKBOaGcF35DhWHamZUW0K4mAbiwWtuf0uxFAgA7">
浏览器将解码该字符串,并显示图像:<img src="data:image/png;base64,R0lGODlhDAAMAKIFAF5LAP/zxAAAANyuAP/gaP///wAAAAAAACH5BAEAAAUALAAAAAAMAAwAAAMlWLPcGjDKFYi9lxKBOaGcF35DhWHamZUW0K4mAbiwWtuf0uxFAgA7">我们使用内建的 FileReader 对象来将 Blob 转换为 base64。它可以将 Blob 中的数据读取为多种格式。在下一章 我们将更深入地介绍它。
下面是下载 Blob 的示例,这次是通过 base-64:
let link = document.createElement('a');
link.download = 'hello.txt';
let blob = new Blob(['Hello, world!'], {type: 'text/plain'});
let reader = new FileReader();
reader.readAsDataURL(blob); // 将 Blob 转换为 base64 并调用 onload
reader.onload = function() {
link.href = reader.result; // data url
link.click();
};
这两种从 Blob 创建 URL 的方法都可以用。但通常 URL.createObjectURL(blob) 更简单快捷。

Image 转换为 blob
我们可以创建一个图像(image)的、图像的一部分、或者甚至创建一个页面截图的 Blob。这样方便将其上传至其他地方。
图像操作是通过 <canvas> 元素来实现的:
- 使用 canvas.drawImage 在 canvas 上绘制图像(或图像的一部分)。
- 调用 canvas 方法 .toBlob(callback, format, quality) 创建一个
Blob,并在创建完成后使用其运行callback。
在下面这个示例中,图像只是被复制了,不过我们可以在创建 blob 之前,从中裁剪图像,或者在 canvas 上对其进行转换:
// 获取任何图像
let img = document.querySelector('img');
// 生成同尺寸的 <canvas>
let canvas = document.createElement('canvas');
canvas.width = img.clientWidth;
canvas.height = img.clientHeight;
let context = canvas.getContext('2d');
// 向其中复制图像(此方法允许剪裁图像)
context.drawImage(img, 0, 0);
// 我们 context.rotate(),并在 canvas 上做很多其他事情
// toBlob 是异步操作,结束后会调用 callback
canvas.toBlob(function(blob) {
// blob 创建完成,下载它
let link = document.createElement('a');
link.download = 'example.png';
link.href = URL.createObjectURL(blob);
link.click();
// 删除内部 blob 引用,这样浏览器可以从内存中将其清除
URL.revokeObjectURL(link.href);
}, 'image/png');
如果我们更喜欢 async/await 而不是 callback:
let blob = await new Promise(resolve => canvasElem.toBlob(resolve, 'image/png'));
对于页面截屏,我们可以使用诸如 https://github.com/niklasvh/html2canvas 之类的库。它所做的只是扫一遍浏览器页面,并将其绘制在 <canvas> 上。然后,我们就可以像上面一样获取一个它的 Blob。
Blob 转换为 ArrayBuffer
Blob 构造器允许从几乎任何东西创建 blob,包括任何 BufferSource。
但是,如果我们需要执行低级别的处理时,我们可以从 blob.arrayBuffer() 中获取最低级别的 ArrayBuffer:
// 从 blob 获取 arrayBuffer
const bufferPromise = await blob.arrayBuffer();
// 或
blob.arrayBuffer().then(buffer => /* 处理 ArrayBuffer */);
Blob 转换为 Stream
当我们读取和写入超过 2 GB 的 blob 时,将其转换为 arrayBuffer 的使用对我们来说会更加占用内存。这种情况下,我们可以直接将 blob 转换为 stream 进行处理。
stream 是一种特殊的对象,我们可以从它那里逐部分地读取(或写入)。这块的知识点不在本文的范围之内,但这里有一个例子,你可以在 https://developer.mozilla.org/en-US/docs/Web/API/Streams_API 了解更多相关内容。对于适合逐段处理的数据,使用 stream 是很方便的。
Blob 接口里的 stream() 方法返回一个 ReadableStream,在被读取时可以返回 Blob 中包含的数据。
如下所示:
// 从 blob 获取可读流(readableStream)
const readableStream = blob.stream();
const stream = readableStream.getReader();
while (true) {
// 对于每次迭代:value 是下一个 blob 数据片段
let { done, value } = await stream.read();
if (done) {
// 读取完毕,stream 里已经没有数据了
console.log('all blob processed.');
break;
}
// 对刚从 blob 中读取的数据片段做一些处理
console.log(value);
}
File 和 FileReader
File 对象继承自 Blob,并扩展了与文件系统相关的功能。
有两种方式可以获取它。
第一种,与 Blob 类似,有一个构造器:
new File(fileParts, fileName, [options])
fileParts—— Blob/BufferSource/String 类型值的数组。fileName—— 文件名字符串。options—— 可选对象:lastModified—— 最后一次修改的时间戳(整数日期)。
第二种,更常见的是,我们从<input type="file">或拖放或其他浏览器接口来获取文件。在这种情况下,file 将从操作系统(OS)获得 this 信息。
由于File是继承自Blob的,所以File对象具有相同的属性,附加:
name—— 文件名,lastModified—— 最后一次修改的时间戳。
这就是我们从<input type="file">中获取File对象的方式:
<input type="file" onchange="showFile(this)">
<script>
function showFile(input) {
let file = input.files[0];
alert(`File name: ${file.name}`); // 例如 my.png
alert(`Last modified: ${file.lastModified}`); // 例如 1552830408824
}
</script>
请注意:
输入(input)可以选择多个文件,因此input.files是一个类数组对象。这里我们只有一个文件,所以我们只取input.files[0]。
FileReader
FileReader 是一个对象,其唯一目的是从 Blob(因此也从 File)对象中读取数据。
它使用事件来传递数据,因为从磁盘读取数据可能比较费时间。
构造函数:
let reader = new FileReader(); // 没有参数
主要方法:
readAsArrayBuffer(blob)—— 将数据读取为二进制格式的ArrayBuffer。readAsText(blob, [encoding])—— 将数据读取为给定编码(默认为utf-8编码)的文本字符串。readAsDataURL(blob)—— 读取二进制数据,并将其编码为 base64 的 data url。abort()—— 取消操作。
read*方法的选择,取决于我们喜欢哪种格式,以及如何使用数据。readAsArrayBuffer—— 用于二进制文件,执行低级别的二进制操作。对于诸如切片(slicing)之类的高级别的操作,File是继承自Blob的,所以我们可以直接调用它们,而无需读取。readAsText—— 用于文本文件,当我们想要获取字符串时。readAsDataURL—— 当我们想在src中使用此数据,并将其用于img或其他标签时。正如我们在 Blob 一章中所讲的,还有一种用于此的读取文件的替代方案:URL.createObjectURL(file)。
读取过程中,有以下事件:loadstart—— 开始加载。progress—— 在读取过程中出现。load—— 读取完成,没有 error。abort—— 调用了abort()。error—— 出现 error。loadend—— 读取完成,无论成功还是失败。
读取完成后,我们可以通过以下方式访问读取结果:reader.result是结果(如果成功)reader.error是 error(如果失败)。
使用最广泛的事件无疑是load和error。
这是一个读取文件的示例:
<input type="file" onchange="readFile(this)">
<script>
function readFile(input) {
let file = input.files[0];
let reader = new FileReader();
reader.readAsText(file);
reader.onload = function() {
console.log(reader.result);
};
reader.onerror = function() {
console.log(reader.error);
};
}
</script>
FileReader用于 blob
正如我们在 Blob 一章中所提到的,FileReader不仅可读取文件,还可读取任何 blob。
我们可以使用它将 blob 转换为其他格式:
readAsArrayBuffer(blob)—— 转换为ArrayBuffer,readAsText(blob, [encoding])—— 转换为字符串(TextDecoder的一个替代方案),readAsDataURL(blob)—— 转换为 base64 的 data url。
在 Web Workers 中可以使用
FileReaderSync
对于 Web Worker,还有一种同步的FileReader变体,称为 FileReaderSync。
它的读取方法read*不会生成事件,但是会像常规函数那样返回一个结果。
不过,这仅在 Web Worker 中可用,因为在读取文件的时候,同步调用会有延迟,而在 Web Worker 中,这种延迟并不是很重要。它不会影响页面。