浏览器环境,规格
JavaScript 语言最初是为 Web 浏览器创建的。此后,它已经演变成了一种具有多种用途和平台的语言。
平台可以是一个浏览器,一个 Web 服务器,或其他 主机(host),甚至可以是一个“智能”咖啡机,如果它能运行 JavaScript 的话。它们每个都提供了特定于平台的功能。JavaScript 规范将其称为 主机环境。
主机环境提供了自己的对象和语言核心以外的函数。Web 浏览器提供了一种控制网页的方法。Node.JS 提供了服务器端功能,等等。
下面是 JavaScript 在浏览器中运行时的鸟瞰示意图
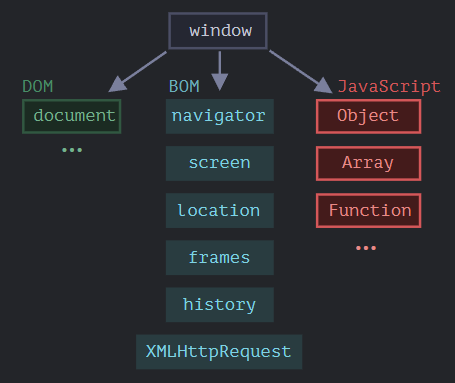
有一个叫做
window 的“根”对象。它有两个角色:
- 首先,它是 JavaScript 代码的全局对象,如 全局对象 一章所述。
- 其次,它代表“浏览器窗口”,并提供了控制它的方法。
文档对象模型 DOM
文档对象模型(Document Object Model),简称 DOM,将所有页面内容表示为可以修改的对象。
document 对象是页面的主要“入口点”。我们可以使用它来更改或创建页面上的任何内容。
// 将背景颜色修改为红色
document.body.style.background = "red";
// 在 1 秒后将其修改回来
setTimeout(() => document.body.style.background = "", 1000);
在这里,我们使用了 document.body.style,但还有很多很多其他的东西。规范中有属性和方法的详细描述:DOM Living Standard。
DOM 不仅仅用于浏览器
DOM 规范解释了文档的结构,并提供了操作文档的对象。有的非浏览器设备也使用 DOM。
例如,下载 HTML 文件并对其进行处理的服务器端脚本也可以使用 DOM。但它们可能仅支持部分规范中的内容。
用于样式的 CSSOM
另外也有一份针对 CSS 规则和样式表的、单独的规范 CSS Object Model (CSSOM),这份规范解释了如何将 CSS 表示为对象,以及如何读写这些对象。
当我们修改文档的样式规则时,CSSOM 与 DOM 是一起使用的。但实际上,很少需要 CSSOM,因为我们很少需要从 JavaScript 中修改 CSS 规则(我们通常只是添加/移除一些 CSS 类,而不是直接修改其中的 CSS 规则),但这也是可行的。
浏览器对象模型 BOM
浏览器对象模型(Browser Object Model),简称 BOM,表示由浏览器(主机环境)提供的用于处理文档(document)之外的所有内容的其他对象。
例如:
- navigator 对象提供了有关浏览器和操作系统的背景信息。navigator 有许多属性,但是最广为人知的两个属性是:
navigator.userAgent—— 关于当前浏览器,navigator.platform—— 关于平台(有助于区分 Windows/Linux/Mac 等)。 - location 对象允许我们读取当前 URL,并且可以将浏览器重定向到新的 URL。
alert(location.href); // 显示当前 URL
if (confirm("Go to Wikipedia?")) {
location.href = "https://wikipedia.org"; // 将浏览器重定向到另一个 URL
}
函数 alert/confirm/prompt 也是 BOM 的一部分:它们与文档(document)没有直接关系,但它代表了与用户通信的纯浏览器方法。
规范
BOM 是通用 HTML 规范 的一部分。
是的,你没听错。在 https://html.spec.whatwg.org 中的 HTML 规范不仅是关于“HTML 语言”(标签,特性)的,还涵盖了一堆对象、方法和浏览器特定的 DOM 扩展。这就是“广义的 HTML”。此外,某些部分也有其他的规范,它们被列在 https://spec.whatwg.org 中。
DOM 树
HTML 文档的主干是标签(tag)。
根据文档对象模型(DOM),每个 HTML 标签都是一个对象。嵌套的标签是闭合标签的“子标签(children)”。标签内的文本也是一个对象。
所有这些对象都可以通过 JavaScript 来访问,我们可以使用它们来修改页面。
例如,document.body 是表示 <body> 标签的对象。
在这,我们使用了 style.background 来修改 document.body 的背景颜色,但是还有很多其他的属性,例如:
innerHTML—— 节点的 HTML 内容。offsetWidth—— 节点宽度(以像素度量)- ……等。
很快,我们将学习更多操作 DOM 的方法,但首先我们需要了解 DOM 的结构。
DOM例子
<!DOCTYPE HTML>
<html>
<head>
<title>About elk</title>
</head>
<body>
The truth about elk.
</body>
</html>
DOM 将 HTML 表示为标签的树形结构。
<svg width="690" height="320"><g transform="translate(20,30)"><path class="link" d="M7,0L7,30L40.333333333333336,30" style="fill: none; stroke: rgb(190, 195, 199); stroke-width: 1px;"></path><path class="link" d="M7,0L7,180L40.333333333333336,180" style="fill: none; stroke: rgb(190, 195, 199); stroke-width: 1px;"></path><path class="link" d="M7,0L7,210L40.333333333333336,210" style="fill: none; stroke: rgb(190, 195, 199); stroke-width: 1px;"></path><path class="link" d="M40.333333333333336,210L40.333333333333336,240L73.66666666666667,240" style="fill: none; stroke: rgb(190, 195, 199); stroke-width: 1px;"></path><path class="link" d="M40.333333333333336,30L40.333333333333336,60L73.66666666666667,60" style="fill: none; stroke: rgb(190, 195, 199); stroke-width: 1px;"></path><path class="link" d="M40.333333333333336,30L40.333333333333336,90L73.66666666666667,90" style="fill: none; stroke: rgb(190, 195, 199); stroke-width: 1px;"></path><path class="link" d="M40.333333333333336,30L40.333333333333336,150L73.66666666666667,150" style="fill: none; stroke: rgb(190, 195, 199); stroke-width: 1px;"></path><path class="link" d="M73.66666666666667,90L73.66666666666667,120L107,120" style="fill: none; stroke: rgb(190, 195, 199); stroke-width: 1px;"></path><g class="node" transform="translate(0,0)" style="opacity: 1;"><rect y="-12.5" x="-5" rx="4" ry="4" height="25" width="280" style="fill: rgb(206, 224, 244); cursor: pointer;"></rect><text dy="4.5" dx="3.5" style="fill: black; pointer-events: none;">▾ </text><text dy="4.5" dx="16.5" style="font: 14px Consolas, "Lucida Console", Menlo, Monaco, monospace; fill: rgb(51, 51, 51); pointer-events: none;">HTML</text></g><g class="node" transform="translate(33.33333206176758,30)" style="opacity: 1;"><rect y="-12.5" x="-5" rx="4" ry="4" height="25" width="280" style="fill: rgb(206, 224, 244); cursor: pointer;"></rect><text dy="4.5" dx="3.5" style="fill: black; pointer-events: none;">▾ </text><text dy="4.5" dx="16.5" style="font: 14px Consolas, "Lucida Console", Menlo, Monaco, monospace; fill: rgb(51, 51, 51); pointer-events: none;">HEAD</text></g><g class="node" transform="translate(33.33333206176758,180)" style="opacity: 1;"><rect y="-12.5" x="-5" rx="4" ry="4" height="25" width="280" style="fill: rgb(255, 222, 153); cursor: pointer;"></rect><text dy="4.5" dx="3.5" style="fill: black; pointer-events: none;"></text><text dy="4.5" dx="5.5" style="font: 14px Consolas, "Lucida Console", Menlo, Monaco, monospace; fill: rgb(51, 51, 51); pointer-events: none;">#text ↵</text></g><g class="node" transform="translate(33.33333206176758,210)" style="opacity: 1;"><rect y="-12.5" x="-5" rx="4" ry="4" height="25" width="280" style="fill: rgb(206, 224, 244); cursor: pointer;"></rect><text dy="4.5" dx="3.5" style="fill: black; pointer-events: none;">▾ </text><text dy="4.5" dx="16.5" style="font: 14px Consolas, "Lucida Console", Menlo, Monaco, monospace; fill: rgb(51, 51, 51); pointer-events: none;">BODY</text></g><g class="node" transform="translate(66.66666412353516,240)" style="opacity: 1;"><rect y="-12.5" x="-5" rx="4" ry="4" height="25" width="280" style="fill: rgb(255, 222, 153); cursor: pointer;"></rect><text dy="4.5" dx="3.5" style="fill: black; pointer-events: none;"></text><text dy="4.5" dx="5.5" style="font: 14px Consolas, "Lucida Console", Menlo, Monaco, monospace; fill: rgb(51, 51, 51); pointer-events: none;">#text ↵␣␣The truth about elk.↵</text></g><g class="node" transform="translate(66.66666412353516,60)" style="opacity: 1;"><rect y="-12.5" x="-5" rx="4" ry="4" height="25" width="280" style="fill: rgb(255, 222, 153); cursor: pointer;"></rect><text dy="4.5" dx="3.5" style="fill: black; pointer-events: none;"></text><text dy="4.5" dx="5.5" style="font: 14px Consolas, "Lucida Console", Menlo, Monaco, monospace; fill: rgb(51, 51, 51); pointer-events: none;">#text ↵␣␣</text></g><g class="node" transform="translate(66.66666412353516,90)" style="opacity: 1;"><rect y="-12.5" x="-5" rx="4" ry="4" height="25" width="280" style="fill: rgb(206, 224, 244); cursor: pointer;"></rect><text dy="4.5" dx="3.5" style="fill: black; pointer-events: none;">▾ </text><text dy="4.5" dx="16.5" style="font: 14px Consolas, "Lucida Console", Menlo, Monaco, monospace; fill: rgb(51, 51, 51); pointer-events: none;">TITLE</text></g><g class="node" transform="translate(100,120)" style="opacity: 1;"><rect y="-12.5" x="-5" rx="4" ry="4" height="25" width="280" style="fill: rgb(255, 222, 153); cursor: pointer;"></rect><text dy="4.5" dx="3.5" style="fill: black; pointer-events: none;"></text><text dy="4.5" dx="5.5" style="font: 14px Consolas, "Lucida Console", Menlo, Monaco, monospace; fill: rgb(51, 51, 51); pointer-events: none;">#text About elk</text></g><g class="node" transform="translate(66.66666412353516,150)" style="opacity: 1;"><rect y="-12.5" x="-5" rx="4" ry="4" height="25" width="280" style="fill: rgb(255, 222, 153); cursor: pointer;"></rect><text dy="4.5" dx="3.5" style="fill: black; pointer-events: none;"></text><text dy="4.5" dx="5.5" style="font: 14px Consolas, "Lucida Console", Menlo, Monaco, monospace; fill: rgb(51, 51, 51); pointer-events: none;">#text ↵</text></g></g></svg>
每个树的节点都是一个对象。
标签被称为 元素节点(或者仅仅是元素),并形成了树状结构:<html> 在根节点,<head> 和 <body> 是其子项,等。
元素内的文本形成 文本节点,被标记为 #text。一个文本节点只包含一个字符串。它没有子项,并且总是树的叶子。
例如,<title> 标签里面有文本 "About elk"。
请注意文本节点中的特殊字符:
- 换行符:
↵(在 JavaScript 中为\n) - 空格:
␣
空格和换行符都是完全有效的字符,就像字母和数字。它们形成文本节点并成为 DOM 的一部分。所以,例如,在上面的示例中,<head>标签中的<title>标签前面包含了一些空格,并且该文本变成了一个#text节点(它只包含一个换行符和一些空格)。
只有两个顶级排除项:
- 由于历史原因,
<head>之前的空格和换行符均被忽略。 - 如果我们在
</body>之后放置一些东西,那么它会被自动移动到body内,并处于body中的最下方,因为 HTML 规范要求所有内容必须位于<body>内。所以</body>之后不能有空格。
在其他情况下,一切都很简单 —— 如果文档中有空格(就像任何字符一样),那么它们将成为 DOM 中的文本节点,而如果我们删除它们,则不会有任何空格。
字符串开头/结尾处的空格,以及只有空格的文本节点,通常会被工具隐藏
与 DOM 一起使用的浏览器工具(即将介绍)通常不会在文本的开始/结尾显示空格,并且在标签之间也不会显示空文本节点(换行符)。
开发者工具通过这种方式节省屏幕空间。
在本教程中,如果这些空格和空文本节点无关紧要时,我们在后面出现的关于 DOM 的示意图中会忽略它们。这样的空格通常不会影响文档的显示方式。
自动修正
如果浏览器遇到格式不正确的 HTML,它会在形成 DOM 时自动更正它。
例如,顶级标签总是 <html>。即使它不存在于文档中 — 它也会出现在 DOM 中,因为浏览器会创建它。对于 <body> 也是一样。
例如,如果一个 HTML 文件中只有一个单词 “Hello”,浏览器则会把它包装到 <html> 和 <body> 中,并且会添加所需的 <head>
在生成 DOM 时,浏览器会自动处理文档中的错误,关闭标签等。
表格永远有
<tbody>
表格是一个有趣的“特殊的例子”。按照 DOM 规范,它们必须具有<tbody>标签,但 HTML 文本可能会忽略它。然后浏览器在创建 DOM 时,自动地创建了<tbody>。
其他节点类型
除了元素和文本节点外,还有一些其他的节点类型。
例如,注释
在这里我们可以看到一个新的树节点类型 —— comment 节点,被标记为 #comment,它在两个文本节点之间。
我们可能会想 —— 为什么要将注释添加到 DOM 中?它不会对视觉展现产生任何影响吗。但是有一条规则 —— 如果一些内容存在于 HTML 中,那么它也必须在 DOM 树中。
HTML 中的所有内容,甚至注释,都会成为 DOM 的一部分。
甚至 HTML 开头的 <!DOCTYPE...> 指令也是一个 DOM 节点。它在 DOM 树中位于 <html> 之前。很少有人知道这一点。我们不会触及那个节点,我们甚至不会在图表中绘制它,但它确实就在那里。
表示整个文档的 document 对象,在形式上也是一个 DOM 节点。
一共有 12 种节点类型。实际上,我们通常用到的是其中的 4 种:
document—— DOM 的“入口点”。- 元素节点 —— HTML 标签,树构建块。
- 文本节点 —— 包含文本。
- 注释 —— 有时我们可以将一些信息放入其中,它不会显示,但 JS 可以从 DOM 中读取它。
try yourself
要在实际中查看 DOM 结构,请尝试 Live DOM Viewer。只需输入文档,它将立即显示为 DOM。
探索 DOM 的另一种方式是使用浏览器开发工具。实际上,这就是我们在开发中所使用的。
你可以打开这个网页 elks.html,然后打开浏览器开发工具,并切换到元素(Elements)选项卡。
你可以看到 DOM,点击元素,查看它们的细节等。
请注意,开发者工具中的 DOM 结构是经过简化的。文本节点仅以文本形式显示。并且根本没有“空白”(只有空格)的文本节点。这其实挺好,因为大多数情况下,我们只关心元素节点。
点击左上角的 按钮可以让我们使用鼠标(或其他指针设备)从网页中选择一个节点并“检查(inspect)”它(在元素选项卡中滚动到该节点)。当我们有一个巨大的 HTML 页面(和相应的巨大 DOM),并希望查看其中的一个特定元素的位置时,这很有用。
另一种方法是在网页上右键单击,然后在上下文菜单中选择“检查(Inspect)”。
在工具的右侧部分有以下子选项卡:
- Styles —— 我们可以看到按规则应用于当前元素的 CSS 规则,包括内建规则(灰色)。几乎所有内容都可以就地编辑,包括下面的方框的 dimension/margin/padding。
- Computed —— 按属性查看应用于元素的 CSS:对于每个属性,我们可以都可以看到赋予它的规则(包括 CSS 继承等)。
- Event Listeners —— 查看附加到 DOM 元素的事件侦听器(我们将在本教程的下一部分介绍它们)。
- ……等。
学习它们的最佳方式就是多点一点看一下。大多数值都是可以就地编辑的。
与控制台交互
在我们处理 DOM 时,我们可能还希望对其应用 JavaScript。例如:获取一个节点并运行一些代码来修改它,以查看结果。以下是在元素(Elements)选项卡和控制台(Console)之间切换的一些技巧。
首先:
- 在元素(Elements)选项卡中选择第一个
<li>。 - 按下 Esc —— 它将在元素(Elements)选项卡下方打开控制台(Console)。
现在最后选中的元素可以通过$0来进行操作,在之前的选择中则是$1。
我们可以对它们执行一些命令。例如,$0.style.background = 'red'使选定的列表项(list item)变成红色
这就是在控制台(Console)中获取元素(Elements)选项卡中的节点的方法。
还有一种方式。如果存在引用 DOM 节点的变量,那么我们可以在控制台(Console)中使用命令 inspect(node),来在元素(Elements)选项卡中查看它。
或者我们可以直接在控制台(Console)中输出 DOM 节点,并“就地”探索它,例如下面的 document.body
当然,这是出于调试目的。从下一章开始,我们将使用 JavaScript 访问和修改 DOM。
浏览器开发者工具对于开发有很大的帮助:我们可以探索 DOM,尝试一些东西,并找出问题所在。
遍历DOM
DOM 让我们可以对元素和它们中的内容做任何事,但是首先我们需要获取到对应的 DOM 对象。
对 DOM 的所有操作都是以 document 对象开始。它是 DOM 的主“入口点”。从它我们可以访问任何节点。
这里是一张描述对象间链接的图片,通过这些链接我们可以在 DOM 节点之间移动。
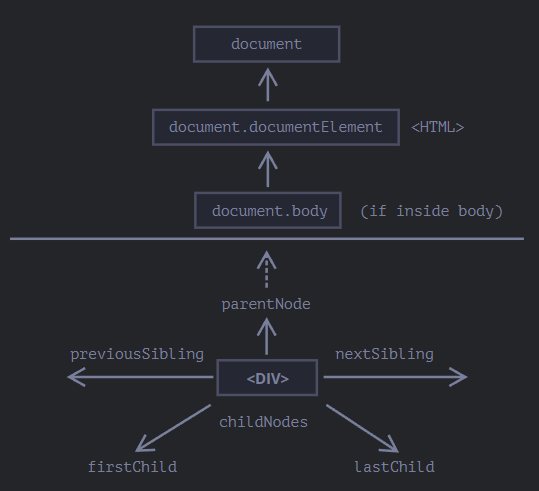
最顶层 documentElement body
最顶层的树节点可以直接作为 document 的属性来使用:
<html> = document.documentElement
最顶层的 document 节点是 document.documentElement。这是对应 <html> 标签的 DOM 节点。
<body> = document.body
另一个被广泛使用的 DOM 节点是 <body> 元素 —— document.body。
<head> = document.head
<head> 标签可以通过 document.head 访问。
这里有个问题:
document.body的值可能是null
脚本无法访问在运行时不存在的元素。
尤其是,如果一个脚本是在<head>中,那么脚本是访问不到document.body元素的,因为浏览器还没有读到它。
在 DOM 的世界中,
null就意味着“不存在”
在 DOM 中,null值就意味着“不存在”或者“没有这个节点”。
子节点 childNotes firstChild lastChild
从现在开始,我们将使用下面这两个术语:
- 子节点(或者叫作子) —— 对应的是直系的子元素。换句话说,它们被完全嵌套在给定的元素中。例如,
<head>和<body>就是<html>元素的子元素。 - 子孙元素 —— 嵌套在给定元素中的所有元素,包括子元素,以及子元素的子元素等。
<body>元素的子孙元素不仅包含直接的子元素<div>和<ul>,还包含像<li>(<ul>的子元素)和<b>(<li>的子元素)这样的元素 — 整个子树。
childNodes集合列出了所有子节点,包括文本节点。
for (let i = 0; i < document.body.childNodes.length; i++) {
alert( document.body.childNodes[i] ); // Text, DIV, Text, UL, ..., SCRIPT
}
请注意这里的一个有趣的细节。如果我们运行上面这个例子,所显示的最后一个元素是 <script>。实际上,文档下面还有很多东西,但是在这个脚本运行的时候,浏览器还没有读到下面的内容,所以这个脚本也就看不到它们。
firstChild 和 lastChild 属性是访问第一个和最后一个子元素的快捷方式。
它们只是简写。如果元素存在子节点,那么下面的脚本运行结果将是 true
elem.childNodes[0] === elem.firstChild
elem.childNodes[elem.childNodes.length - 1] === elem.lastChild
这里还有一个特别的函数 elem.hasChildNodes() 用于检查节点是否有子节点。
DOM 集合
正如我们看到的那样,childNodes 看起来就像一个数组。但实际上它并不是一个数组,而是一个 集合 —— 一个类数组的可迭代对象。
这个性质会导致两个重要的结果:
- 我们可以使用
for..of来迭代它
这是因为集合是可迭代的(提供了所需要的Symbol.iterator属性)。 - 无法使用数组的方法,因为它不是一个数组
集合的性质所得到的第一个结果很不错。第二个结果也还可以忍受,因为如果我们想要使用数组的方法的话,我们可以使用Array.from方法来从集合创建一个“真”数组
alert( Array.from(document.body.childNodes).filter ); // function
DOM 集合是只读的
DOM 集合,甚至可以说本章中列出的 所有 导航(navigation)属性都是只读的。
我们不能通过类似childNodes[i] = ...的操作来替换一个子节点。
修改子节点需要使用其它方法。我们将会在下一章中看到它们。
DOM 集合是实时的
除小部分例外,几乎所有的 DOM 集合都是 实时 的。换句话说,它们反映了 DOM 的当前状态。
如果我们保留一个对elem.childNodes的引用,然后向 DOM 中添加/移除节点,那么这些节点的更新会自动出现在集合中。
不要使用
for..in来遍历集合
可以使用for..of对集合进行迭代。但有时候人们会尝试使用for..in来迭代集合。
请不要这么做。for..in循环遍历的是所有可枚举的(enumerable)属性。集合还有一些“额外的”很少被用到的属性,通常这些属性也是我们不期望得到的
兄弟节点 父节点
兄弟节点(sibling) 是指有同一个父节点的节点。
例如,<head> 和 <body> 就是兄弟节点
<body>可以说是<head>的“下一个”或者“右边”兄弟节点。<head>可以说是<body>的“前一个”或者“左边”兄弟节点。
下一个兄弟节点在nextSibling属性中,上一个是在previousSibling属性中。
可以通过parentNode来访问父节点。
纯元素导航
上面列出的导航(navigation)属性引用 所有 节点。例如,在 childNodes 中我们可以看到文本节点,元素节点,甚至包括注释节点(如果它们存在的话)。
但是对于很多任务来说,我们并不想要文本节点或注释节点。我们希望操纵的是代表标签的和形成页面结构的元素节点。
所以,让我们看看更多只考虑 元素节点 的导航链接(navigation link)

这些链接和我们在上面提到过的类似,只是在词中间加了
Element:
children—— 仅那些作为元素节点的子代的节点。firstElementChild,lastElementChild—— 第一个和最后一个子元素。previousElementSibling,nextElementSibling—— 兄弟元素。parentElement—— 父元素。
为什么是
parentElement? 父节点可以不是一个元素吗?
parentElement属性返回的是“元素类型”的父节点,而parentNode返回的是“任何类型”的父节点。这些属性通常来说是一样的:它们都是用于获取父节点。
唯一的例外就是document.documentElement
alert( document.documentElement.parentNode ); // document
alert( document.documentElement.parentElement ); // null
因为根节点
document.documentElement(<html>)的父节点是document。但document不是一个元素节点,所以parentNode返回了document,但parentElement返回的是null。
当我们想从任意节点elem到<html>而不是到document时,这个细节可能很有用
while(elem = elem.parentElement) { // 向上,直到 <html>
alert( elem );
}
更多链接 表格
到现在,我们已经描述了基本的导航(navigation)属性。
方便起见,某些类型的 DOM 元素可能会提供特定于其类型的其他属性。
表格(Table)是一个很好的例子,它代表了一个特别重要的情况:
<table> 元素支持 (除了上面给出的,之外) 以下属性:
table.rows——<tr>元素的集合。table.caption/tHead/tFoot—— 引用元素<caption>,<thead>,<tfoot>。table.tBodies——<tbody>元素的集合(根据标准还有很多元素,但是这里至少会有一个 —— 即使没有被写在 HTML 源文件中,浏览器也会将其放入 DOM 中)。
<thead>,<tfoot>,<tbody>元素提供了rows属性:tbody.rows—— 表格内部<tr>元素的集合。
<tr>:tr.cells—— 在给定<tr>中的<td>和<th>单元格的集合。tr.sectionRowIndex—— 给定的<tr>在封闭的<thead>/<tbody>/<tfoot>中的位置(索引)。tr.rowIndex—— 在整个表格中<tr>的编号(包括表格的所有行)。
<td>和<th>:td.cellIndex—— 在封闭的<tr>中单元格的编号。
搜索 getElement querySelector
document.getElementById 或者只使用 id
如果一个元素有 id 特性(attribute),那我们就可以使用 document.getElementById(id) 方法获取该元素,无论它在哪里。
<div id="elem">
<div id="elem-content">Element</div>
</div>
<script>
// 获取该元素
let elem = document.getElementById('elem');
// 将该元素背景改为红色
elem.style.background = 'red';
</script>
<script>
// elem 是对带有 id="elem" 的 DOM 元素的引用
elem.style.background = 'red';
// id="elem-content" 内有连字符,所以它不能成为一个变量
// ...但是我们可以通过使用方括号 window['elem-content'] 来访问它
</script>
除非我们声明一个具有相同名称的 JavaScript 变量,否则它具有优先权
<div id="elem"></div>
<script>
let elem = 5; // 现在 elem 是 5,而不是对 <div id="elem"> 的引用
alert(elem); // 5
</script>
请不要使用以 id 命名的全局变量来访问元素
在规范中 对此行为进行了描述,所以它是一种标准。但这是注意考虑到兼容性才支持的。
浏览器尝试通过混合 JavaScript 和 DOM 的命名空间来帮助我们。对于内联到 HTML 中的简单脚本来说,这还行,但是通常来说,这不是一件好事。因为这可能会造成命名冲突。另外,当人们阅读 JavaScript 代码且看不到对应的 HTML 时,变量的来源就会不明显。
在本教程中,我们只会在元素来源非常明显时,为了简洁起见,才会使用id直接引用对应的元素。
在实际开发中,document.getElementById是首选方法。
id必须是唯一的
id必须是唯一的。在文档中,只能有一个元素带有给定的id。
如果有多个元素都带有同一个id,那么使用它的方法的行为是不可预测的,例如document.getElementById可能会随机返回其中一个元素。因此,请遵守规则,保持id的唯一性。
只有
document.getElementById,没有anyElem.getElementById
getElementById方法只能被在document对象上调用。它会在整个文档中查找给定的id。
querySelectorAll
到目前为止,最通用的方法是 elem.querySelectorAll(css),它返回 elem 中与给定 CSS 选择器匹配的所有元素。
这个方法确实功能强大,因为可以使用任何 CSS 选择器。
也可以使用伪类
CSS 选择器的伪类,例如:hover和:active也都是被支持的。例如,document.querySelectorAll(':hover')将会返回鼠标指针正处于其上方的元素的集合(按嵌套顺序:从最外层<html>到嵌套最多的元素)。
querySelector
elem.querySelector(css) 调用会返回给定 CSS 选择器的第一个元素。
换句话说,结果与 elem.querySelectorAll(css)[0] 相同,但是后者会查找 所有 元素,并从中选取一个,而 elem.querySelector 只会查找一个。因此它在速度上更快,并且写起来更短。
matches
之前的方法是搜索 DOM。
elem.matches(css) 不会查找任何内容,它只会检查 elem 是否与给定的 CSS 选择器匹配。它返回 true 或 false。
当我们遍历元素(例如数组或其他内容)并试图过滤那些我们感兴趣的元素时,这个方法会很有用。
closest
元素的祖先(ancestor)是:父级,父级的父级,它的父级等。祖先们一起组成了从元素到顶端的父级链。
elem.closest(css) 方法会查找与 CSS 选择器匹配的最近的祖先。elem 自己也会被搜索。
换句话说,方法 closest 在元素中得到了提升,并检查每个父级。如果它与选择器匹配,则停止搜索并返回该祖先。
getElementsBy*
还有其他通过标签,类等查找节点的方法。
如今,它们大多已经成为了历史,因为 querySelector 功能更强大,写起来更短。
因此,这里我们介绍它们只是为了完整起见,而你仍然可以在旧脚本中找到这些方法。
elem.getElementsByTagName(tag)查找具有给定标签的元素,并返回它们的集合。tag参数也可以是对于“任何标签”的星号"*"。elem.getElementsByClassName(className)返回具有给定CSS类的元素。document.getElementsByName(name)返回在文档范围内具有给定name特性的元素。很少使用。
不要忘记字母
"s"!
新手开发者有时会忘记字符"s"。也就是说,他们会调用getElementByTagName而不是getElement**s**ByTagName。
getElementById中没有字母"s",是因为它只返回单个元素。但是getElementsByTagName返回的是元素的集合,所以里面有"s"。
它返回的是一个集合,不是一个元素!
另一个普遍的错误是不加索引
这是行不通的,因为它需要的是一个 input 的 集合,并将值赋(assign)给它,而不是赋值给其中的一个元素。
我们应该遍历集合或通过对应的索引来获取元素,然后赋值
实时的集合
所有的 "getElementsBy*" 方法都会返回一个 实时的(live) 集合。这样的集合始终反映的是文档的当前状态,并且在文档发生更改时会“自动更新”。
在下面的例子中,有两个脚本。
- 第一个创建了对
<div>的集合的引用。截至目前,它的长度是1。 - 第二个脚本在浏览器再遇到一个
<div>时运行,所以它的长度是2。
<div>First div</div>
<script>
let divs = document.getElementsByTagName('div');
alert(divs.length); // 1
</script>
<div>Second div</div>
<script>
alert(divs.length); // 2
</script>
相反,querySelectorAll 返回的是一个 静态的 集合。就像元素的固定数组。
如果我们使用它,那么两个脚本都会输出 1:
<div>First div</div>
<script>
let divs = document.querySelectorAll('div');
alert(divs.length); // 1
</script>
<div>Second div</div>
<script>
alert(divs.length); // 1
</script>
节点属性 type tag 和 content
DOM 节点类
不同的 DOM 节点可能有不同的属性。例如,标签 <a> 相对应的元素节点具有链接相关的(link-related)属性,标签 <input> 相对应的元素节点具有与输入相关的属性,等。文本节点与元素节点不同。但是所有这些标签对应的 DOM 节点之间也存在共有的属性和方法,因为所有类型的 DOM 节点都形成了一个单一层次的结构(single hierarchy)。
每个 DOM 节点都属于相应的内建类。
层次结构(hierarchy)的根节点是 EventTarget,Node 继承自它,其他 DOM 节点继承自 Node。

类如下所示:
- EventTarget —— 是一切的根“抽象(abstract)”类。
该类的对象从未被创建。它作为一个基础,以便让所有 DOM 节点都支持所谓的“事件(event)”,我们会在之后学习它。 - Node —— 也是一个“抽象”类,充当 DOM 节点的基础。
它提供了树的核心功能:parentNode,nextSibling,childNodes等(它们都是 getter)。Node类的对象从未被创建。但是还有一些继承自它的其他类(因此继承了Node的功能)。 - Document 由于历史原因通常被
HTMLDocument继承(尽管最新的规范没有规定)—— 是一个整体的文档。
全局变量document就是属于这个类。它作为 DOM 的入口。 - CharacterData —— 一个“抽象”类,被下述类继承:
- Element —— 是 DOM 元素的基础类。
它提供了元素级导航(navigation),如nextElementSibling,children,以及搜索方法,如getElementsByTagName和querySelector。
浏览器不仅支持 HTML,还支持 XML 和 SVG。因此,Element类充当的是更具体的类的基础:SVGElement,XMLElement(我们在这里不需要它)和HTMLElement。 - 最后,HTMLElement —— 是所有 HTML 元素的基础类。我们大部分时候都会用到它。
它会被更具体的 HTML 元素继承:- HTMLInputElement ——
<input>元素的类, - HTMLBodyElement ——
<body>元素的类, - HTMLAnchorElement ——
<a>元素的类, - ……等
还有很多其他标签具有自己的类,可能还具有特定的属性和方法,而一些元素,如<span>、<section>、<article>等,没有任何特定的属性,所以它们是HTMLElement类的实例。
因此,给定节点的全部属性和方法都是继承链的结果。
- HTMLInputElement ——
例如,我们考虑一下 <input> 元素的 DOM 对象。它属于 HTMLInputElement 类。
它获取属性和方法,并将其作为下列类(按继承顺序列出)的叠加:
HTMLInputElement—— 该类提供特定于输入的属性,HTMLElement—— 它提供了通用(common)的 HTML 元素方法(以及 getter 和 setter)Element—— 提供通用(generic)元素方法,Node—— 提供通用 DOM 节点属性,EventTarget—— 为事件(包括事件本身)提供支持,- ……最后,它继承自
Object,因为像hasOwnProperty这样的“普通对象”方法也是可用的。
我们可以通过回调来查看 DOM 节点类名,因为对象通常都具有constructor属性。它引用类的 constructor,constructor.name就是它的名称
document.body.constructor.name // HTMLBodyElement
document.body // [object HTMLBodyElement]
document.body instanceof HTMLBodyElement // true
document.body instanceof HTMLElement // true
document.body instanceof Element // true
document.body instanceof Node // true
document.body instanceof EventTarget // true
正如我们所看到的,DOM 节点是常规的 JavaScript 对象。它们使用基于原型的类进行继承。
在浏览器中,使用 console.dir(elem) 输出元素来查看也是非常容易的。在控制台中,你可以看到 HTMLElement.prototype 和 Element.prototype 等。
console.dir(elem)与console.log(elem)
大多数浏览器在其开发者工具中都支持这两个命令:console.log和console.dir。它们将它们的参数输出到控制台中。对于 JavaScript 对象,这些命令通常做的是相同的事。
但对于 DOM 元素,它们是不同的:
console.log(elem)显示元素的 DOM 树。console.dir(elem)将元素显示为 DOM 对象,非常适合探索其属性。
规范中的 IDL
在规范中,DOM 类不是使用 JavaScript 来描述的,而是一种特殊的 接口描述语言(Interface description language),简写为 IDL,它通常很容易理解。
在 IDL 中,所有属性以其类型开头。例如,DOMString和boolean等。
以下是摘录(excerpt),并附有注释:
// 定义 HTMLInputElement
// 冒号 ":" 表示 HTMLInputElement 继承自 HTMLElement
interface HTMLInputElement: HTMLElement {
// 接下来是 <input> 元素的属性和方法
// "DOMString" 表示属性的值是字符串
attribute DOMString accept;
attribute DOMString alt;
attribute DOMString autocomplete;
attribute DOMString value;
// 布尔值属性(true/false)
attribute boolean autofocus;
...
// 现在方法:"void" 表示方法没有返回值
void select();
...
}
nodeType 属性
nodeType 属性提供了另一种“过时的”用来获取 DOM 节点类型的方法。
它有一个数值型值(numeric value):
- 对于元素节点
elem.nodeType == 1, - 对于文本节点
elem.nodeType == 3, - 对于 document 对象
elem.nodeType == 9, - 在 规范 中还有一些其他值。
<body>
<script>
let elem = document.body;
// 让我们检查一下:elem 中的节点类型是什么?
alert(elem.nodeType); // 1 => element
// 它的第一个子节点的类型是……
alert(elem.firstChild.nodeType); // 3 => text
// 对于 document 对象,类型是 9
alert( document.nodeType ); // 9
</script>
</body>
在现代脚本中,我们可以使用 instanceof 和其他基于类的检查方法来查看节点类型,但有时 nodeType 可能更简单。我们只能读取 nodeType 而不能修改它。
标签 nodeName tagName
给定一个 DOM 节点,我们可以从 nodeName 或者 tagName 属性中读取它的标签名
alert( document.body.nodeName ); // BODY
alert( document.body.tagName ); // BODY
tagName 和 nodeName 之间有什么不同吗?
当然,差异就体现在它们的名字上,但确实有些微妙。
tagName属性仅适用于Element节点。nodeName是为任意Node定义的:- 对于元素,它的意义与
tagName相同。 - 对于其他节点类型(text,comment 等),它拥有一个对应节点类型的字符串。
换句话说,tagName仅受元素节点支持(因为它起源于Element类),而nodeName则可以说明其他节点类型。
例如,我们比较一下document的tagName和nodeName,以及一个注释节点
- 对于元素,它的意义与
<body><!-- comment -->
<script>
// for comment
alert( document.body.firstChild.tagName ); // undefined(不是一个元素)
alert( document.body.firstChild.nodeName ); // #comment
// for document
alert( document.tagName ); // undefined(不是一个元素)
alert( document.nodeName ); // #document
</script>
</body>
如果我们只处理元素,那么 tagName 和 nodeName 这两种方法,我们都可以使用,没有区别。
标签名称始终是大写的,除非是在 XML 模式下
浏览器有两种处理文档(document)的模式:HTML 和 XML。通常,HTML 模式用于网页。只有在浏览器接收到带有Content-Type: application/xml+xhtmlheader 的 XML-document 时,XML 模式才会被启用。
在 HTML 模式下,tagName/nodeName始终是大写的:它是BODY,而不是<body>或<BoDy>。
在 XML 模式中,大小写保持为“原样”。如今,XML 模式很少被使用。
innerHTML 内容
innerHTML 属性允许将元素中的 HTML 获取为字符串形式。
我们也可以修改它。因此,它是更改页面最有效的方法之一。
下面这个示例显示了 document.body 中的内容,然后将其完全替换
<body>
<p>A paragraph</p>
<div>A div</div>
<script>
alert( document.body.innerHTML ); // 读取当前内容
document.body.innerHTML = 'The new BODY!'; // 替换它
</script>
</body>
脚本不会执行
如果innerHTML将一个<script>标签插入到 document 中 —— 它会成为 HTML 的一部分,但是不会执行。
Be careful "innerHTML += "会完全重写
我们可以使用 elem.innerHTML+="more html" 将 HTML 附加到元素上。
但我们必须非常谨慎地使用它,因为我们所做的 不是 附加内容,而且完全地重写。
从技术上来说,下面这两行代码的作用相同
elem.innerHTML += "...";
// 进行写入的一种更简短的方式:
elem.innerHTML = elem.innerHTML + "..."
换句话说,innerHTML+= 做了以下工作:
- 移除旧的内容。
- 然后写入新的
innerHTML(新旧结合)。
因为内容已“归零”并从头开始重写,因此所有的图片和其他资源都将重写加载。
在上面的chatDiv示例中,chatDiv.innerHTML+="How goes?"重建了 HTML 内容并重新加载了smile.gif(希望它是缓存的)。如果chatDiv有许多其他文本和图片,那么就很容易看到重新加载(译注:是指在有很多内容时,重新加载会耗费更多的时间,所以你就很容易看见页面重载的过程)。
并且还会有其他副作用。例如,如果现有的文本被用鼠标选中了,那么大多数浏览器都会在重写innerHTML时删除选定状态。如果这里有一个带有用户输入的文本的<input>,那么这个被输入的文本将会被移除。诸如此类。
幸运的是,除了innerHTML,还有其他可以添加 HTML 的方法,我们很快就会学到。
outerHTML: 元素的完整HTML
outerHTML 属性包含了元素的完整 HTML。就像 innerHTML 加上元素本身一样。
注意:与 innerHTML 不同,写入 outerHTML 不会改变元素。而是在 DOM 中替换它。
是的,听起来很奇怪,它确实很奇怪,这就是为什么我们在这里对此做了一个单独的注释。看一下。
<div>Hello, world!</div>
<script>
let div = document.querySelector('div');
// 使用 <p>...</p> 替换 div.outerHTML
div.outerHTML = '<p>A new element</p>'; // (*)
// 蛤!'div' 还是原来那样!
alert(div.outerHTML); // <div>Hello, world!</div> (**)
</script>
看起来真的很奇怪,对吧?
在 (*) 行,我们使用 <p>A new element</p> 替换 div。在外部文档(DOM)中我们可以看到的是新内容而不是 <div>。但是正如我们在 (**) 行所看到的,旧的 div 变量并没有被改变。
outerHTML 赋值不会修改 DOM 元素(在这个例子中是被 ‘div’ 引用的对象),而是将其从 DOM 中删除并在其位置插入新的 HTML。
所以,在 div.outerHTML=... 中发生的事情是:
div被从文档(document)中移除。- 另一个 HTML 片段
<p>A new element</p>被插入到其位置上。 div仍拥有其旧的值。新的 HTML 没有被赋值给任何变量。
在这儿很容易出错:修改div.outerHTML然后继续使用div,就好像它包含的是新内容一样。但事实并非如此。这样的东西对于innerHTML是正确的,但是对于outerHTML却不正确。
我们可以向elem.outerHTML写入内容,但是要记住,它不会改变我们所写的元素(‘elem’)。而是将新的 HTML 放在其位置上。我们可以通过查询 DOM 来获取对新元素的引用。
nodeValue/data: 文本节点内容
innerHTML 属性仅对元素节点有效。
其他节点类型,例如文本节点,具有它们的对应项:nodeValue 和 data 属性。这两者在实际使用中几乎相同,只有细微规范上的差异。因此,我们将使用 data,因为它更短。
对于文本节点,我们可以想象读取或修改它们的原因,但是注释呢?
有时,开发者会将信息或模板说明嵌入到 HTML 中的注释中,如下所示
<!-- if isAdmin -->
<div>Welcome, Admin!</div>
<!-- /if -->
……然后,JavaScript 可以从 data 属性中读取它,并处理嵌入的指令。
textContent: 纯文本
textContent 提供了对元素内的 文本 的访问权限:仅文本,去掉所有 <tags>。
<div id="news">
<h1>Headline!</h1>
<p>Martians attack people!</p>
</div>
<script>
// Headline! Martians attack people!
alert(news.textContent);
</script>
正如我们所看到,只返回文本,就像所有 <tags> 都被剪掉了一样,但实际上其中的文本仍然存在。
在实际开发中,用到这样的文本读取的场景非常少。
写入 textContent 要有用得多,因为它允许以“安全方式”写入文本。
假设我们有一个用户输入的任意字符串,我们希望将其显示出来。
- 使用
innerHTML,我们将其“作为 HTML”插入,带有所有 HTML 标签。 - 使用
textContent,我们将其“作为文本”插入,所有符号(symbol)均按字面意义处理。
<div id="elem1"></div>
<div id="elem2"></div>
<script>
let name = prompt("What's your name?", "<b>Winnie-the-Pooh!</b>");
elem1.innerHTML = name;
elem2.textContent = name;
</script>
- 第一个
<div>获取 name “作为 HTML”:所有标签都变成标签,所以我们可以看到粗体的 name。 - 第二个
<div>获取 name “作为文本”,因此我们可以从字面上看到<b>Winnie-the-Pooh!</b>。
在大多数情况下,我们期望来自用户的文本,并希望将其视为文本对待。我们不希望在我们的网站中出现意料不到的 HTML。对textContent的赋值正好可以做到这一点。
"hidden" 属性
“hidden” 特性(attribute)和 DOM 属性(property)指定元素是否可见。
我们可以在 HTML 中使用它,或者使用 JavaScript 对其进行赋值
<div>Both divs below are hidden</div>
<div hidden>With the attribute "hidden"</div>
<div id="elem">JavaScript assigned the property "hidden"</div>
<script>
elem.hidden = true;
</script>
从技术上来说,hidden 与 style="display:none" 做的是相同的事。但 hidden 写法更简洁。
这里有一个 blinking 元素
<div id="elem">A blinking element</div>
<script>
setInterval(() => elem.hidden = !elem.hidden, 1000);
</script>
更多属性
DOM 元素还有其他属性,特别是那些依赖于 class 的属性:
value——<input>,<select>和<textarea>(HTMLInputElement,HTMLSelectElement……)的 value。href——<a href="...">(HTMLAnchorElement)的 href。id—— 所有元素(HTMLElement)的 “id” 特性(attribute)的值。- ……以及更多其他内容……
如果我们想要快速获取它们,或者对具体的浏览器规范感兴趣 — 我们总是可以使用console.dir(elem)输出元素并读取其属性。或者在浏览器的开发者工具的元素(Elements)标签页中探索“DOM 属性”。
特性和属性 (Attributes and properties)
当浏览器加载页面时,它会“读取”(或者称之为:“解析”)HTML 并从中生成 DOM 对象。对于元素节点,大多数标准的 HTML 特性(attributes)会自动变成 DOM 对象的属性(properties)。(译注:attribute 和 property 两词意思相近,为作区分,全文将 attribute 译为“特性”,property 译为“属性”,请读者注意区分。)
例如,如果标签是 <body id="page">,那么 DOM 对象就会有 body.id="page"。
DOM 属性
我们已经见过了内建 DOM 属性。它们数量庞大。但是从技术上讲,没有人会限制我们,如果我们觉得这些 DOM 还不够,我们可以添加我们自己的。
DOM 节点是常规的 JavaScript 对象。我们可以更改它们。
// 添加一个属性
document.body.myData = {
name: 'xxx',
title: 'xxx'
};
// 添加一个方法
document.body.sayTagName = function() {
alert(this.tagName);
};
// 修改内建属性的原型,为所有元素添加一个方法
Element.prototype.sayHi = function() {
alert("Hi");
};
所以,DOM 属性和方法的行为就像常规的 Javascript 对象一样:
- 它们可以有很多值。
- 它们是大小写敏感的(要写成
elem.nodeType,而不是elem.NoDeTyPe)。
HTML 属性
在 HTML 中,标签可能拥有特性(attributes)。当浏览器解析 HTML 文本,并根据标签创建 DOM 对象时,浏览器会辨别 标准的 特性并以此创建 DOM 属性。
所以,当一个元素有 id 或其他 标准的 特性,那么就会生成对应的 DOM 属性。但是非 标准的 特性则不会。
<body id="test" something="non-standard">
<script>
alert(document.body.id); // test
// 非标准的特性没有获得对应的属性
alert(document.body.something); // undefined
</script>
</body>
请注意,一个元素的标准的特性对于另一个元素可能是未知的。例如 "type" 是 <input> 的一个标准的特性(HTMLInputElement),但对于 <body>(HTMLBodyElement)来说则不是。规范中对相应元素类的标准的属性进行了详细的描述。
<body id="body" type="...">
<input id="input" type="text">
<script>
alert(input.type); // text
alert(body.type); // undefined:DOM 属性没有被创建,因为它不是一个标准的特性
</script>
</body>
所以,如果一个特性不是标准的,那么就没有相对应的 DOM 属性。那我们有什么方法来访问这些特性吗?
当然。所有特性都可以通过使用以下方法进行访问:
elem.hasAttribute(name)—— 检查特性是否存在。elem.getAttribute(name)—— 获取这个特性值。elem.setAttribute(name, value)—— 设置这个特性值。elem.removeAttribute(name)—— 移除这个特性。
这些方法操作的实际上是 HTML 中的内容。
我们也可以使用elem.attributes读取所有特性:属于内建 Attr 类的对象的集合,具有name和value属性。
HTML 特性有以下几个特征:
- 它们的名字是大小写不敏感的(
id与ID相同)。 - 它们的值总是字符串类型的。
<body>
<div id="elem" about="Elephant"></div>
<script>
alert( elem.getAttribute('About') ); // (1) 'Elephant',读取
elem.setAttribute('Test', 123); // (2) 写入
alert( elem.outerHTML ); // (3) 查看特性是否在 HTML 中(在)
for (let attr of elem.attributes) { // (4) 列出所有
alert( `${attr.name} = ${attr.value}` );
}
</script>
</body>
请注意:
getAttribute('About')—— 这里的第一个字母是大写的,但是在 HTML 中,它们都是小写的。但这没有影响:特性的名称是大小写不敏感的。- 我们可以将任何东西赋值给特性,但是这些东西会变成字符串类型的。所以这里我们的值为
"123"。 - 所有特性,包括我们设置的那个特性,在
outerHTML中都是可见的。 attributes集合是可迭代对象,该对象将所有元素的特性(标准和非标准的)作为name和value属性存储在对象中。
属性-特性同步
当一个标准的特性被改变,对应的属性也会自动更新,(除了几个特例)反之亦然。
在下面这个示例中,id 被修改为特性,我们可以看到对应的属性也发生了变化。
<input>
<script>
let input = document.querySelector('input');
// 特性 => 属性
input.setAttribute('id', 'id');
alert(input.id); // id(被更新了)
// 属性 => 特性
input.id = 'newId';
alert(input.getAttribute('id')); // newId(被更新了)
</script>
但这里也有些例外,例如 input.value 只能从特性同步到属性,反过来则不行
<input>
<script>
let input = document.querySelector('input');
// 特性 => 属性
input.setAttribute('value', 'text');
alert(input.value); // text
// 这个操作无效,属性 => 特性
input.value = 'newValue';
alert(input.getAttribute('value')); // text(没有被更新!)
</script>
在上面这个例子中:
- 改变特性值
value会更新属性。 - 但是属性的更改不会影响特性。
这个“功能”在实际中会派上用场,因为用户行为可能会导致value的更改,然后在这些操作之后,如果我们想从 HTML 中恢复“原始”值,那么该值就在特性中。
DOM 属性是多类型的
DOM 属性不总是字符串类型的。例如,input.checked 属性(对于 checkbox 的)是布尔型的。
<input id="input" type="checkbox" checked> checkbox
<script>
alert(input.getAttribute('checked')); // 特性值是:空字符串
alert(input.checked); // 属性值是:true
</script>
还有其他的例子。style 特性是字符串类型的,但 style 属性是一个对象
<div id="div" style="color:red;font-size:120%">Hello</div>
<script>
// 字符串
alert(div.getAttribute('style')); // color:red;font-size:120%
// 对象
alert(div.style); // [object CSSStyleDeclaration]
alert(div.style.color); // red
</script>
尽管大多数 DOM 属性都是字符串类型的。
有一种非常少见的情况,即使一个 DOM 属性是字符串类型的,但它可能和 HTML 特性也是不同的。例如,href DOM 属性一直是一个 完整的 URL,即使该特性包含一个相对路径或者包含一个 #hash。
<a id="a" href="#hello">link</a>
<script>
// 特性
alert(a.getAttribute('href')); // #hello
// 属性
alert(a.href ); // http://site.com/page#hello 形式的完整 URL
</script>
如果我们需要 href 特性的值,或者其他与 HTML 中所写的完全相同的特性,则可以使用 getAttribute。
非标准的特性,dataset
当编写 HTML 时,我们会用到很多标准的特性。但是非标准的,自定义的呢?首先,让我们看看它们是否有用?用来做什么?
有时,非标准的特性常常用于将自定义的数据从 HTML 传递到 JavaScript,或者用于为 JavaScript “标记” HTML 元素。
<!-- 标记这个 div 以在这显示 "name" -->
<div show-info="name"></div>
<!-- 标记这个 div 以在这显示 "age" -->
<div show-info="age"></div>
<script>
// 这段代码找到带有标记的元素,并显示需要的内容
let user = {
name: "Pete",
age: 25
};
for(let div of document.querySelectorAll('[show-info]')) {
// 在字段中插入相应的信息
let field = div.getAttribute('show-info');
div.innerHTML = user[field]; // 首先 "name" 变为 Pete,然后 "age" 变为 25
}
</script>
它们还可以用来设置元素的样式。
例如,这里使用 order-state 特性来设置订单状态
<style>
/* 样式依赖于自定义特性 "order-state" */
.order[order-state="new"] {
color: green;
}
.order[order-state="pending"] {
color: blue;
}
.order[order-state="canceled"] {
color: red;
}
</style>
<div class="order" order-state="new">
A new order.
</div>
<div class="order" order-state="pending">
A pending order.
</div>
<div class="order" order-state="canceled">
A canceled order.
</div>
为什么使用特性比使用 .order-state-new,.order-state-pending,.order-state-canceled 这些样式类要好?
因为特性值更容易管理。我们可以轻松地更改状态
// 比删除旧的或者添加一个新的类要简单一些
div.setAttribute('order-state', 'canceled');
但是自定义的特性也存在问题。如果我们出于我们的目的使用了非标准的特性,之后它被引入到了标准中并有了其自己的用途,该怎么办?HTML 语言是在不断发展的,并且更多的特性出现在了标准中,以满足开发者的需求。在这种情况下,自定义的属性可能会产生意料不到的影响。
为了避免冲突,存在 data-* 特性。
所有以 “data-” 开头的特性均被保留供程序员使用。它们可在 dataset 属性中使用。
例如,如果一个 elem 有一个名为 "data-about" 的特性,那么可以通过 elem.dataset.about 取到它。
<body data-about="Elephants">
<script>
alert(document.body.dataset.about); // Elephants
</script>
像 data-order-state 这样的多词特性可以以驼峰式进行调用:dataset.orderState。
<style>
.order[data-order-state="new"] {
color: green;
}
.order[data-order-state="pending"] {
color: blue;
}
.order[data-order-state="canceled"] {
color: red;
}
</style>
<div id="order" class="order" data-order-state="new">
A new order.
</div>
<script>
// 读取
alert(order.dataset.orderState); // new
// 修改
order.dataset.orderState = "pending"; // (*)
</script>
使用 data-* 特性是一种合法且安全的传递自定义数据的方式。
请注意,我们不仅可以读取数据,还可以修改数据属性(data-attributes)。然后 CSS 会更新相应的视图:在上面这个例子中的最后一行 (*) 将颜色更改为了蓝色。
修改文档 (document)
创建一个元素
document.creatElement(tag)
用给定的标签创建一个新 元素节点(element node)
let div = document.createElement('div');
document.createTextNode(text)
用给定的文本创建一个 文本节点
let textNode = document.createTextNode('Here I am');
大多数情况下,我们需要为此消息创建像 div 这样的元素节点。
创建一条消息
// 1. 创建 <div> 元素
let div = document.createElement('div');
// 2. 将元素的类设置为 "alert"
div.className = "alert";
// 3. 填充消息内容
div.innerHTML = "<strong>Hi there!</strong> You've read an important message.";
我们已经创建了该元素。但到目前为止,它还只是在一个名为 div 的变量中,尚未在页面中。所以我们无法在页面上看到它。
插入方法
为了让 div 显示出来,我们需要将其插入到 document 中的某处。例如,通过 document.body 将其插入到 <body> 元素里。
对此有一个特殊的方法 append:document.body.append(div)
我们对 document.body 调用了 append 方法。不过我们可以在其他任何元素上调用 append 方法,以将另外一个元素放入到里面。例如,通过调用 div.append(anotherElement),我们便可以在 <div> 末尾添加一些内容。
这里是更多的元素插入方法,指明了不同的插入位置:
node.append(...nodes or strings)—— 在node末尾 插入节点或字符串,node.prepend(...nodes or strings)—— 在node开头 插入节点或字符串,node.before(...nodes or strings)—— 在node前面 插入节点或字符串,node.after(...nodes or strings)—— 在node后面 插入节点或字符串,node.replaceWith(...nodes or strings)—— 将node替换为给定的节点或字符串。
这些方法的参数可以是一个要插入的任意的 DOM 节点列表,或者文本字符串(会被自动转换成文本节点)。
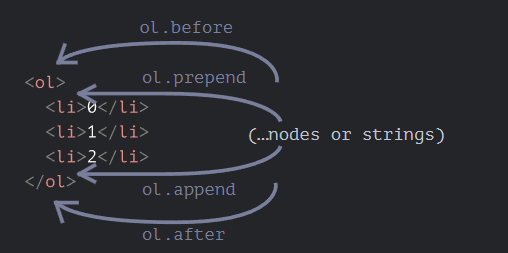
<div id="div"></div>
<script>
div.before('<p>Hello</p>', document.createElement('hr'));
</script>
请注意:这里的文字都被“作为文本”插入,而不是“作为 HTML 代码”。因此像 <、> 这样的符号都会被作转义处理来保证正确显示。
最终为
<p>Hello</p>
<hr>
<div id="div"></div>
换句话说,字符串被以一种安全的方式插入到页面中,就像 elem.textContent 所做的一样。
所以,这些方法只能用来插入 DOM 节点或文本片段。
但如果我们想要将内容“作为 HTML 代码插入”,让内容中的所有标签和其他东西都像使用 elem.innerHTML 所表现的效果一样,那应该怎么办呢?
insertAdjacentHTML/Text/Element
为此,我们可以使用另一个非常通用的方法:elem.insertAdjacentHTML(where, html)。
该方法的第一个参数是代码字(code word),指定相对于 elem 的插入位置。必须为以下之一:
"beforebegin"—— 将html插入到elem之前,"afterbegin"—— 将html插入到elem开头,"beforeend"—— 将html插入到elem末尾,"afterend"—— 将html插入到elem之后。
第二个参数是 HTML 字符串,该字符串会被“作为 HTML” 插入。

我们很容易就会注意到这张图片和上一张图片的相似之处。插入点实际上是相同的,但此方法插入的是 HTML。
这个方法有两个兄弟:elem.insertAdjacentText(where, text)—— 语法一样,但是将text字符串“作为文本”插入而不是作为 HTML,elem.insertAdjacentElement(where, elem)—— 语法一样,但是插入的是一个元素。
它们的存在主要是为了使语法“统一”。实际上,大多数时候只使用insertAdjacentHTML。因为对于元素和文本,我们有append/prepend/before/after方法 —— 它们也可以用于插入节点/文本片段,但写起来更短。

节点移除
node.remove()
请注意:如果我们要将一个元素 移动 到另一个地方,则无需将其从原来的位置中删除。
所有插入方法都会自动从旧位置删除该节点。
<div id="first">First</div>
<div id="second">Second</div>
<script>
// 无需调用 remove
second.after(first); // 获取 #second,并在其后面插入 #first
</script>
克隆节点 cloneNode
当我们有一个很大的元素时,克隆的方式可能更快更简单。
调用 elem.cloneNode(true) 来创建元素的一个“深”克隆 —— 具有所有特性(attribute)和子元素。如果我们调用 elem.cloneNode(false),那克隆就不包括子元素。
DocumentFragment
DocumentFragment 是一个特殊的 DOM 节点,用作来传递节点列表的包装器(wrapper)。
我们可以向其附加其他节点,但是当我们将其插入某个位置时,则会插入其内容。
例如,下面这段代码中的 getListContent 会生成带有 <li> 列表项的片段,然后将其插入到 <ul> 中
<ul id="ul"></ul>
<script>
function getListContent() {
let fragment = new DocumentFragment();
for(let i=1; i<=3; i++) {
let li = document.createElement('li');
li.append(i);
fragment.append(li);
}
return fragment;
}
ul.append(getListContent()); // (*)
</script>
请注意,在最后一行 (*) 我们附加了 DocumentFragment,但是它和 ul “融为一体(blends in)”了,所以最终的文档结构应该是
<ul>
<li>1</li>
<li>2</li>
<li>3</li>
</ul>
DocumentFragment 很少被显式使用。如果可以改为返回一个节点数组,那为什么还要附加到特殊类型的节点上呢?
我们之所以提到 DocumentFragment,主要是因为它上面有一些概念,例如 template 元素,我们将在以后讨论。
老式的insert/remove
老式用法
这些内容有助于理解旧脚本,但不适合用于新代码的开发中。
parentElem.appendChild(node)
将 node 附加为 parentElem 的最后一个子元素。
parentElem.insertBefore(node, nextSibling)
在 parentElem 的 nextSibling 前插入 node。
parentElem.replaceChild(node, oldChild)
将 parentElem 的后代中的 oldChild 替换为 node。
所有这些方法都会返回插入/删除的节点。换句话说,parentElem.appendChild(node) 返回 node。但是通常我们不会使用返回值,我们只是使用对应的方法。
关于 document.write
非常古老的向网页添加内容的方法:document.write。
调用 document.write(html) 意味着将 html “就地马上”写入页面。html 字符串可以是动态生成的,所以它很灵活。我们可以使用 JavaScript 创建一个完整的页面并对其进行写入。
这个方法来自于没有 DOM,没有标准的上古时期……。但这个方法依被保留了下来,因为还有脚本在使用它。
由于以下重要的限制,在现代脚本中我们很少看到它:
document.write 调用只在页面加载时工作。
因此,在某种程度上讲,它在“加载完成”阶段是不可用的,这与我们上面介绍的其他 DOM 方法不同。
这是它的缺陷。
还有一个好处。从技术上讲,当在浏览器正在读取(“解析”)传入的 HTML 时调用 document.write 方法来写入一些东西,浏览器会像它本来就在 HTML 文本中那样使用它。
所以它运行起来出奇的快,因为它 不涉及 DOM 修改。它直接写入到页面文本中,而此时 DOM 尚未构建。
因此,如果我们需要向 HTML 动态地添加大量文本,并且我们正处于页面加载阶段,并且速度很重要,那么它可能会有帮助。但实际上,这些要求很少同时出现。我们可以在脚本中看到此方法,通常是因为这些脚本很旧。
样式和类
在我们讨论 JavaScript 处理样式和类的方法之前 —— 有一个重要的规则。希望它足够明显,但是我们仍然必须提到它。
通常有两种设置元素样式的方式:
- 在 CSS 中创建一个类,并添加它:
<div class="..."> - 将属性直接写入
style:<div style="...">。
JavaScript 既可以修改类,也可以修改style属性。
相较于将样式写入style属性,我们应该首选通过 CSS 类的方式来添加样式。仅当类“无法处理”时,才应选择使用style属性的方式。
例如,如果我们动态地计算元素的坐标,并希望通过 JavaScript 来设置它们,那么使用style是可以接受的
let top = /* 复杂的计算 */;
let left = /* 复杂的计算 */;
elem.style.left = left; // 例如 '123px',在运行时计算出的
elem.style.top = top; // 例如 '456px'
对于其他情况,例如将文本设为红色,添加一个背景图标 —— 可以在 CSS 中对这些样式进行描述,然后添加类(JavaScript 可以做到)。这样更灵活,更易于支持。
className classList
更改类是脚本中最常见的操作之一。
在很久以前,JavaScript 中有一个限制:像 "class" 这样的保留字不能用作对象的属性。这一限制现在已经不存在了,但当时就不能存在像 elem.class 这样的 "class" 属性。
因此,对于类,引入了看起来类似的属性 "className":elem.className 对应于 "class" 特性(attribute)。
如果我们对 elem.className 进行赋值,它将替换类中的整个字符串。有时,这正是我们所需要的,但通常我们希望添加/删除单个类。
这里还有另一个属性:elem.classList。
elem.classList 是一个特殊的对象,它具有 add/remove/toggle 单个类的方法。
因此,我们既可以使用 className 对完整的类字符串进行操作,也可以使用使用 classList 对单个类进行操作。我们选择什么取决于我们的需求。
classList 的方法:
elem.classList.add/remove(class)—— 添加/移除类。elem.classList.toggle(class)—— 如果类不存在就添加类,存在就移除它。elem.classList.contains(class)—— 检查给定类,返回true/false。
此外,classList是可迭代的
元素样式
elem.style 属性是一个对象,它对应于 "style" 特性(attribute)中所写的内容。elem.style.width="100px" 的效果等价于我们在 style 特性中有一个 width:100px 字符串。
对于多词(multi-word)属性,使用驼峰式 camelCase:
background-color => elem.style.backgroundColor
z-index => elem.style.zIndex
border-left-width => elem.style.borderLeftWidth
前缀属性
像-moz-border-radius和-webkit-border-radius这样的浏览器前缀属性,也遵循同样的规则:连字符-表示大写。
button.style.MozBorderRadius = '5px';
button.style.WebkitBorderRadius = '5px';
重置样式属性
有时我们想要分配一个样式属性,稍后移除它。
例如,为了隐藏一个元素,我们可以设置 elem.style.display = "none"。
然后,稍后我们可能想要移除 style.display,就像它没有被设置一样。这里不应该使用 delete elem.style.display,而应该使用 elem.style.display = "" 将其赋值为空。
如果我们将 style.display 设置为空字符串,那么浏览器通常会应用 CSS 类以及内建样式,就好像根本没有这样的 style.display 属性一样。
还有一个特殊的方法 elem.style.removeProperty('style property')。所以,我们可以像这样删除一个属性
document.body.style.background = 'red'; //将 background 设置为红色
setTimeout(() => document.body.style.removeProperty('background'), 1000); // 1 秒后移除 background
用
style.cssText进行完全的重写
通常,我们使用style.*来对各个样式属性进行赋值。我们不能像这样的div.style="color: red; width: 100px"设置完整的属性,因为div.style是一个对象,并且它是只读的。
想要以字符串的形式设置完整的样式,可以使用特殊属性style.cssText:
<div id="div">Button</div>
<script>
// 我们可以在这里设置特殊的样式标记,例如 "important"
div.style.cssText=`color: red !important;
background-color: yellow;
width: 100px;
text-align: center;
`;
alert(div.style.cssText);
</script>
我们很少使用这个属性,因为这样的赋值会删除所有现有样式:它不是进行添加,而是替换它们。有时可能会删除所需的内容。但是,当我们知道我们不会删除现有样式时,可以安全地将其用于新元素。
可以通过设置一个特性(attribute)来实现同样的效果:div.setAttribute('style', 'color: red...')。
注意单位
不要忘记将 CSS 单位添加到值上。
例如,我们不应该将 elem.style.top 设置为 10,而应将其设置为 10px。否则设置会无效
计算样式 getComputedStyle
修改样式很简单。但是如何 读取 样式呢?
例如,我们想知道元素的 size,margins 和 color。应该怎么获取?
style 属性仅对 "style" 特性(attribute)值起作用,而没有任何 CSS 级联(cascade)。
因此我们无法使用 elem.style 读取来自 CSS 类的任何内容。
例如,这里的 style 看不到 margin
<head>
<style> body { color: red; margin: 5px } </style>
</head>
<body>
The red text
<script>
alert(document.body.style.color); // 空的
alert(document.body.style.marginTop); // 空的
</script>
</body>
……但如果我们需要,例如,将 margin 增加 20px 呢?那么我们需要 margin 的当前值。
对于这个需求,这里有另一种方法:getComputedStyle。
语法如下:
getComputedStyle(element, [pseudo])
element
需要被读取样式值的元素。
pseudo
伪元素(如果需要),例如 ::before。空字符串或无参数则意味着元素本身。
结果是一个具有样式属性的对象,像 elem.style,但现在对于所有的 CSS 类来说都是如此。
计算值和解析值
在 CSS 中有两个概念:
- 计算 (computed) 样式值是所有 CSS 规则和 CSS 继承都应用后的值,这是 CSS 级联(cascade)的结果。它看起来像
height:1em或font-size:125%。- 解析 (resolved) 样式值是最终应用于元素的样式值。诸如
1em或125%这样的值是相对的。浏览器将使用计算(computed)值,并使所有单位均为固定的,且为绝对单位,例如:height:20px或font-size:16px。对于几何属性,解析(resolved)值可能具有浮点,例如:width:50.5px。- 很久以前,创建了
getComputedStyle来获取计算(computed)值,但事实证明,解析(resolved)值要方便得多,标准也因此发生了变化。- 所以,现在
getComputedStyle实际上返回的是属性的解析值(resolved)。
getComputedStyle需要完整的属性名
我们应该总是使用我们想要的确切的属性,例如paddingLeft、marginTop或borderTopWidth。否则,就不能保证正确的结果。
例如,如果有paddingLeft/paddingTop属性,那么对于getComputedStyle(elem).padding,我们会得到什么?什么都没有,或者是从已知的 padding 中“生成”的值?这里没有标准的规则。
应用于
:visited链接的样式被隐藏了!
可以使用 CSS 伪类:visited对被访问过的链接进行着色。
但getComputedStyle没有给出访问该颜色的方式,因为如果允许的话,任意页面都可以通过在页面上创建它,并通过检查样式来确定用户是否访问了某链接。
JavaScript 看不到:visited所应用的样式。此外,CSS 中也有一个限制,即禁止在:visited中应用更改几何形状的样式。这是为了确保一个不好的页面无法检测链接是否被访问,进而窥探隐私。
元素大小和滚动
示例元素
作为演示属性的示例元素,我们将使用下面给出的元素
<div id="example">
...Text...
</div>
<style>
#example {
width: 300px;
height: 200px;
border: 25px solid #E8C48F;
padding: 20px;
overflow: auto;
}
</style>
它有边框(border),内边距(padding)和滚动(scrolling)等全套功能。但没有外边距(margin),因为它们不是元素本身的一部分,并且它们没什么特殊的属性。
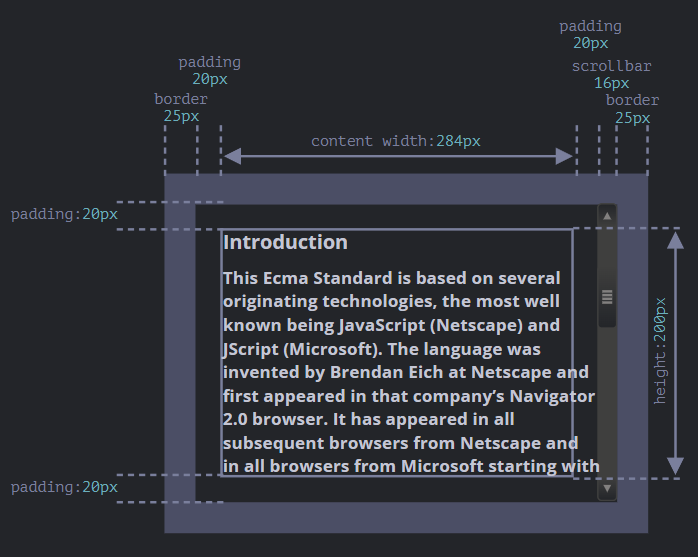
注意滚动条
上图演示了元素具有滚动条这种最复杂的情况。一些浏览器(并非全部)通过从内容(上面标记为 “content width”)中获取空间来为滚动条保留空间。
因此,如果没有滚动条,内容宽度将是300 px,但是如果滚动条宽度是16px(不同的设备和浏览器,滚动条的宽度可能有所不同),那么还剩下300 - 16 = 284px,我们应该考虑到这一点。这就是为什么本章的例子总是假设有滚动条。如果没有滚动条,一些计算会更简单。
文本可能会溢出到
padding-bottom中
在我们的插图中的 padding 中通常显示为空,但是如果元素中有很多文本,并且溢出了,那么浏览器会在padding-bottom处显示“溢出”文本,这是正常现象。
几何

这些属性的值在技术上讲是数字,但这些数字其实是“像素(pixel)”,因此它们是像素测量值。
让我们从元素外部开始探索属性。
offsetParent offsetLeft/Top
这些属性很少使用,但它们仍然是“最外面”的几何属性,所以我们将从它们开始。
offsetParent 是最接近的祖先(ancestor),在浏览器渲染期间,它被用于计算坐标。
最近的祖先为下列之一:
- CSS 定位的(
position为absolute、relative、fixed或sticky), - 或
<td>,<th>,<table>, - 或
<body>。
属性offsetLeft/offsetTop提供相对于offsetParent左上角的 x/y 坐标。
在下面这个例子中,内部的<div>有<main>作为offsetParent,并且offsetLeft/offsetTop让它从左上角位移(180):
<main style="position: relative" id="main">
<article>
<div id="example" style="position: absolute; left: 180px; top: 180px">...</div>
</article>
</main>
<script>
alert(example.offsetParent.id); // main
alert(example.offsetLeft); // 180(注意:这是一个数字,不是字符串 "180px")
alert(example.offsetTop); // 180
</script>

有以下几种情况下,
offsetParent 的值为 null:
- 对于未显示的元素(
display:none或者不在文档中)。 - 对于
<body>与<html>。 - 对于带有
position:fixed的元素。
offsetWidth/Height
现在,让我们继续关注元素本身。
这两个属性是最简单的。它们提供了元素的“外部” width/height。或者,换句话说,它的完整大小(包括边框)。

对于我们的示例元素:
offsetWidth = 390—— 外部宽度(width),可以计算为内部 CSS-width(300px)加上 padding(2 * 20px)和 border(2 * 25px)。offsetHeight = 290—— 外部高度(height)。
对于未显示的元素,几何属性为 0/null
仅针对显示的元素计算几何属性。
如果一个元素(或其任何祖先)具有display:none或不在文档中,则所有几何属性均为零(或offsetParent为null)。
例如,当我们创建了一个元素,但尚未将其插入文档中,或者它(或它的祖先)具有display:none时,offsetParent为null,并且offsetWidth和offsetHeight为0。
我们可以用它来检查一个元素是否被隐藏,像这样:
function isHidden(elem) {
return !elem.offsetWidth && !elem.offsetHeight;
}
请注意,对于会展示在屏幕上,但大小为零的元素,它们的
isHidden返回true。
clientTop/Left
在元素内部,我们有边框(border)。
为了测量它们,可以使用 clientTop 和 clientLeft。
在我们的例子中:
clientLeft = 25—— 左边框宽度clientTop = 25—— 上边框宽度
……但准确地说 —— 这些属性不是边框的 width/height,而是内侧与外侧的相对坐标。
有什么区别?
当文档从右到左显示(操作系统为阿拉伯语或希伯来语)时,影响就显现出来了。此时滚动条不在右边,而是在左边,此时clientLeft则包含了滚动条的宽度。
在这种情况下,clientLeft的值将不是25,而是加上滚动条的宽度25 + 16 = 41。

clientWidth/Height
这些属性提供了元素边框内区域的大小。
它们包括了 “content width” 和 “padding”,但不包括滚动条宽度(scrollbar):

在上图中,我们首先考虑
clientHeight。这里没有水平滚动条,所以它恰好是 border 内的总和:CSS-height
200px 加上顶部和底部的 padding(2 * 20px),总计 240px。现在
clientWidth —— 这里的 “content width” 不是 300px,而是 284px,因为被滚动条占用了 16px。所以加起来就是 284px 加上左侧和右侧的 padding,总计 324px。如果这里没有 padding,那么
clientWidth/Height 代表的就是内容区域,即 border 和 scrollbar(如果有)内的区域。
因此,当没有 padding 时,我们可以使用
clientWidth/clientHeight 来获取内容区域的大小。
scrollWidth/Height
这些属性就像 clientWidth/clientHeight,但它们还包括滚动出(隐藏)的部分

在上图中:
scrollHeight = 723—— 是内容区域的完整内部高度,包括滚动出的部分。scrollWidth = 324—— 是完整的内部宽度,这里我们没有水平滚动,因此它等于clientWidth。
我们可以使用这些属性将元素展开(expand)到整个 width/height。
// 将元素展开(expand)到完整的内容高度
element.style.height = `${element.scrollHeight}px`;
scrollLeft/scrollTop
属性 scrollLeft/scrollTop 是元素的隐藏、滚动部分的 width/height。
在下图中,我们可以看到带有垂直滚动块的 scrollHeight 和 scrollTop。

换句话说,
scrollTop 就是“已经滚动了多少”。
scrollLeft/scrollTop是可修改的
大多数几何属性是只读的,但是scrollLeft/scrollTop是可修改的,并且浏览器会滚动该元素。
如果你点击下面的元素,则会执行代码elem.scrollTop += 10。这使得元素内容向下滚动10px。
将scrollTop设置为0或一个大的值,例如1e9,将会使元素滚动到顶部/底部。
不要从css中获取width/height
我们刚刚介绍了 DOM 元素的几何属性,它们可用于获得宽度、高度和计算距离。
但是,正如我们在 样式和类 一章所知道的那样,我们可以使用 getComputedStyle 来读取 CSS-width 和 height。
那为什么不像这样用 getComputedStyle 读取元素的 width 呢?
let elem = document.body;
alert( getComputedStyle(elem).width ); // 显示 elem 的 CSS width
为什么我们应该使用几何属性呢?这里有两个原因:
- 首先,CSS
width/height取决于另一个属性:box-sizing,它定义了“什么是” CSS 宽度和高度。出于 CSS 的目的而对box-sizing进行的更改可能会破坏此类 JavaScript 操作。 - 其次,CSS 的
width/height可能是auto,例如内联(inline)元素:
从 CSS 的观点来看,width:auto是完全正常的,但在 JavaScript 中,我们需要一个确切的px大小,以便我们在计算中使用它。因此,这里的 CSS 宽度没什么用。
还有另一个原因:滚动条。有时,在没有滚动条的情况下代码工作正常,当出现滚动条时,代码就出现了 bug,因为在某些浏览器中,滚动条会占用内容的空间。因此,可用于内容的实际宽度小于 CSS 宽度。而 clientWidth/clientHeight 则会考虑到这一点。
……但是,使用 getComputedStyle(elem).width 时,情况就不同了。某些浏览器(例如 Chrome)返回的是实际内部宽度减去滚动条宽度,而某些浏览器(例如 Firefox)返回的是 CSS 宽度(忽略了滚动条)。这种跨浏览器的差异是不使用 getComputedStyle 而依靠几何属性的原因。
在桌面 Windows 操作系统上,Firefox、Chrome、Edge 都为滚动条保留了空间。但 Firefox 显示的是 300px,而 Chrome 和 Edge 显示较少。这是因为 Firefox 返回 CSS 宽度,其他浏览器返回“真实”宽度。
请注意,所描述的差异只是关于从 JavaScript 读取的 getComputedStyle(...).width,而视觉上看,一切都是正确的。
Window 大小和滚动
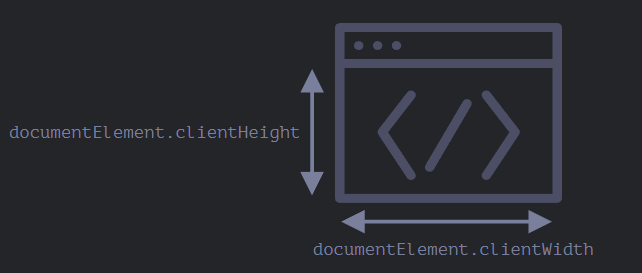
窗口的 width/height
document.documentElement.clientWidth/clientHeight
不是
window.innerWidth/innerHeight
浏览器也支持像window.innerWidth/innerHeight这样的属性。它们看起来像我们想要的,那为什么不使用它们呢?
如果这里存在一个滚动条,并且滚动条占用了一些空间,那么clientWidth/clientHeight会提供没有滚动条(减去它)的 width/height。换句话说,它们返回的是可用于内容的文档的可见部分的 width/height。
window.innerWidth/innerHeight包括了滚动条。
DOCTYPE很重要
请注意:当 HTML 中没有<!DOCTYPE HTML>时,顶层级(top-level)几何属性的工作方式可能就会有所不同。可能会出现一些稀奇古怪的情况。
在现代 HTML 中,我们始终都应该写DOCTYPE。
文档的 width/height
document.documentElement.scrollWidth/scrollHeight
从理论上讲,由于根文档元素是 document.documentElement,并且它包围了所有内容,因此我们可以通过使用 documentElement.scrollWidth/scrollHeight 来测量文档的完整大小。
但是在该元素上,对于整个文档,这些属性均无法正常工作。在 Chrome/Safari/Opera 中,如果没有滚动条,documentElement.scrollHeight 甚至可能小于 documentElement.clientHeight!很奇怪,对吧?
为了可靠地获得完整的文档高度,我们应该采用以下这些属性的最大值:
let scrollHeight = Math.max(
document.body.scrollHeight,
document.documentElement.scrollHeight,
document.body.offsetHeight,
document.documentElement.offsetHeight,
document.body.clientHeight,
document.documentElement.clientHeight
);
alert('Full document height, with scrolled out part: ' + scrollHeight);
为什么这样?最好不要问。这些不一致来源于远古时代,而不是“聪明”的逻辑。
获得当前滚动
DOM 元素的当前滚动状态在其 scrollLeft/scrollTop 属性中。
对于文档滚动,在大多数浏览器中,我们可以使用 document.documentElement.scrollLeft/scrollTop,但在较旧的基于 WebKit 的浏览器中则不行,例如在 Safari(bug 5991)中,我们应该使用 document.body 而不是 document.documentElement。
幸运的是,我们根本不必记住这些特性,因为我们可以从 window.pageXOffset/pageYOffset 中获取页面当前滚动
这些属性是只读的。
我们也可以从
window的scrollX和scrollY属性中获取滚动信息
由于历史原因,存在了这两种属性,但它们是一样的:
window.pageXOffset是window.scrollX的别名。window.pageYOffset是window.scrollY的别名。
滚动:scrollTO, scrollBy, scrollIntoView
重要:
必须在 DOM 完全构建好之后才能通过 JavaScript 滚动页面。
例如,如果我们尝试通过<head>中的脚本滚动页面,它将无法正常工作。
可以通过更改 scrollTop/scrollLeft 来滚动常规元素。
我们可以使用 document.documentElement.scrollTop/scrollLeft 对页面进行相同的操作(Safari 除外,而应该使用 document.body.scrollTop/Left 代替)。
或者,有一个更简单的通用解决方案:使用特殊方法 window.scrollBy(x,y) 和 window.scrollTo(pageX,pageY)。
- 方法
scrollBy(x,y)将页面滚动至 相对于当前位置的(x, y)位置。例如,scrollBy(0,10)会将页面向下滚动10px。 - 方法
scrollTo(pageX,pageY)将页面滚动至 绝对坐标,使得可见部分的左上角具有相对于文档左上角的坐标(pageX, pageY)。就像设置了scrollLeft/scrollTop一样。
为了完整起见,让我们再介绍一种方法:elem.scrollIntoView(top)。
对 elem.scrollIntoView(top) 的调用将滚动页面以使 elem 可见。它有一个参数:
- 如果
top=true(默认值),页面滚动,使elem出现在窗口顶部。元素的上边缘将与窗口顶部对齐。 - 如果
top=false,页面滚动,使elem出现在窗口底部。元素的底部边缘将与窗口底部对齐。
禁止滚动
有时候我们需要使文档“不可滚动”。例如,当我们需要用一条需要立即引起注意的大消息来覆盖文档时,我们希望访问者与该消息而不是与文档进行交互。
要使文档不可滚动,只需要设置 document.body.style.overflow = "hidden"。该页面将“冻结”在其当前滚动位置上。
我们还可以使用相同的技术来冻结其他元素的滚动,而不仅仅是 document.body。
这个方法的缺点是会使滚动条消失。如果滚动条占用了一些空间,它原本占用的空间就会空出来,那么内容就会“跳”进去以填充它。
这看起来有点奇怪,但是我们可以对比冻结前后的 clientWidth。如果它增加了(滚动条消失后),那么我们可以在 document.body 中滚动条原来的位置处通过添加 padding,来替代滚动条,这样这个问题就解决了。保持了滚动条冻结前后文档内容宽度相同。
坐标
要移动页面的元素,我们应该先熟悉坐标。
大多数 JavaScript 方法处理的是以下两种坐标系中的一个:
- 相对于窗口 —— 类似于
position:fixed,从窗口的顶部/左侧边缘计算得出。- 我们将这些坐标表示为
clientX/clientY,当我们研究事件属性时,就会明白为什么使用这种名称来表示坐标。
- 我们将这些坐标表示为
- 相对于文档 —— 与文档根(document root)中的
position:absolute类似,从文档的顶部/左侧边缘计算得出。- 我们将它们表示为
pageX/pageY。
当页面滚动到最开始时,此时窗口的左上角恰好是文档的左上角,它们的坐标彼此相等。但是,在文档移动之后,元素的窗口相对坐标会发生变化,因为元素在窗口中移动,而元素在文档中的相对坐标保持不变。
在下图中,我们在文档中取一点,并演示了它滚动之前(左)和之后(右)的坐标:
 当文档滚动了:
当文档滚动了:
- 我们将它们表示为
pageY—— 元素在文档中的相对坐标保持不变,从文档顶部(现在已滚动出去)开始计算。clientY—— 窗口相对坐标确实发生了变化(箭头变短了),因为同一个点越来越靠近窗口顶部。
元素坐标 getBoundingClientRect
方法 elem.getBoundingClientRect() 返回最小矩形的窗口坐标,该矩形将 elem 作为内建 DOMRect 类的对象。
主要的 DOMRect 属性:
x/y—— 矩形原点相对于窗口的 X/Y 坐标,width/height—— 矩形的 width/height(可以为负)。
此外,还有派生(derived)属性:top/bottom—— 顶部/底部矩形边缘的 Y 坐标,left/right—— 左/右矩形边缘的 X 坐标。
正如你所看到的,x/y和width/height对矩形进行了完整的描述。可以很容易地从它们计算出派生(derived)属性:left = xtop = yright = x + widthbottom = y + height
请注意:- 坐标可能是小数,例如
10.5。这是正常的,浏览器内部使用小数进行计算。在设置style.left/top时,我们不是必须对它们进行舍入。 - 坐标可能是负数。例如滚动页面,使
elem现在位于窗口的上方,则elem.getBoundingClientRect().top为负数。

为什么需要派生(derived)属性?如果有了
x/y,为什么还要还会存在top/left?
从数学上讲,一个矩形是使用其起点(x,y)和方向向量(width,height)唯一定义的。因此,其它派生属性是为了方便起见。
从技术上讲,width/height可能为负数,从而允许“定向(directed)”矩形,例如代表带有正确标记的开始和结束的鼠标选择。
负的width/height值表示矩形从其右下角开始,然后向左上方“增长”。
这是一个矩形,其width和height均为负数(例如width=-200,height=-100):
正如你所看到的,在这个例子中,left/top与x/y不相等。
但是实际上,elem.getBoundingClientRect()总是返回正数的 width/height,这里我们提及负的width/height只是为了帮助你理解,为什么这些看起来重复的属性,实际上并不是重复的。

IE 浏览器不支持
x/y
由于历史原因,IE 浏览器不支持x/y属性。
因此,我们可以写一个 polyfill(在DomRect.prototype中添加一个 getter),或者仅使用top/left,因为对于正值的width/height来说,它们和x/y一直是一样的,尤其是对于elem.getBoundingClientRect()的结果。
坐标的 right/bottom 与 CSS position 属性不同
相对于窗口(window)的坐标和 CSSposition:fixed之间有明显的相似之处。
但是在 CSS 定位中,right属性表示距右边缘的距离,而bottom属性表示距下边缘的距离。
如果我们再看一下上面的图片,我们可以看到在 JavaScript 中并非如此。窗口的所有坐标都从左上角开始计数,包括这些坐标。
elementFromPoint(x, y)
对 document.elementFromPoint(x, y) 的调用会返回在窗口坐标 (x, y) 处嵌套最多(the most nested)的元素。
下面的代码会高亮显示并输出现在位于窗口中间的元素的标签:
let centerX = document.documentElement.clientWidth / 2;
let centerY = document.documentElement.clientHeight / 2;
let elem = document.elementFromPoint(centerX, centerY);
elem.style.background = "red";
alert(elem.tagName);
因为它使用的是窗口坐标,所以元素可能会因当前滚动位置而有所不同。
对于在窗口之外的坐标,
elementFromPoint返回null
方法document.elementFromPoint(x,y)只对在可见区域内的坐标(x,y)起作用。
如果任何坐标为负或者超过了窗口的 width/height,那么该方法就会返回null。
在大多数情况下,这种行为并不是一个问题,但是我们应该记住这一点。
用于 fixed 定位
大多数时候,我们需要使用坐标来确定某些内容的位置。
想要在某元素附近展示内容,我们可以使用 getBoundingClientRect 来获取这个元素的坐标,然后使用 CSS position 以及 left/top(或 right/bottom)。
我们可以修改代码以在元素左侧,右侧或下面显示消息,也可以应用 CSS 动画来营造“淡入淡出”效果等。这很简单,因为我们有该元素所有坐标和大小。
但是请注意一个重要的细节:滚动页面时,消息就会从按钮流出。
原因很显然:message 元素依赖于 position:fixed,因此当页面滚动时,它仍位于窗口的同一位置。
要改变这一点,我们需要使用基于文档(document)的坐标和 position:absolute 样式。
文档坐标
文档相对坐标从文档的左上角开始计算,而不是窗口。
在 CSS 中,窗口坐标对应于 position:fixed,而文档坐标与顶部的 position:absolute 类似。
我们可以使用 position:absolute 和 top/left 来把某些内容放到文档中的某个位置,以便在页面滚动时,元素仍能保留在该位置。但是我们首先需要正确的坐标。
这里没有标准方法来获取元素的文档坐标。但是写起来很容易。
这两个坐标系统通过以下公式相连接:
pageY=clientY+ 文档的垂直滚动出的部分的高度。pageX=clientX+ 文档的水平滚动出的部分的宽度。