Fetch
JavaScript 可以将网络请求发送到服务器,并在需要时加载新信息。
例如,我们可以使用网络请求来:
- 提交订单,
- 加载用户信息,
- 从服务器接收最新的更新,
- ……等。
……所有这些都没有重新加载页面!
对于来自 JavaScript 的网络请求,有一个总称术语 “AJAX”(Asynchronous JavaScript And XML 的简称)。但是,我们不必使用 XML:这个术语诞生于很久以前,所以这个词一直在那儿。
有很多方式可以向服务器发送网络请求,并从服务器获取信息。
fetch()方法是一种现代通用的方法,那么我们就从它开始吧。旧版本的浏览器不支持它(可以 polyfill),但是它在现代浏览器中的支持情况很好。
基本语法:
let promise = fetch(url, [options])
url—— 要访问的 URL。options—— 可选参数:method,header 等。
没有options,这就是一个简单的 GET 请求,下载url的内容。
浏览器立即启动请求,并返回一个该调用代码应该用来获取结果的promise。
获取响应通常需要经过两个阶段。
第一阶段,当服务器发送了响应头(response header),fetch返回的promise就使用内建的 Response class 对象来对响应头进行解析。
在这个阶段,我们可以通过检查响应头,来检查 HTTP 状态以确定请求是否成功,当前还没有响应体(response body)。
如果fetch无法建立一个 HTTP 请求,例如网络问题,亦或是请求的网址不存在,那么 promise 就会 reject。异常的 HTTP 状态,例如 404 或 500,不会导致出现 error。
我们可以在 response 的属性中看到 HTTP 状态:status—— HTTP 状态码,例如 200。ok—— 布尔值,如果 HTTP 状态码为 200-299,则为true。
let response = await fetch(url);
if (response.ok) { // 如果 HTTP 状态码为 200-299
// 获取 response body(此方法会在下面解释)
let json = await response.json();
} else {
alert("HTTP-Error: " + response.status);
}
第二阶段,为了获取 response body,我们需要使用一个其他的方法调用。
Response 提供了多种基于 promise 的方法,来以不同的格式访问 body:
response.text()—— 读取 response,并以文本形式返回 response,response.json()—— 将 response 解析为 JSON 格式,response.formData()—— 以FormData对象(在 下一章 有解释)的形式返回 response,response.blob()—— 以 Blob(具有类型的二进制数据)形式返回 response,response.arrayBuffer()—— 以 ArrayBuffer(低级别的二进制数据)形式返回 response,- 另外,
response.body是 ReadableStream 对象,它允许你逐块读取 body,我们稍后会用一个例子解释它。
例如,我们从 GitHub 获取最新 commits 的 JSON 对象:
let url = 'https://api.github.com/repos/javascript-tutorial/en.javascript.info/commits';
let response = await fetch(url);
let commits = await response.json(); // 读取 response body,并将其解析为 JSON 格式
alert(commits[0].author.login);
也可以使用纯 promise 语法,不使用 await:
fetch('https://api.github.com/repos/javascript-tutorial/en.javascript.info/commits')
.then(response => response.json())
.then(commits => alert(commits[0].author.login));
要获取响应文本,可以使用 await response.text() 代替 .json():
let response = await fetch('https://api.github.com/repos/javascript-tutorial/en.javascript.info/commits');
let text = await response.text(); // 将 response body 读取为文本
alert(text.slice(0, 80) + '...');
作为一个读取为二进制格式的演示示例,让我们 fetch 并显示一张 “fetch” 规范 中的图片(Blob 操作的有关内容请见 Blob):
let response = await fetch('/article/fetch/logo-fetch.svg');
let blob = await response.blob(); // 下载为 Blob 对象
// 为其创建一个 <img>
let img = document.createElement('img');
img.style = 'position:fixed;top:10px;left:10px;width:100px';
document.body.append(img);
// 显示它
img.src = URL.createObjectURL(blob);
setTimeout(() => { // 3 秒后将其隐藏
img.remove();
URL.revokeObjectURL(img.src);
}, 3000);
重要:
我们只能选择一种读取 body 的方法。
如果我们已经使用了response.text()方法来获取 response,那么如果再用response.json(),则不会生效,因为 body 内容已经被处理过了。
let text = await response.text(); // response body 被处理了
let parsed = await response.json(); // 失败(已经被处理过了)
Response header
Response header 位于 response.headers 中的一个类似于 Map 的 header 对象。
它不是真正的 Map,但是它具有类似的方法,我们可以按名称(name)获取各个 header,或迭代它们:
let response = await fetch('https://api.github.com/repos/javascript-tutorial/en.javascript.info/commits');
// 获取一个 header
alert(response.headers.get('Content-Type')); // application/json; charset=utf-8
// 迭代所有 header
for (let [key, value] of response.headers) {
alert(`${key} = ${value}`);
}
Request header
要在 fetch 中设置 request header,我们可以使用 headers 选项。它有一个带有输出 header 的对象,如下所示:
let response = fetch(protectedUrl, {
headers: {
Authentication: 'secret'
}
});
……但是有一些我们无法设置的 header(详见 forbidden HTTP headers):
Accept-Charset,Accept-EncodingAccess-Control-Request-HeadersAccess-Control-Request-MethodConnectionContent-LengthCookie,Cookie2DateDNTExpectHostKeep-AliveOriginRefererTETrailerTransfer-EncodingUpgradeViaProxy-*Sec-*
这些 header 保证了 HTTP 的正确性和安全性,所以它们仅由浏览器控制。
POST 请求
要创建一个 POST 请求,或者其他方法的请求,我们需要使用 fetch 选项:
method—— HTTP 方法,例如POST,body—— request body,其中之一:- 字符串(例如 JSON 编码的),
FormData对象,以multipart/form-data形式发送数据,Blob/BufferSource发送二进制数据,- URLSearchParams,以
x-www-form-urlencoded编码形式发送数据,很少使用。
JSON 形式是最常用的。
例如,下面这段代码以 JSON 形式发送user对象:
let user = {
name: 'John',
surname: 'Smith'
};
let response = await fetch('/article/fetch/post/user', {
method: 'POST',
headers: {
'Content-Type': 'application/json;charset=utf-8'
},
body: JSON.stringify(user)
});
let result = await response.json();
alert(result.message);
请注意,如果请求的 body 是字符串,则 Content-Type 会默认设置为 text/plain;charset=UTF-8。
但是,当我们要发送 JSON 时,我们会使用 headers 选项来发送 application/json,这是 JSON 编码的数据的正确的 Content-Type。
发送图片
我们同样可以使用 Blob 或 BufferSource 对象通过 fetch 提交二进制数据。
例如,这里有一个 <canvas>,我们可以通过在其上移动鼠标来进行绘制。点击 “submit” 按钮将图片发送到服务器:
<body style="margin:0">
<canvas id="canvasElem" width="100" height="80" style="border:1px solid"></canvas>
<input type="button" value="Submit" onclick="submit()">
<script>
canvasElem.onmousemove = function(e) {
let ctx = canvasElem.getContext('2d');
ctx.lineTo(e.clientX, e.clientY);
ctx.stroke();
};
async function submit() {
let blob = await new Promise(resolve => canvasElem.toBlob(resolve, 'image/png'));
let response = await fetch('/article/fetch/post/image', {
method: 'POST',
body: blob
});
// 服务器给出确认信息和图片大小作为响应
let result = await response.json();
alert(result.message);
}
</script>
</body>
请注意,这里我们没有手动设置 Content-Type header,因为 Blob 对象具有内建的类型(这里是 image/png,通过 toBlob 生成的)。对于 Blob 对象,这个类型就变成了 Content-Type 的值。
可以在不使用 async/await 的情况下重写 submit() 函数,像这样:
function submit() {
canvasElem.toBlob(function(blob) {
fetch('/article/fetch/post/image', {
method: 'POST',
body: blob
})
.then(response => response.json())
.then(result => alert(JSON.stringify(result, null, 2)))
}, 'image/png');
}
FormData
这一章是关于发送 HTML 表单的:带有或不带文件,带有其他字段等。
FormData 对象可以提供帮助。你可能已经猜到了,它是表示 HTML 表单数据的对象。
构造函数是:
let formData = new FormData([form]);
如果提供了 HTML form 元素,它会自动捕获 form 元素字段。
FormData 的特殊之处在于网络方法(network methods),例如 fetch 可以接受一个 FormData 对象作为 body。它会被编码并发送出去,带有 Content-Type: multipart/form-data。
从服务器角度来看,它就像是一个普通的表单提交。
发送一个简单的表单
我们先来发送一个简单的表单。
正如你所看到的,它几乎就是一行代码:
<form id="formElem">
<input type="text" name="name" value="John">
<input type="text" name="surname" value="Smith">
<input type="submit">
</form>
<script>
formElem.onsubmit = async (e) => {
e.preventDefault();
let response = await fetch('/article/formdata/post/user', {
method: 'POST',
body: new FormData(formElem)
});
let result = await response.json();
alert(result.message);
};
</script>
服务器接受 POST 请求并回应 “User saved”。
FormData 方法
我们可以使用以下方法修改 FormData 中的字段:
formData.append(name, value)—— 添加具有给定name和value的表单字段,formData.append(name, blob, fileName)—— 添加一个字段,就像它是<input type="file">,第三个参数fileName设置文件名(而不是表单字段名),因为它是用户文件系统中文件的名称,formData.delete(name)—— 移除带有给定name的字段,formData.get(name)—— 获取带有给定name的字段值,formData.has(name)—— 如果存在带有给定name的字段,则返回true,否则返回false。
从技术上来讲,一个表单可以包含多个具有相同name的字段,因此,多次调用append将会添加多个具有相同名称的字段。
还有一个set方法,语法与append相同。不同之处在于.set移除所有具有给定name的字段,然后附加一个新字段。因此,它确保了只有一个具有这种name的字段,其他的和append一样:formData.set(name, value),formData.set(name, blob, fileName)。
我们也可以使用for..of循环迭代 formData 字段:
let formData = new FormData();
formData.append('key1', 'value1');
formData.append('key2', 'value2');
// 列出 key/value 对
for(let [name, value] of formData) {
alert(`${name} = ${value}`); // key1 = value1,然后是 key2 = value2
}
发送带有文件的表单
表单始终以 Content-Type: multipart/form-data 来发送数据,这个编码允许发送文件。因此 <input type="file"> 字段也能被发送,类似于普通的表单提交。
这是具有这种形式的示例:
<form id="formElem">
<input type="text" name="firstName" value="John">
Picture: <input type="file" name="picture" accept="image/*">
<input type="submit">
</form>
<script>
formElem.onsubmit = async (e) => {
e.preventDefault();
let response = await fetch('/article/formdata/post/user-avatar', {
method: 'POST',
body: new FormData(formElem)
});
let result = await response.json();
alert(result.message);
};
</script>
发送具有 Blob 数据的表单
正如我们在 Fetch 一章中所看到的,以 Blob 发送一个动态生成的二进制数据,例如图片,是很简单的。我们可以直接将其作为 fetch 参数的 body。
但在实际中,通常更方便的发送图片的方式不是单独发送,而是将其作为表单的一部分,并带有附加字段(例如 “name” 和其他 metadata)一起发送。
并且,服务器通常更适合接收多部分编码的表单(multipart-encoded form),而不是原始的二进制数据。
下面这个例子使用 FormData 将一个来自 <canvas> 的图片和一些其他字段一起作为一个表单提交:
<body style="margin:0">
<canvas id="canvasElem" width="100" height="80" style="border:1px solid"></canvas>
<input type="button" value="Submit" onclick="submit()">
<script>
canvasElem.onmousemove = function(e) {
let ctx = canvasElem.getContext('2d');
ctx.lineTo(e.clientX, e.clientY);
ctx.stroke();
};
async function submit() {
let imageBlob = await new Promise(resolve => canvasElem.toBlob(resolve, 'image/png'));
let formData = new FormData();
formData.append("firstName", "John");
formData.append("image", imageBlob, "image.png");
let response = await fetch('/article/formdata/post/image-form', {
method: 'POST',
body: formData
});
let result = await response.json();
alert(result.message);
}
</script>
</body>
请注意图片 Blob 是如何添加的
formData.append("image", imageBlob, "image.png");
就像表单中有 <input type="file" name="image"> 一样,用户从他们的文件系统中使用数据 imageBlob(第二个参数)提交了一个名为 image.png(第三个参数)的文件。
服务器读取表单数据和文件,就好像它是常规的表单提交一样。
Fetch 下载进度
fetch 方法允许去跟踪 下载 进度。
请注意:到目前为止,fetch 方法无法跟踪 上传 进度。对于这个目的,请使用 XMLHttpRequest,我们在后面章节会讲到。
要跟踪下载进度,我们可以使用 response.body 属性。它是 ReadableStream —— 一个特殊的对象,它可以逐块(chunk)提供 body。在 Streams API 规范中有对 ReadableStream 的详细描述。
与 response.text(),response.json() 和其他方法不同,response.body 给予了对进度读取的完全控制,我们可以随时计算下载了多少。
这是从 response.body 读取 response 的示例代码:
// 代替 response.json() 以及其他方法
const reader = response.body.getReader();
// 在 body 下载时,一直为无限循环
while(true) {
// 当最后一块下载完成时,done 值为 true
// value 是块字节的 Uint8Array
const {done, value} = await reader.read();
if (done) {
break;
}
console.log(`Received ${value.length} bytes`)
}
await reader.read() 调用的结果是一个具有两个属性的对象:
done—— 当读取完成时为true,否则为false。value—— 字节的类型化数组:Uint8Array。
请注意:
Streams API 还描述了如果使用for await..of循环异步迭代ReadableStream,但是目前为止,它还未得到很好的支持(参见 浏览器问题),所以我们使用了while循环。
我们在循环中接收响应块(response chunk),直到加载完成,也就是:直到 done 为 true。
要将进度打印出来,我们只需要将每个接收到的片段 value 的长度(length)加到 counter 即可。
这是获取响应,并在控制台中记录进度的完整工作示例,下面有更多说明:
// Step 1:启动 fetch,并获得一个 reader
let response = await fetch('https://api.github.com/repos/javascript-tutorial/en.javascript.info/commits?per_page=100');
const reader = response.body.getReader();
// Step 2:获得总长度(length)
const contentLength = +response.headers.get('Content-Length');
// Step 3:读取数据
let receivedLength = 0; // 当前接收到了这么多字节
let chunks = []; // 接收到的二进制块的数组(包括 body)
while(true) {
const {done, value} = await reader.read();
if (done) {
break;
}
chunks.push(value);
receivedLength += value.length;
console.log(`Received ${receivedLength} of ${contentLength}`)
}
// Step 4:将块连接到单个 Uint8Array
let chunksAll = new Uint8Array(receivedLength); // (4.1)
let position = 0;
for(let chunk of chunks) {
chunksAll.set(chunk, position); // (4.2)
position += chunk.length;
}
// Step 5:解码成字符串
let result = new TextDecoder("utf-8").decode(chunksAll);
// 我们完成啦!
let commits = JSON.parse(result);
alert(commits[0].author.login);
让我们一步步解释下这个过程:
- 我们像往常一样执行
fetch,但不是调用response.json(),而是获得了一个流读取器(stream reader)response.body.getReader()。
请注意,我们不能同时使用这两种方法来读取相同的响应。要么使用流读取器,要么使用 reponse 方法来获取结果。 - 在读取数据之前,我们可以从
Content-Lengthheader 中得到完整的响应长度。
跨源请求中可能不存在这个 header(请参见 Fetch:跨源请求),并且从技术上讲,服务器可以不设置它。但是通常情况下它都会在那里。 - 调用
await reader.read(),直到它完成。
我们将响应块收集到数组chunks中。这很重要,因为在使用完(consumed)响应后,我们将无法使用response.json()或者其他方式(你可以试试,将会出现 error)去“重新读取”它。 - 最后,我们有了一个
chunks—— 一个Uint8Array字节块数组。我们需要将这些块合并成一个结果。但不幸的是,没有单个方法可以将它们串联起来,所以这里需要一些代码来实现:- 我们创建
chunksAll = new Uint8Array(receivedLength)—— 一个具有所有数据块合并后的长度的同类型数组。 - 然后使用
.set(chunk, position)方法,从数组中一个个地复制这些chunk。
- 我们创建
- 我们的结果现在储存在
chunksAll中。但它是一个字节数组,不是字符串。
要创建一个字符串,我们需要解析这些字节。可以使用内建的 TextDecoder 对象完成。然后,我们可以JSON.parse它,如果有必要的话。
如果我们需要的是二进制内容而不是字符串呢?这更简单。用下面这行代码替换掉第 4 和第 5 步,这行代码从所有块创建一个Blob:
let blob = new Blob(chunks);
最后,我们得到了结果(以字符串或 blob 的形式表示,什么方便就用什么),并在过程中对进度进行了跟踪。
再强调一遍,这不能用于 上传 过程(现在无法通过 fetch 获取),仅用于 下载 过程。
另外,如果大小未知,我们应该检查循环中的 receivedLength,一旦达到一定的限制就将其中断。这样 chunks 就不会溢出内存了。
Fetch: 中止(Abort)
正如我们所知道的,fetch 返回一个 promise。JavaScript 通常并没有“中止” promise 的概念。那么我们怎样才能取消一个正在执行的 fetch 呢?例如,如果用户在我们网站上的操作表明不再需要某个执行中的 fetch。
为此有一个特殊的内建对象:AbortController。它不仅可以中止 fetch,还可以中止其他异步任务。
用法非常简单。
AbortController 对象
创建一个控制器(controller):
let controller = new AbortController();
控制器是一个极其简单的对象。
- 它具有单个方法
abort(), - 和单个属性
signal,我们可以在这个属性上设置事件监听器。
当abort()被调用时: controller.signal就会触发abort事件。controller.signal.aborted属性变为true。
通常,我们需要处理两部分:
- 一部分是通过在
controller.signal上添加一个监听器,来执行可取消操作。 - 另一部分是触发取消:在需要的时候调用
controller.abort()。
这是完整的示例(目前还没有fetch):
let controller = new AbortController();
let signal = controller.signal;
// 执行可取消操作部分
// 获取 "signal" 对象,
// 并将监听器设置为在 controller.abort() 被调用时触发
signal.addEventListener('abort', () => alert("abort!"));
// 另一部分,取消(在之后的任何时候):
controller.abort(); // 中止!
// 事件触发,signal.aborted 变为 true
alert(signal.aborted); // true
正如我们所看到的,AbortController 只是在 abort() 被调用时传递 abort 事件的一种方式。
我们可以自己在代码中实现相同类型的事件监听,而不需要 AbortController 对象。
但是有价值的是,fetch 知道如何与 AbortController 对象一起工作。它们是集成在一起的。
与 fetch 一起使用
为了能够取消 fetch,请将 AbortController 的 signal 属性作为 fetch 的一个可选参数(option)进行传递:
let controller = new AbortController();
fetch(url, {
signal: controller.signal
});
fetch 方法知道如何与 AbortController 一起工作。它会监听 signal 上的 abort 事件。
现在,想要中止 fetch,调用 controller.abort() 即可:
controller.abort();
我们完成啦:fetch 从 signal 获取了事件并中止了请求。
当一个 fetch 被中止,它的 promise 就会以一个 error AbortError reject,因此我们应该对其进行处理,例如在 try..catch 中。
这是完整的示例,其中 fetch 在 1 秒后中止:
// 1 秒后中止
let controller = new AbortController();
setTimeout(() => controller.abort(), 1000);
try {
let response = await fetch('/article/fetch-abort/demo/hang', {
signal: controller.signal
});
} catch(err) {
if (err.name == 'AbortError') { // handle abort()
alert("Aborted!");
} else {
throw err;
}
}
AbortController 是可伸缩的
AbortController 是可伸缩的。它允许一次取消多个 fetch。
这是一个代码草稿,该代码并行 fetch 很多 urls,并使用单个控制器将其全部中止:
let urls = [...]; // 要并行 fetch 的 url 列表
let controller = new AbortController();
// 一个 fetch promise 的数组
let fetchJobs = urls.map(url => fetch(url, {
signal: controller.signal
}));
let results = await Promise.all(fetchJobs);
// controller.abort() 被从任何地方调用,
// 它都将中止所有 fetch
如果我们有自己的与 fetch 不同的异步任务,我们可以使用单个 AbortController 中止这些任务以及 fetch。
在我们的任务中,我们只需要监听其 abort 事件:
let urls = [...];
let controller = new AbortController();
let ourJob = new Promise((resolve, reject) => { // 我们的任务
...
controller.signal.addEventListener('abort', reject);
});
let fetchJobs = urls.map(url => fetch(url, { // fetches
signal: controller.signal
}));
// 等待完成我们的任务和所有 fetch
let results = await Promise.all([...fetchJobs, ourJob]);
// controller.abort() 被从任何地方调用,
// 它都将中止所有 fetch 和 ourJob
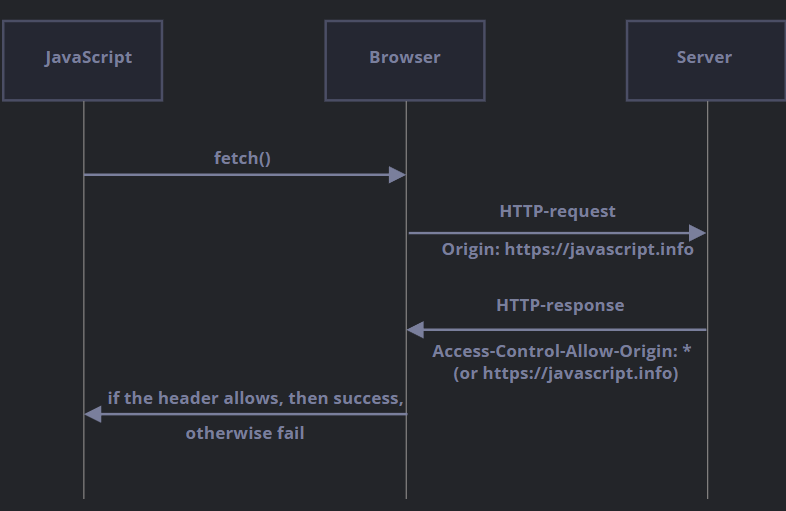
Fetch: 跨源请求
如果我们向另一个网站发送 fetch 请求,则该请求可能会失败。
例如,让我们尝试向 http://example.com 发送 fetch 请求:
try {
await fetch('http://example.com');
} catch(err) {
alert(err); // fetch 失败
}
正如所料,获取失败。
这里的核心概念是 源(origin)—— 域(domain)/端口(port)/协议(protocol)的组合。
跨源请求 —— 那些发送到其他域(即使是子域)、协议或端口的请求 —— 需要来自远程端的特殊 header。
这个策略被称为 “CORS”:跨源资源共享(Cross-Origin Resource Sharing)。
为什么需要 CORS? 跨源请求简史
CORS 的存在是为了保护互联网免受黑客攻击。
说真的,在这说点儿题外话,讲讲它的历史。
多年来,来自一个网站的脚本无法访问另一个网站的内容。
这个简单有力的规则是互联网安全的基础。例如,来自 hacker.com 的脚本无法访问 gmail.com 上的用户邮箱。基于这样的规则,人们感到很安全。
在那时候,JavaScript 并没有任何特殊的执行网络请求的方法。它只是一种用来装饰网页的玩具语言而已。
但是 Web 开发人员需要更多功能。人们发明了各种各样的技巧去突破该限制,并向其他网站发出请求。
使用表单
其中一种和其他服务器通信的方法是在那里提交一个 <form>。人们将它提交到 <iframe>,只是为了停留在当前页面,像这样:
<!-- 表单目标 -->
<iframe name="iframe"></iframe>
<!-- 表单可以由 JavaScript 动态生成并提交 -->
<form target="iframe" method="POST" action="http://another.com/…">
...
</form>
因此,即使没有网络方法,也可以向其他网站发出 GET/POST 请求,因为表单可以将数据发送到任何地方。但是由于禁止从其他网站访问 <iframe> 中的内容,因此就无法读取响应。
确切地说,实际上有一些技巧能够解决这个问题,这在 iframe 和页面中都需要添加特殊脚本。因此,与 iframe 的通信在技术上是可能的。现在我们没必要讲其细节内容,我们还是让这些古董代码不要再出现了吧。
使用 script
另一个技巧是使用 script 标签。script 可以具有任何域的 src,例如 <script src="http://another.com/…">。也可以执行来自任何网站的 script。
如果一个网站,例如 another.com 试图公开这种访问方式的数据,则会使用所谓的 “JSONP (JSON with padding)” 协议。
这是它的工作方式。
假设在我们的网站,需要以这种方式从 http://another.com 网站获取数据,例如天气:
- 首先,我们先声明一个全局函数来接收数据,例如
gotWeather。
// 1. 声明处理天气数据的函数
function gotWeather({ temperature, humidity }) {
alert(`temperature: ${temperature}, humidity: ${humidity}`);
}
- 然后我们创建一个特性(attribute)为
src="http://another.com/weather.json?callback=gotWeather"的<script>标签,使用我们的函数名作为它的callbackURL-参数。
let script = document.createElement('script');
script.src = `http://another.com/weather.json?callback=gotWeather`;
document.body.append(script);
- 远程服务器
another.com动态生成一个脚本,该脚本调用gotWeather(...),发送它想让我们接收的数据。
// 我们期望来自服务器的回答看起来像这样:
gotWeather({
temperature: 25,
humidity: 78
});
- 当远程脚本加载并执行时,
gotWeather函数将运行,并且因为它是我们的函数,我们就有了需要的数据。
这是可行的,并且不违反安全规定,因为双方都同意以这种方式传递数据。而且,既然双方都同意这种行为,那这肯定不是黑客攻击了。现在仍然有提供这种访问的服务,因为即使是非常旧的浏览器它依然适用。
不久之后,网络方法出现在了浏览器 JavaScript 中。
起初,跨源请求是被禁止的。但是,经过长时间的讨论,跨源请求被允许了,但是任何新功能都需要服务器明确允许,以特殊的 header 表述。
安全请求
有两种类型的跨源请求:
- 安全请求。
- 所有其他请求。
安全请求很简单,所以我们先从它开始。
如果一个请求满足下面这两个条件,则该请求是安全的: - 安全的方法:GET,POST 或 HEAD
- 安全的 header —— 仅允许自定义下列 header:
Accept,Accept-Language,Content-Language,Content-Type的值为application/x-www-form-urlencoded,multipart/form-data或text/plain。
任何其他请求都被认为是“非安全”请求。例如,具有PUT方法或API-KeyHTTP-header 的请求就不是安全请求。
本质区别在于,可以使用<form>或<script>进行安全请求,而无需任何其他特殊方法。
因此,即使是非常旧的服务器也能很好地接收安全请求。
与此相反,带有非标准 header 或者例如DELETE方法的请求,无法通过这种方式创建。在很长一段时间里,JavaScript 都不能进行这样的请求。所以,旧的服务器可能会认为此类请求来自具有特权的来源(privileged source),“因为网页无法发送它们”。
当我们尝试发送一个非安全请求时,浏览器会发送一个特殊的“预检(preflight)”请求到服务器 —— 询问服务器,你接受此类跨源请求吗?
并且,除非服务器明确通过 header 进行确认,否则非安全请求不会被发送。
现在,我们来详细介绍它们。
用于安全请求的 CORS
如果一个请求是跨源的,浏览器始终会向其添加 Origin header。
例如,如果我们从 https://javascript.info/page 请求 https://anywhere.com/request,请求的 header 将如下所示:
GET /request
Host: anywhere.com
Origin: https://javascript.info
...
正如你所看到的,Origin 包含了确切的源(domain/protocol/port),没有路径(path)。
服务器可以检查 Origin,如果同意接受这样的请求,就会在响应中添加一个特殊的 header Access-Control-Allow-Origin。该 header 包含了允许的源(在我们的示例中是 https://javascript.info),或者一个星号 *。然后响应成功,否则报错
浏览器在这里扮演受被信任的中间人的角色:
- 它确保发送的跨源请求带有正确的
Origin。 - 它检查响应中的许可
Access-Control-Allow-Origin,如果存在,则允许 JavaScript 访问响应,否则将失败并报错。

这是一个带有服务器许可的响应示例:
200 OK
Content-Type:text/html; charset=UTF-8
Access-Control-Allow-Origin: https://javascript.info
Response header
对于跨源请求,默认情况下,JavaScript 只能访问“安全的” response header:
Cache-ControlContent-LanguageContent-TypeExpiresLast-ModifiedPragma
访问任何其他 response header 都将导致 error。
请注意:
请注意:列表中没有Content-Lengthheader!
该 header 包含完整的响应长度。因此,如果我们正在下载某些内容,并希望跟踪进度百分比,则需要额外的权限才能访问该 header(请见下文)。
要授予 JavaScript 对任何其他 response header 的访问权限,服务器必须发送 Access-Control-Expose-Headers header。它包含一个以逗号分隔的应该被设置为可访问的非安全 header 名称列表。
例如:
200 OK
Content-Type:text/html; charset=UTF-8
Content-Length: 12345
API-Key: 2c9de507f2c54aa1
Access-Control-Allow-Origin: https://javascript.info
Access-Control-Expose-Headers: Content-Length,API-Key
有了这种 Access-Control-Expose-Headers header,此脚本就被允许读取响应的 Content-Length 和 API-Key header。
“非安全”请求
我们可以使用任何 HTTP 方法:不仅仅是 GET/POST,也可以是 PATCH,DELETE 及其他。
之前,没有人能够设想网页能发出这样的请求。因此,可能仍然存在有些 Web 服务将非标准方法视为一个信号:“这不是浏览器”。它们可以在检查访问权限时将其考虑在内。
因此,为了避免误解,任何“非安全”请求 —— 在过去无法完成的,浏览器不会立即发出此类请求。首先,它会先发送一个初步的、所谓的“预检(preflight)”请求,来请求许可。
预检请求使用 OPTIONS 方法,它没有 body,但是有三个 header:
Access-Control-Request-Methodheader 带有非安全请求的方法。Access-Control-Request-Headersheader 提供一个以逗号分隔的非安全 HTTP-header 列表。
如果服务器同意处理请求,那么它会进行响应,此响应的状态码应该为 200,没有 body,具有 header:Access-Control-Allow-Origin必须为*或进行请求的源(例如https://javascript.info)才能允许此请求。Access-Control-Allow-Methods必须具有允许的方法。Access-Control-Allow-Headers必须具有一个允许的 header 列表。- 另外,header
Access-Control-Max-Age可以指定缓存此权限的秒数。因此,浏览器不是必须为满足给定权限的后续请求发送预检。
让我们在一个跨源PATCH请求的例子中一步一步地看它是如何工作的(此方法经常被用于更新数据):

let response = await fetch('https://site.com/service.json', {
method: 'PATCH',
headers: {
'Content-Type': 'application/json',
'API-Key': 'secret'
}
});
这里有三个理由解释为什么它不是一个安全请求(其实一个就够了):
- 方法
PATCH Content-Type不是这三个中之一:application/x-www-form-urlencoded,multipart/form-data,text/plain。- “非安全”
API-Keyheader。
Step 1 预检请求(preflight request)
在发送我们的请求前,浏览器会自己发送如下所示的预检请求:
OPTIONS /service.json
Host: site.com
Origin: https://javascript.info
Access-Control-Request-Method: PATCH
Access-Control-Request-Headers: Content-Type,API-Key
- 方法:
OPTIONS。 - 路径 —— 与主请求完全相同:
/service.json。 - 特殊跨源头:
Origin—— 来源。Access-Control-Request-Method—— 请求方法。Access-Control-Request-Headers—— 以逗号分隔的“非安全” header 列表。
Step 2 预检响应(preflight response)
服务应响应状态 200 和 header:
Access-Control-Allow-Origin: https://javascript.infoAccess-Control-Allow-Methods: PATCHAccess-Control-Allow-Headers: Content-Type,API-Key。
这将允许后续通信,否则会触发错误。
如果服务器将来需要其他方法和 header,则可以通过将这些方法和 header 添加到列表中来预先允许它们。
例如,此响应还允许PUT、DELETE以及其他 header:
200 OK
Access-Control-Allow-Origin: https://javascript.info
Access-Control-Allow-Methods: PUT,PATCH,DELETE
Access-Control-Allow-Headers: API-Key,Content-Type,If-Modified-Since,Cache-Control
Access-Control-Max-Age: 86400
现在,浏览器可以看到 PATCH 在 Access-Control-Allow-Methods 中,Content-Type,API-Key 在列表 Access-Control-Allow-Headers 中,因此它将发送主请求。
如果 Access-Control-Max-Age 带有一个表示秒的数字,则在给定的时间内,预检权限会被缓存。上面的响应将被缓存 86400 秒,也就是一天。在此时间范围内,后续请求将不会触发预检。假设它们符合缓存的配额,则将直接发送它们。
Step 3 实际请求(actual request)
预检成功后,浏览器现在发出主请求。这里的过程与安全请求的过程相同。
主请求具有 Origin header(因为它是跨源的):
PATCH /service.json
Host: site.com
Content-Type: application/json
API-Key: secret
Origin: https://javascript.info
Step 4 实际响应(actual response)
服务器不应该忘记在主响应中添加 Access-Control-Allow-Origin。成功的预检并不能免除此要求:
Access-Control-Allow-Origin: https://javascript.info
然后,JavaScript 可以读取主服务器响应了。
请注意:
预检请求发生在“幕后”,它对 JavaScript 不可见。
JavaScript 仅获取对主请求的响应,如果没有服务器许可,则获得一个 error。
凭据(Credentials)
默认情况下,由 JavaScript 代码发起的跨源请求不会带来任何凭据(cookies 或者 HTTP 认证(HTTP authentication))。
这对于 HTTP 请求来说并不常见。通常,对 http://site.com 的请求附带有该域的所有 cookie。但是由 JavaScript 方法发出的跨源请求是个例外。
例如,fetch('http://another.com') 不会发送任何 cookie,即使那些 (!) 属于 another.com 域的 cookie。
为什么?
这是因为具有凭据的请求比没有凭据的请求要强大得多。如果被允许,它会使用它们的凭据授予 JavaScript 代表用户行为和访问敏感信息的全部权力。
服务器真的这么信任这种脚本吗?是的,它必须显式地带有允许请求的凭据和附加 header。
要在 fetch 中发送凭据,我们需要添加 credentials: "include" 选项,像这样:
fetch('http://another.com', {
credentials: "include"
});
现在,fetch 将把源自 another.com 的 cookie 和我们的请求发送到该网站。
如果服务器同意接受 带有凭据 的请求,则除了 Access-Control-Allow-Origin 外,服务器还应该在响应中添加 header Access-Control-Allow-Credentials: true。
例如:
200 OK
Access-Control-Allow-Origin: https://javascript.info
Access-Control-Allow-Credentials: true
请注意:对于具有凭据的请求,禁止 Access-Control-Allow-Origin 使用星号 *。如上所示,它必须有一个确切的源。这是另一项安全措施,以确保服务器真的知道它信任的发出此请求的是谁。
Fetch API
到目前为止,我们已经对 fetch 相当了解了。
现在让我们来看看 fetch 的剩余 API,来了解它的全部本领吧。
请注意:
请注意:这些选项 (option) 大多都很少使用。即使跳过本章,你也可以很好地使用fetch。
但是,知道fetch可以做什么还是很好的,所以如果需要,你可以来看看这些细节内容。
这是所有可能的 fetch 选项及其默认值(注释中标注了可选值)的完整列表:
let promise = fetch(url, {
method: "GET", // POST,PUT,DELETE,等。
headers: {
// 内容类型 header 值通常是自动设置的
// 取决于 request body
"Content-Type": "text/plain;charset=UTF-8"
},
body: undefined // string,FormData,Blob,BufferSource,或 URLSearchParams
referrer: "about:client", // 或 "" 以不发送 Referer header,
// 或者是当前源的 url
referrerPolicy: "no-referrer-when-downgrade", // no-referrer,origin,same-origin...
mode: "cors", // same-origin,no-cors
credentials: "same-origin", // omit,include
cache: "default", // no-store,reload,no-cache,force-cache,或 only-if-cached
redirect: "follow", // manual,error
integrity: "", // 一个 hash,像 "sha256-abcdef1234567890"
keepalive: false, // true
signal: undefined, // AbortController 来中止请求
window: window // null
});
一个令人印象深刻的列表,对吧?
我们已经在 Fetch 一章中详细介绍了 method,headers 和 body。
在 Fetch:中止(Abort) 一章中介绍了 signal 选项。
现在让我们一起探索其余的功能。
referrer, referrerPolicy
这些选项决定了 fetch 如何设置 HTTP 的 Referer header。
通常来说,这个 header 是被自动设置的,并包含了发出请求的页面的 url。在大多数情况下,它一点也不重要,但有时出于安全考虑,删除或缩短它是有意义的。
referrer 选项允许设置任何 Referer(在当前域的),或者移除它。
如果不想发送 referrer,可以将 referrer 设置为空字符串:
fetch('/page', {
referrer: "" // 没有 Referer header
});
设置在当前域内的另一个 url:
fetch('/page', {
// 假设我们在 https://javascript.info
// 我们可以设置任何 Referer header,但必须是在当前域内的
referrer: "https://javascript.info/anotherpage"
});
referrerPolicy 选项为 Referer 设置一般的规则。
请求分为 3 种类型:
- 同源请求。
- 跨源请求。
- 从 HTTPS 到 HTTP 的请求 (从安全协议到不安全协议)。
与referrer选项允许设置确切的Referer值不同,referrerPolicy告诉浏览器针对各个请求类型的一般的规则。
可能的值在 Referrer Policy 规范中有详细描述:
"no-referrer-when-downgrade"—— 默认值:除非我们从 HTTPS 发送请求到 HTTP(到安全性较低的协议),否则始终会发送完整的Referer。"no-referrer"—— 从不发送Referer。"origin"—— 只发送在Referer中的域,而不是完整的页面 URL,例如,只发送http://site.com而不是http://site.com/path。"origin-when-cross-origin"—— 发送完整的Referer到相同的源,但对于跨源请求,只发送域部分(同上)。"same-origin"—— 发送完整的Referer到相同的源,但对于跨源请求,不发送Referer。"strict-origin"—— 只发送域,对于 HTTPS→HTTP 请求,则不发送Referer。"strict-origin-when-cross-origin"—— 对于同源情况下则发送完整的Referer,对于跨源情况下,则只发送域,如果是 HTTPS→HTTP 请求,则什么都不发送。"unsafe-url"—— 在Referer中始终发送完整的 url,即使是 HTTPS→HTTP 请求。
这是一个包含所有组合的表格:
| 值 | 同源 | 跨源 | HTTPS→HTTP |
|---|---|---|---|
"no-referrer" |
- | - | - |
"no-referrer-when-downgrade" 或 ""(默认) |
完整的 url | 完整的 url | - |
"origin" |
仅域 | 仅域 | 仅域 |
"origin-when-cross-origin" |
完整的 url | 仅域 | 仅域 |
"same-origin" |
完整的 url | - | - |
"strict-origin" |
仅域 | 仅域 | - |
"strict-origin-when-cross-origin" |
完整的 url | 仅域 | - |
"unsafe-url" |
完整的 url | 完整的 url | 完整的 url |
假如我们有一个带有 URL 结构的管理区域(admin zone),它不应该被从网站外看到。
如果我们发送了一个 fetch,则默认情况下,它总是发送带有页面完整 url 的 Referer header(我们从 HTTPS 向 HTTP 发送请求的情况除外,这种情况下没有 Referer)。
例如 Referer: https://javascript.info/admin/secret/paths。
如果我们想让其他网站只知道域的部分,而不是 URL 路径,我们可以这样设置选项:
fetch('https://another.com/page', {
// ...
referrerPolicy: "origin-when-cross-origin" // Referer: https://javascript.info
});
我们可以将其置于所有 fetch 调用中,也可以将其集成到我们项目的执行所有请求并在内部使用 fetch 的 JavaScript 库中。
与默认行为相比,它的唯一区别在于,对于跨源请求,fetch 只发送 URL 域的部分(例如 https://javascript.info,没有路径)。对于同源请求,我们仍然可以获得完整的 Referer(可能对于调试目的是有用的)。
Referrer policy 不仅适用于
fetch
在 规范 中描述的 referrer policy,不仅适用于fetch,它还具有全局性。
特别是,可以使用Referrer-PolicyHTTP header,或者为每个链接设置<a rel="noreferrer">,来为整个页面设置默认策略(policy)。
mode
mode 选项是一种安全措施,可以防止偶发的跨源请求:
"cors"—— 默认值,允许跨源请求,如 Fetch:跨源请求 一章所述,"same-origin"—— 禁止跨源请求,"no-cors"—— 只允许安全的跨源请求。
当fetch的 URL 来自于第三方,并且我们想要一个“断电开关”来限制跨源能力时,此选项可能很有用。
credentials
credentials 选项指定 fetch 是否应该随请求发送 cookie 和 HTTP-Authorization header。
"same-origin"—— 默认值,对于跨源请求不发送,"include"—— 总是发送,需要来自跨源服务器的Access-Control-Allow-Credentials,才能使 JavaScript 能够访问响应,详细内容在 Fetch:跨源请求 一章有详细介绍,"omit"—— 不发送,即使对于同源请求。
cache
默认情况下,fetch 请求使用标准的 HTTP 缓存。就是说,它遵从 Expires,Cache-Control header,发送 If-Modified-Since,等。就像常规的 HTTP 请求那样。
使用 cache 选项可以忽略 HTTP 缓存或者对其用法进行微调:
"default"——fetch使用标准的 HTTP 缓存规则和 header,"no-store"—— 完全忽略 HTTP 缓存,如果我们设置 headerIf-Modified-Since,If-None-Match,If-Unmodified-Since,If-Match,或If-Range,则此模式会成为默认模式,"reload"—— 不从 HTTP 缓存中获取结果(如果有),而是使用响应填充缓存(如果 response header 允许此操作),"no-cache"—— 如果有一个已缓存的响应,则创建一个有条件的请求,否则创建一个普通的请求。使用响应填充 HTTP 缓存,"force-cache"—— 使用来自 HTTP 缓存的响应,即使该响应已过时(stale)。如果 HTTP 缓存中没有响应,则创建一个常规的 HTTP 请求,行为像正常那样,"only-if-cached"—— 使用来自 HTTP 缓存的响应,即使该响应已过时(stale)。如果 HTTP 缓存中没有响应,则报错。只有当mode为same-origin时生效。
redirect
通常来说,fetch 透明地遵循 HTTP 重定向,例如 301,302 等。
redirect 选项允许对此进行更改:
"follow"—— 默认值,遵循 HTTP 重定向,"error"—— HTTP 重定向时报错,"manual"—— 允许手动处理 HTTP 重定向。在重定向的情况下,我们将获得一个特殊的响应对象,其中包含response.type="opaqueredirect"和归零/空状态以及大多数其他属性。
integrity
integrity 选项允许检查响应是否与已知的预先校验和相匹配。
正如 规范 所描述的,支持的哈希函数有 SHA-256,SHA-384,和 SHA-512,可能还有其他的,这取决于浏览器。
例如,我们下载一个文件,并且我们知道它的 SHA-256 校验和为 “abcdef”(当然,实际校验和会更长)。
我们可以将其放在 integrity 选项中,就像这样:
fetch('http://site.com/file', {
integrity: 'sha256-abcdef'
});
然后 fetch 将自行计算 SHA-256 并将其与我们的字符串进行比较。如果不匹配,则会触发错误。
keepalive
keepalive 选项表示该请求可能会在网页关闭后继续存在。
例如,我们收集有关当前访问者是如何使用我们的页面(鼠标点击,他查看的页面片段)的统计信息,以分析和改善用户体验。
当访问者离开我们的网页时 —— 我们希望能够将数据保存到我们的服务器上。
我们可以使用 window.onunload 事件来实现:
window.onunload = function() {
fetch('/analytics', {
method: 'POST',
body: "statistics",
keepalive: true
});
};
通常,当一个文档被卸载时(unloaded),所有相关的网络请求都会被中止。但是,keepalive 选项告诉浏览器,即使在离开页面后,也要在后台执行请求。所以,此选项对于我们的请求成功至关重要。
它有一些限制:
- 我们无法发送兆字节的数据:
keepalive请求的 body 限制为 64KB。- 如果我们需要收集有关访问的大量统计信息,我们则应该将其定期以数据包的形式发送出去,这样就不会留下太多数据给最后的
onunload请求了。 - 此限制是被应用于当前所有
keepalive请求的总和的。换句话说,我们可以并行执行多个keepalive请求,但它们的 body 长度之和不得超过 64KB。
- 如果我们需要收集有关访问的大量统计信息,我们则应该将其定期以数据包的形式发送出去,这样就不会留下太多数据给最后的
- 如果文档(document)已卸载(unloaded),我们就无法处理服务器响应。因此,在我们的示例中,因为
keepalive,所以fetch会成功,但是后续的函数将无法正常工作。- 在大多数情况下,例如发送统计信息,这不是问题,因为服务器只接收数据,并通常向此类请求发送空的响应。
URL 对象
内建的 URL 类提供了用于创建和解析 URL 的便捷接口。
没有任何一个网络方法一定需要使用 URL 对象,字符串就足够了。所以从技术上讲,我们并不是必须使用 URL。但是有些时候 URL 对象真的很有用。
创建 URL 对象
创建一个新 URL 对象的语法:
new URL(url, [base])
url—— 完整的 URL,或者仅路径(如果设置了 base),base—— 可选的 base URL:如果设置了此参数,且参数url只有路径,则会根据这个base生成 URL。
例如:
let url = new URL('https://javascript.info/profile/admin');
下面这两个 URL 是一样的:
let url1 = new URL('https://javascript.info/profile/admin');
let url2 = new URL('/profile/admin', 'https://javascript.info');
alert(url1); // https://javascript.info/profile/admin
alert(url2); // https://javascript.info/profile/admin
我们可以根据相对于现有 URL 的路径轻松创建一个新的 URL:
let url = new URL('https://javascript.info/profile/admin');
let newUrl = new URL('tester', url);
alert(newUrl); // https://javascript.info/profile/tester
URL 对象立即允许我们访问其组件,因此这是一个解析 url 的好方法,例如:
let url = new URL('https://javascript.info/url');
alert(url.protocol); // https:
alert(url.host); // javascript.info
alert(url.pathname); // /url
这是 URL 组件的备忘单:
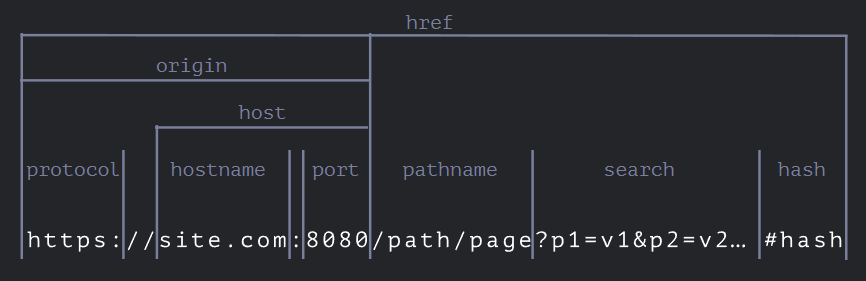
href是完整的 URL,与url.toString()相同protocol以冒号字符:结尾search—— 以问号?开头的一串参数hash以哈希字符#开头- 如果存在 HTTP 身份验证,则这里可能还会有
user和password属性:http://login:password@site.com(图片上没有,很少被用到)。
我们可以将
URL对象传递给网络(和大多数其他)方法,而不是字符串
我们可以在fetch或XMLHttpRequest中使用URL对象,几乎可以在任何需要 URL 字符串的地方都能使用URL对象。
通常,URL对象可以替代字符串传递给任何方法,因为大多数方法都会执行字符串转换,这会将URL对象转换为具有完整 URL 的字符串。
SearchParams "?..."
假设,我们想要创建一个具有给定搜索参数的 url,例如:https://google.com/search?query=JavaScript。
我们可以在 URL 字符串中提供它们:
new URL('https://google.com/search?query=JavaScript')
……但是,如果参数中包含空格,非拉丁字母等(具体参见下文),参数就需要被编码。
因此,有一个 URL 属性用于解决这个问题:url.searchParams,URLSearchParams 类型的对象。
它为搜索参数提供了简便的方法:
append(name, value)—— 按照name添加参数,delete(name)—— 按照name移除参数,get(name)—— 按照name获取参数,getAll(name)—— 获取相同name的所有参数(这是可行的,例如?user=John&user=Pete),has(name)—— 按照name检查参数是否存在,set(name, value)—— set/replace 参数,sort()—— 按 name 对参数进行排序,很少使用,- ……并且它是可迭代的,类似于
Map。
包含空格和标点符号的参数的示例:
let url = new URL('https://google.com/search');
url.searchParams.set('q', 'test me!'); // 添加带有一个空格和一个 ! 的参数
alert(url); // https://google.com/search?q=test+me%21
url.searchParams.set('tbs', 'qdr:y'); // 添加带有一个冒号 : 的参数
// 参数会被自动编码
alert(url); // https://google.com/search?q=test+me%21&tbs=qdr%3Ay
// 遍历搜索参数(被解码)
for(let [name, value] of url.searchParams) {
alert(`${name}=${value}`); // q=test me!,然后是 tbs=qdr:y
}
编码 encoding
RFC3986 标准定义了 URL 中允许哪些字符,不允许哪些字符。
那些不被允许的字符必须被编码,例如非拉丁字母和空格 —— 用其 UTF-8 代码代替,前缀为 %,例如 %20(由于历史原因,空格可以用 + 编码,但这是一个例外)。
好消息是 URL 对象会自动处理这些。我们仅需提供未编码的参数,然后将 URL 转换为字符串:
// 在此示例中使用一些西里尔字符
let url = new URL('https://ru.wikipedia.org/wiki/Тест');
url.searchParams.set('key', 'ъ');
alert(url); //https://ru.wikipedia.org/wiki/%D0%A2%D0%B5%D1%81%D1%82?key=%D1%8A
正如你所看到的,url 路径中的 Тест 和 ъ 参数都被编码了。
URL 变长了,因为每个西里尔字母用 UTF-8 编码的两个字节表示,因此这里有两个 %.. 实体(entities)。
编码字符串
在过去,在出现 URL 对象之前,人们使用字符串作为 URL。
而现在,URL 对象通常更方便,但是仍然可以使用字符串。在很多情况下,使用字符串可以使代码更短。
如果使用字符串,则需要手动编码/解码特殊字符。
下面是用于编码/解码 URL 的内建函数:
- encodeURI —— 编码整个 URL。
- decodeURI —— 解码为编码前的状态。
- encodeURIComponent —— 编码 URL 组件,例如搜索参数,或者 hash,或者 pathname。
- decodeURIComponent —— 解码为编码前的状态。
一个自然的问题:“encodeURIComponent和encodeURI之间有什么区别?我们什么时候应该使用哪个?”
如果我们看一个 URL,就容易理解了,它被分解为本文上面图中所示的组件形式:
https://site.com:8080/path/page?p1=v1&p2=v2#hash
正如我们所看到的,在 URL 中 :,?,=,&,# 这类字符是被允许的。
……另一方面,对于 URL 的单个组件,例如一个搜索参数,则必须对这些字符进行编码,以免破坏 URL 的格式。
encodeURI仅编码 URL 中完全禁止的字符。encodeURIComponent也编码这类字符,此外,还编码#,$,&,+,,,/,:,;,=,?和@字符。
所以,对于一个 URL 整体,我们可以使用encodeURI:
// 在 url 路径中使用西里尔字符
let url = encodeURI('http://site.com/привет');
alert(url); // http://site.com/%D0%BF%D1%80%D0%B8%D0%B2%D0%B5%D1%82
……而对于 URL 参数,我们应该改用 encodeURIComponent:
let music = encodeURIComponent('Rock&Roll');
let url = `https://google.com/search?q=${music}`;
alert(url); // https://google.com/search?q=Rock%26Roll
将其与 encodeURI 进行比较:
let music = encodeURI('Rock&Roll');
let url = `https://google.com/search?q=${music}`;
alert(url); // https://google.com/search?q=Rock&Roll
我们可以看到,encodeURI 没有对 & 进行编码,因为它对于整个 URL 来说是合法的字符。
但是,我们应该编码在搜索参数中的 & 字符,否则,我们将得到 q=Rock&Roll —— 实际上是 q=Rock 加上某个晦涩的参数 Roll。不符合预期。
因此,对于每个搜索参数,我们应该使用 encodeURIComponent,以将其正确地插入到 URL 字符串中。最安全的方式是对 name 和 value 都进行编码,除非我们能够绝对确保它只包含允许的字符。
encode*与URL之间的编码差异
URL 和 URLSearchParams 基于最新的 URL 规范:RFC3986,而encode*函数是基于过时的 RFC2396。
它们之间有一些区别,例如对 IPv6 地址的编码方式不同:
// IPv6 地址的合法 url
let url = 'http://[2607:f8b0:4005:802::1007]/';
alert(encodeURI(url)); // http://%5B2607:f8b0:4005:802::1007%5D/
alert(new URL(url)); // http://[2607:f8b0:4005:802::1007]/
正如我们所看到的,
encodeURI替换了方括号[...],这是不正确的,原因是:在 RFC2396 (August 1998) 时代,还不存在 IPv6 url。
这种情况很少见,encode*函数在大多数情况下都能正常工作。
XMLHttpRequest
XMLHttpRequest 是一个内建的浏览器对象,它允许使用 JavaScript 发送 HTTP 请求。
虽然它的名字里面有 “XML” 一词,但它可以操作任何数据,而不仅仅是 XML 格式。我们可以用它来上传/下载文件,跟踪进度等。
现如今,我们有一个更为现代的方法叫做 fetch,它的出现使得 XMLHttpRequest 在某种程度上被弃用。
在现代 Web 开发中,出于以下三种原因,我们还在使用 XMLHttpRequest:
- 历史原因:我们需要支持现有的使用了
XMLHttpRequest的脚本。 - 我们需要兼容旧浏览器,并且不想用 polyfill(例如为了使脚本更小)。
- 我们需要做一些
fetch目前无法做到的事情,例如跟踪上传进度。
这些话听起来熟悉吗?如果是,那么请继续阅读下面的XMLHttpRequest相关内容吧。如果还不是很熟悉的话,那么请先阅读 Fetch 一章的内容。
XMLHttpRequest 基础
XMLHttpRequest 有两种执行模式:同步(synchronous)和异步(asynchronous)。
我们首先来看看最常用的异步模式:
要发送请求,需要 3 个步骤:
- 创建
XMLHttpRequest:
let xhr = new XMLHttpRequest();
此构造器没有参数。
2. 初始化它,通常就在 new XMLHttpRequest 之后:
xhr.open(method, URL, [async, user, password])
此方法指定请求的主要参数:
- method —— HTTP 方法。通常是 "GET" 或 "POST"。
- URL —— 要请求的 URL,通常是一个字符串,也可以是 URL 对象。
- async —— 如果显式地设置为 false,那么请求将会以同步的方式处理,我们稍后会讲到它。
- user,password —— HTTP 基本身份验证(如果需要的话)的登录名和密码。
请注意,open 调用与其名称相反,不会建立连接。它仅配置请求,而网络活动仅以 send 调用开启。
3. 发送请求。
xhr.send([body])
这个方法会建立连接,并将请求发送到服务器。可选参数 body 包含了 request body。
一些请求方法,像 GET 没有 request body。还有一些请求方法,像 POST 使用 body 将数据发送到服务器。我们稍后会看到相应示例。
4. 监听 xhr 事件以获取响应。
这三个事件是最常用的:
- load —— 当请求完成(即使 HTTP 状态为 400 或 500 等),并且响应已完全下载。
- error —— 当无法发出请求,例如网络中断或者无效的 URL。
- progress —— 在下载响应期间定期触发,报告已经下载了多少。
xhr.onload = function() {
alert(`Loaded: ${xhr.status} ${xhr.response}`);
};
xhr.onerror = function() { // 仅在根本无法发出请求时触发
alert(`Network Error`);
};
xhr.onprogress = function(event) { // 定期触发
// event.loaded —— 已经下载了多少字节
// event.lengthComputable = true,当服务器发送了 Content-Length header 时
// event.total —— 总字节数(如果 lengthComputable 为 true)
alert(`Received ${event.loaded} of ${event.total}`);
};
下面是一个完整的示例。它从服务器加载 /article/xmlhttprequest/example/load,并打印加载进度:
// 1. 创建一个 new XMLHttpRequest 对象
let xhr = new XMLHttpRequest();
// 2. 配置它:从 URL /article/.../load GET-request
xhr.open('GET', '/article/xmlhttprequest/example/load');
// 3. 通过网络发送请求
xhr.send();
// 4. 当接收到响应后,将调用此函数
xhr.onload = function() {
if (xhr.status != 200) { // 分析响应的 HTTP 状态
alert(`Error ${xhr.status}: ${xhr.statusText}`); // 例如 404: Not Found
} else { // 显示结果
alert(`Done, got ${xhr.response.length} bytes`); // response 是服务器响应
}
};
xhr.onprogress = function(event) {
if (event.lengthComputable) {
alert(`Received ${event.loaded} of ${event.total} bytes`);
} else {
alert(`Received ${event.loaded} bytes`); // 没有 Content-Length
}
};
xhr.onerror = function() {
alert("Request failed");
};
一旦服务器有了响应,我们可以在以下 xhr 属性中接收结果:
status
HTTP 状态码(一个数字):200,404,403 等,如果出现非 HTTP 错误,则为 0。
statusText
HTTP 状态消息(一个字符串):状态码为 200 对应于 OK,404 对应于 Not Found,403 对应于 Forbidden。
response(旧脚本可能用的是 responseText)
服务器 response body。
我们还可以使用相应的属性指定超时(timeout):
xhr.timeout = 10000; // timeout 单位是 ms,此处即 10 秒
如果在给定时间内请求没有成功执行,请求就会被取消,并且触发 timeout 事件。
URL 搜索参数(URL search parameters)
为了向 URL 添加像?name=value这样的参数,并确保正确的编码,我们可以使用 URL 对象:
let url = new URL('https://google.com/search');
url.searchParams.set('q', 'test me!');
// 参数 'q' 被编码
xhr.open('GET', url); // https://google.com/search?q=test+me%21
响应类型
我们可以使用 xhr.responseType 属性来设置响应格式:
""(默认)—— 响应格式为字符串,"text"—— 响应格式为字符串,"arraybuffer"—— 响应格式为ArrayBuffer(对于二进制数据,请参见 ArrayBuffer,二进制数组),"blob"—— 响应格式为Blob(对于二进制数据,请参见 Blob),"document"—— 响应格式为 XML document(可以使用 XPath 和其他 XML 方法)或 HTML document(基于接收数据的 MIME 类型)"json"—— 响应格式为 JSON(自动解析)。
例如,我们以 JSON 格式获取响应:
let xhr = new XMLHttpRequest();
xhr.open('GET', '/article/xmlhttprequest/example/json');
xhr.responseType = 'json';
xhr.send();
// 响应为 {"message": "Hello, world!"}
xhr.onload = function() {
let responseObj = xhr.response;
alert(responseObj.message); // Hello, world!
};
请注意:
在旧的脚本中,你可能会看到xhr.responseText,甚至会看到xhr.responseXML属性。
它们是由于历史原因而存在的,以获取字符串或 XML 文档。如今,我们应该在xhr.responseType中设置格式,然后就能获取如上所示的xhr.response了。
readyState
XMLHttpRequest 的状态(state)会随着它的处理进度变化而变化。可以通过 xhr.readyState 来了解当前状态。
规范 中提到的所有状态如下:
UNSENT = 0; // 初始状态
OPENED = 1; // open 被调用
HEADERS_RECEIVED = 2; // 接收到 response header
LOADING = 3; // 响应正在被加载(接收到一个数据包)
DONE = 4; // 请求完成
XMLHttpRequest 对象以 0 → 1 → 2 → 3 → … → 3 → 4 的顺序在它们之间转变。每当通过网络接收到一个数据包,就会重复一次状态 3。
我们可以使用 readystatechange 事件来跟踪它们:
xhr.onreadystatechange = function() {
if (xhr.readyState == 3) {
// 加载中
}
if (xhr.readyState == 4) {
// 请求完成
}
};
你可能在非常老的代码中找到 readystatechange 这样的事件监听器,它的存在是有历史原因的,因为曾经有很长一段时间都没有 load 以及其他事件。如今,它已被 load/error/progress 事件处理程序所替代。
中止请求 Aborting
我们可以随时终止请求。调用 xhr.abort() 即可:
xhr.abort(); // 终止请求
它会触发 abort 事件,且 xhr.status 变为 0。
同步请求
如果在 open 方法中将第三个参数 async 设置为 false,那么请求就会以同步的方式进行。
换句话说,JavaScript 执行在 send() 处暂停,并在收到响应后恢复执行。这有点儿像 alert 或 prompt 命令。
下面是重写的示例,open 的第三个参数为 false:
let xhr = new XMLHttpRequest();
xhr.open('GET', '/article/xmlhttprequest/hello.txt', false);
try {
xhr.send();
if (xhr.status != 200) {
alert(`Error ${xhr.status}: ${xhr.statusText}`);
} else {
alert(xhr.response);
}
} catch(err) { // 代替 onerror
alert("Request failed");
}
这看起来好像不错,但是很少使用同步调用,因为它们会阻塞页面内的 JavaScript,直到加载完成。在某些浏览器中,滚动可能无法正常进行。如果一个同步调用执行时间过长,浏览器可能会建议关闭“挂起(hanging)”的网页。
XMLHttpRequest 的很多高级功能在同步请求中都不可用,例如向其他域发起请求或者设置超时。并且,正如你所看到的,没有进度指示。
基于这些原因,同步请求使用的非常少,几乎从不使用。在这我们就不再讨论它了。
HTTP-header
XMLHttpRequest 允许发送自定义 header,并且可以从响应中读取 header。
HTTP-header 有三种方法:
setRequestHeader(name, value)
使用给定的 name 和 value 设置 request header。
例如:
xhr.setRequestHeader('Content-Type', 'application/json');
Header 的限制
一些 header 是由浏览器专门管理的,例如Referer和Host。 完整列表请见 规范。
为了用户安全和请求的正确性,XMLHttpRequest不允许更改它们。
不能移除 header
XMLHttpRequest的另一个特点是不能撤销setRequestHeader。
一旦设置了 header,就无法撤销了。其他调用会向 header 中添加信息,但不会覆盖它。
例如:
xhr.setRequestHeader('X-Auth', '123');
xhr.setRequestHeader('X-Auth', '456');
// header 将是:
// X-Auth: 123, 456
getResponseHeader(name)
获取具有给定 name 的 header(Set-Cookie 和 Set-Cookie2 除外)。
例如:
xhr.getResponseHeader('Content-Type')
getAllResponseHeaders()
返回除 Set-Cookie 和 Set-Cookie2 外的所有 response header。
header 以单行形式返回,例如:
Cache-Control: max-age=31536000
Content-Length: 4260
Content-Type: image/png
Date: Sat, 08 Sep 2012 16:53:16 GMT
header 之间的换行符始终为 "\r\n"(不依赖于操作系统),所以我们可以很容易地将其拆分为单独的 header。name 和 value 之间总是以冒号后跟一个空格 ": " 分隔。这是标准格式。
因此,如果我们想要获取具有 name/value 对的对象,则需要用一点 JavaScript 代码来处理它们。
像这样(假设如果两个 header 具有相同的名称,那么后者就会覆盖前者):
let headers = xhr
.getAllResponseHeaders()
.split('\r\n')
.reduce((result, current) => {
let [name, value] = current.split(': ');
result[name] = value;
return result;
}, {});
// headers['Content-Type'] = 'image/png'
POST,FormData
要建立一个 POST 请求,我们可以使用内建的 FormData 对象。
语法为:
let formData = new FormData([form]); // 创建一个对象,可以选择从 <form> 中获取数据
formData.append(name, value); // 附加一个字段
我们创建它,可以选择从一个表单中获取数据,如果需要,还可以 append 更多字段,然后:
xhr.open('POST', ...)—— 使用POST方法。xhr.send(formData)将表单发送到服务器。
例如:
<form name="person">
<input name="name" value="John">
<input name="surname" value="Smith">
</form>
<script>
// 从表单预填充 FormData
let formData = new FormData(document.forms.person);
// 附加一个字段
formData.append("middle", "Lee");
// 将其发送出去
let xhr = new XMLHttpRequest();
xhr.open("POST", "/article/xmlhttprequest/post/user");
xhr.send(formData);
xhr.onload = () => alert(xhr.response);
</script>
以 multipart/form-data 编码发送表单。
或者,如果我们更喜欢 JSON,那么可以使用 JSON.stringify 并以字符串形式发送。
只是,不要忘记设置 header Content-Type: application/json,只要有了它,很多服务端框架都能自动解码 JSON:
let xhr = new XMLHttpRequest();
let json = JSON.stringify({
name: "John",
surname: "Smith"
});
xhr.open("POST", '/submit')
xhr.setRequestHeader('Content-type', 'application/json; charset=utf-8');
xhr.send(json);
.send(body) 方法就像一个非常杂食性的动物。它几乎可以发送任何 body,包括 Blob 和 BufferSource 对象。
上传进度
progress 事件仅在下载阶段触发。
也就是说:如果我们 POST 一些内容,XMLHttpRequest 首先上传我们的数据(request body),然后下载响应。
如果我们要上传的东西很大,那么我们肯定会对跟踪上传进度感兴趣。但是 xhr.onprogress 在这里并不起作用。
这里有另一个对象,它没有方法,它专门用于跟踪上传事件:xhr.upload。
它会生成事件,类似于 xhr,但是 xhr.upload 仅在上传时触发它们:
loadstart—— 上传开始。progress—— 上传期间定期触发。abort—— 上传中止。error—— 非 HTTP 错误。load—— 上传成功完成。timeout—— 上传超时(如果设置了timeout属性)。loadend—— 上传完成,无论成功还是 error。
handler 示例:
xhr.upload.onprogress = function(event) {
alert(`Uploaded ${event.loaded} of ${event.total} bytes`);
};
xhr.upload.onload = function() {
alert(`Upload finished successfully.`);
};
xhr.upload.onerror = function() {
alert(`Error during the upload: ${xhr.status}`);
};
跨源请求
XMLHttpRequest 可以使用和 fetch 相同的 CORS 策略进行跨源请求。
就像 fetch 一样,默认情况下不会将 cookie 和 HTTP 授权发送到其他域。要启用它们,可以将 xhr.withCredentials 设置为 true:
let xhr = new XMLHttpRequest();
xhr.withCredentials = true;
xhr.open('POST', 'http://anywhere.com/request');
...
有关跨源 header 的详细信息,请见 Fetch:跨源请求 一章。
可恢复的文件上传
使用 fetch 方法来上传文件相当容易。
连接断开后如何恢复上传?这里没有对此的内建选项,但是我们有实现它的一些方式。
对于大文件(如果我们可能需要恢复),可恢复的上传应该带有上传进度提示。由于 fetch 不允许跟踪上传进度,我们将会使用 XMLHttpRequest。
不太实用的进度事件
要恢复上传,我们需要知道在连接断开前已经上传了多少。
我们有 xhr.upload.onprogress 来跟踪上传进度。
不幸的是,它不会帮助我们在此处恢复上传,因为它会在数据 被发送 时触发,但是服务器是否接收到了?浏览器并不知道。
或许它是由本地网络代理缓冲的(buffered),或者可能是远程服务器进程刚刚终止而无法处理它们,亦或是它在中间丢失了,并没有到达服务器。
这就是为什么此事件仅适用于显示一个好看的进度条。
要恢复上传,我们需要 确切地 知道服务器接收的字节数。而且只有服务器能告诉我们,因此,我们将发出一个额外的请求。
算法
- 首先,创建一个文件 id,以唯一地标识我们要上传的文件:
let fileId = file.name + '-' + file.size + '-' + file.lastModified;
在恢复上传时需要用到它,以告诉服务器我们要恢复的内容。
如果名称,或大小,或最后一次修改时间发生了更改,则将有另一个 fileId。
2. 向服务器发送一个请求,询问它已经有了多少字节,像这样:
let response = await fetch('status', {
headers: {
'X-File-Id': fileId
}
});
// 服务器已有的字节数
let startByte = +await response.text();
这假设服务器通过 X-File-Id header 跟踪文件上传。应该在服务端实现。
如果服务器上尚不存在该文件,则服务器响应应为 0。
3. 然后,我们可以使用 Blob 和 slice 方法来发送从 startByte 开始的文件:
xhr.open("POST", "upload", true);
// 文件 id,以便服务器知道我们要恢复的是哪个文件
xhr.setRequestHeader('X-File-Id', fileId);
// 发送我们要从哪个字节开始恢复,因此服务器知道我们正在恢复
xhr.setRequestHeader('X-Start-Byte', startByte);
xhr.upload.onprogress = (e) => {
console.log(`Uploaded ${startByte + e.loaded} of ${startByte + e.total}`);
};
// 文件可以是来自 input.files[0],或者另一个源
xhr.send(file.slice(startByte));
这里我们将文件 id 作为 X-File-Id 发送给服务器,所以服务器知道我们正在上传哪个文件,并且,我们还将起始字节作为 X-Start-Byte 发送给服务器,所以服务器知道我们不是重新上传它,而是恢复其上传。
服务器应该检查其记录,如果有一个上传的该文件,并且当前已上传的文件大小恰好是 X-Start-Byte,那么就将数据附加到该文件。
长轮询 Long polling
长轮询是与服务器保持持久连接的最简单的方式,它不使用任何特定的协议,例如 WebSocket 或者 Server Sent Event。
它很容易实现,在很多场景下也很好用。
常规轮询
从服务器获取新信息的最简单的方式是定期轮询。也就是说,定期向服务器发出请求:“你好,我在这儿,你有关于我的任何信息吗?”例如,每 10 秒一次。
作为响应,服务器首先通知自己,客户端处于在线状态,然后 —— 发送目前为止的消息包。
这可行,但是也有些缺点:
- 消息传递的延迟最多为 10 秒(两个请求之间)。
- 即使没有消息,服务器也会每隔 10 秒被请求轰炸一次,即使用户切换到其他地方或者处于休眠状态,也是如此。就性能而言,这是一个很大的负担。
因此,如果我们讨论的是一个非常小的服务,那么这种方式可能可行,但总的来说,它需要改进。
长轮询
所谓“长轮询”是轮询服务器的一种更好的方式。
它也很容易实现,并且可以无延迟地传递消息。
其流程为:
- 请求发送到服务器。
- 服务器在有消息之前不会关闭连接。
- 当消息出现时 —— 服务器将对其请求作出响应。
- 浏览器立即发出一个新的请求。
对于此方法,浏览器发出一个请求并与服务器之间建立起一个挂起的(pending)连接的情况是标准的。仅在有消息被传递时,才会重新建立连接。
如果连接丢失,可能是因为网络错误,浏览器会立即发送一个新请求。
实现长轮询的客户端subscribe函数的示例代码:

async function subscribe() {
let response = await fetch("/subscribe");
if (response.status == 502) {
// 状态 502 是连接超时错误,
// 连接挂起时间过长时可能会发生,
// 远程服务器或代理会关闭它
// 让我们重新连接
await subscribe();
} else if (response.status != 200) {
// 一个 error —— 让我们显示它
showMessage(response.statusText);
// 一秒后重新连接
await new Promise(resolve => setTimeout(resolve, 1000));
await subscribe();
} else {
// 获取并显示消息
let message = await response.text();
showMessage(message);
// 再次调用 subscribe() 以获取下一条消息
await subscribe();
}
}
subscribe();
正如你所看到的,subscribe 函数发起了一个 fetch,然后等待响应,处理它,并再次调用自身。
服务器应该可以处理许多挂起的连接
服务器架构必须能够处理许多挂起的连接。
某些服务器架构是每个连接对应一个进程,导致进程数和连接数一样多,而每个进程都会消耗相当多的内存。因此,过多的连接会消耗掉全部内存。
使用像 PHP 和 Ruby 语言编写的后端程序会经常遇到这个问题。
使用 Node.js 编写的服务端程序通常不会出现此类问题。
也就是说,这不是编程语言的问题。大多数现代编程语言,包括 PHP 和 Ruby,都允许实现更适当的后端程序。只是请确保你的服务器架构在同时有很多连接的情况下能够正常工作。
使用场景
在消息很少的情况下,长轮询很有效。
如果消息比较频繁,那么上面描绘的请求-接收(requesting-receiving)消息的图表就会变成锯状状(saw-like)。
每个消息都是一个单独的请求,并带有 header,身份验证开销(authentication overhead)等。
因此,在这种情况下,首选另一种方法,例如:Websocket 或 Server Sent Events。
WebSocket
在 RFC 6455 规范中描述的 WebSocket 协议,提供了一种在浏览器和服务器之间建立持久连接来交换数据的方法。数据可以作为“数据包”在两个方向上传递,而无需中断连接也无需额外的 HTTP 请求。
对于需要连续数据交换的服务,例如网络游戏,实时交易系统等,WebSocket 尤其有用。
一个简单例子
要打开一个 WebSocket 连接,我们需要在 url 中使用特殊的协议 ws 创建 new WebSocket:
let socket = new WebSocket("ws://javascript.info");
同样也有一个加密的 wss:// 协议。类似于 WebSocket 中的 HTTPS。
始终使用
wss://
wss://协议不仅是被加密的,而且更可靠。
因为ws://数据不是加密的,对于任何中间人来说其数据都是可见的。并且,旧的代理服务器不了解 WebSocket,它们可能会因为看到“奇怪的” header 而中止连接。
另一方面,wss://是基于 TLS 的 WebSocket,类似于 HTTPS 是基于 TLS 的 HTTP),传输安全层在发送方对数据进行了加密,在接收方进行解密。因此,数据包是通过代理加密传输的。它们看不到传输的里面的内容,且会让这些数据通过。
一旦 socket 被建立,我们就应该监听 socket 上的事件。一共有 4 个事件:
open—— 连接已建立,message—— 接收到数据,error—— WebSocket 错误,close—— 连接已关闭。
……如果我们想发送一些东西,那么可以使用socket.send(data)。
这是一个示例:
let socket = new WebSocket("wss://javascript.info/article/websocket/demo/hello");
socket.onopen = function(e) {
alert("[open] Connection established");
alert("Sending to server");
socket.send("My name is John");
};
socket.onmessage = function(event) {
alert(`[message] Data received from server: ${event.data}`);
};
socket.onclose = function(event) {
if (event.wasClean) {
alert(`[close] Connection closed cleanly, code=${event.code} reason=${event.reason}`);
} else {
// 例如服务器进程被杀死或网络中断
// 在这种情况下,event.code 通常为 1006
alert('[close] Connection died');
}
};
socket.onerror = function(error) {
alert(`[error] ${error.message}`);
};
在上面的示例中,假设运行着一个用 Node.js 写的小型服务器 server.js。它响应为 “Hello from server, John”,然后等待 5 秒,关闭连接。
所以事件顺序为:open → message → close。
这就是 WebSocket,我们已经可以使用 WebSocket 通信了。很简单,不是吗?
现在让我们更深入地学习它。
建立 WebSocket
当 new WebSocket(url) 被创建后,它将立即开始连接。
在连接期间,浏览器(使用 header)问服务器:“你支持 WebSocket 吗?”如果服务器回复说“我支持”,那么通信就以 WebSocket 协议继续进行,该协议根本不是 HTTP。

这是由
new WebSocket("wss://javascript.info/chat") 发出的请求的浏览器 header 示例。
GET /chat
Host: javascript.info
Origin: https://javascript.info
Connection: Upgrade
Upgrade: websocket
Sec-WebSocket-Key: Iv8io/9s+lYFgZWcXczP8Q==
Sec-WebSocket-Version: 13
Origin—— 客户端页面的源,例如https://javascript.info。WebSocket 对象是原生支持跨源的。没有特殊的 header 或其他限制。旧的服务器无法处理 WebSocket,因此不存在兼容性问题。但Originheader 很重要,因为它允许服务器决定是否使用 WebSocket 与该网站通信。Connection: Upgrade—— 表示客户端想要更改协议。Upgrade: websocket—— 请求的协议是 “websocket”。Sec-WebSocket-Key—— 浏览器随机生成的安全密钥。Sec-WebSocket-Version—— WebSocket 协议版本,当前为 13。
无法模拟 WebSocket 握手
我们不能使用XMLHttpRequest或fetch来进行这种 HTTP 请求,因为不允许 JavaScript 设置这些 header。
如果服务器同意切换为 WebSocket 协议,服务器应该返回响应码 101:
101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: hsBlbuDTkk24srzEOTBUlZAlC2g=
这里 Sec-WebSocket-Accept 是 Sec-WebSocket-Key,是使用特殊的算法重新编码的。浏览器使用它来确保响应与请求相对应。
然后,使用 WebSocket 协议传输数据,我们很快就会看到它的结构(“frames”)。它根本不是 HTTP。
扩展和子协议
WebSocket 可能还有其他 header,Sec-WebSocket-Extensions 和 Sec-WebSocket-Protocol,它们描述了扩展和子协议。
例如:
Sec-WebSocket-Extensions: deflate-frame表示浏览器支持数据压缩。扩展与传输数据有关,扩展了 WebSocket 协议的功能。Sec-WebSocket-Extensionsheader 由浏览器自动发送,其中包含其支持的所有扩展的列表。Sec-WebSocket-Protocol: soap, wamp表示我们不仅要传输任何数据,还要传输 SOAP 或 WAMP(“The WebSocket Application Messaging Protocol”)协议中的数据。WebSocket 子协议已经在 IANA catalogue 中注册。因此,此 header 描述了我们将要使用的数据格式。
这个可选的 header 是使用new WebSocket的第二个参数设置的。它是子协议数组,例如,如果我们想使用 SOAP 或 WAMP:
let socket = new WebSocket("wss://javascript.info/chat", ["soap", "wamp"]);
服务器应该使用同意使用的协议和扩展的列表进行响应。
例如,这个请求:
GET /chat
Host: javascript.info
Upgrade: websocket
Connection: Upgrade
Origin: https://javascript.info
Sec-WebSocket-Key: Iv8io/9s+lYFgZWcXczP8Q==
Sec-WebSocket-Version: 13
Sec-WebSocket-Extensions: deflate-frame
Sec-WebSocket-Protocol: soap, wamp
响应:
101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: hsBlbuDTkk24srzEOTBUlZAlC2g=
Sec-WebSocket-Extensions: deflate-frame
Sec-WebSocket-Protocol: soap
在这里服务器响应 —— 它支持扩展 “deflate-frame”,并且仅支持所请求的子协议中的 SOAP。
数据传输
WebSocket 通信由 “frames”(即数据片段)组成,可以从任何一方发送,并且有以下几种类型:
- “text frames” —— 包含各方发送给彼此的文本数据。
- “binary data frames” —— 包含各方发送给彼此的二进制数据。
- “ping/pong frames” 被用于检查从服务器发送的连接,浏览器会自动响应它们。
- 还有 “connection close frame” 以及其他服务 frames。
在浏览器里,我们仅直接使用文本或二进制 frames。
WebSocket.send()方法可以发送文本或二进制数据。
socket.send(body)调用允许body是字符串或二进制格式,包括Blob,ArrayBuffer等。不需要额外的设置:直接发送它们就可以了。
当我们收到数据时,文本总是以字符串形式呈现。而对于二进制数据,我们可以在Blob和ArrayBuffer格式之间进行选择。
它是由socket.binaryType属性设置的,默认为"blob",因此二进制数据通常以Blob对象呈现。
Blob 是高级的二进制对象,它直接与<a>,<img>及其他标签集成在一起,因此,默认以Blob格式是一个明智的选择。但是对于二进制处理,要访问单个数据字节,我们可以将其改为"arraybuffer":
socket.binaryType = "arraybuffer";
socket.onmessage = (event) => {
// event.data 可以是文本(如果是文本),也可以是 arraybuffer(如果是二进制数据)
};
限速
想象一下:我们的应用程序正在生成大量要发送的数据。但是用户的网速却很慢,可能是在乡下的移动设备上。
我们可以反复地调用 socket.send(data)。但是数据将会缓冲(储存)在内存中,并且只能在网速允许的情况下尽快将数据发送出去。
socket.bufferedAmount 属性储存了目前已缓冲的字节数,等待通过网络发送。
我们可以检查它以查看 socket 是否真的可用于传输。
// 每 100ms 检查一次 socket
// 仅当所有现有的数据都已被发送出去时,再发送更多数据
setInterval(() => {
if (socket.bufferedAmount == 0) {
socket.send(moreData());
}
}, 100);
连接关闭
通常,当一方想要关闭连接时(浏览器和服务器都具有相同的权限),它们会发送一个带有数字码(numeric code)和文本形式的原因的 “connection close frame”。
它的方法是:
socket.close([code], [reason]);
code是一个特殊的 WebSocket 关闭码(可选)reason是一个描述关闭原因的字符串(可选)
然后,另外一方通过close事件处理器获取了关闭码和关闭原因,例如:
// 关闭方:
socket.close(1000, "Work complete");
// 另一方
socket.onclose = event => {
// event.code === 1000
// event.reason === "Work complete"
// event.wasClean === true (clean close)
};
最常见的数字码:
1000—— 默认,正常关闭(如果没有指明code时使用它),1006—— 没有办法手动设定这个数字码,表示连接丢失(没有 close frame)。
还有其他数字码,例如:1001—— 一方正在离开,例如服务器正在关闭,或者浏览器离开了该页面,1009—— 消息太大,无法处理,1011—— 服务器上发生意外错误,- ……等。
完整列表请见 RFC6455, §7.4.1。
WebSocket 码有点像 HTTP 码,但它们是不同的。特别是,小于1000的码都是被保留的,如果我们尝试设置这样的码,将会出现错误。
// 在连接断开的情况下
socket.onclose = event => {
// event.code === 1006
// event.reason === ""
// event.wasClean === false(未关闭 frame)
};
连接状态
要获取连接状态,可以通过带有值的 socket.readyState 属性:
0—— “CONNECTING”:连接还未建立,1—— “OPEN”:通信中,2—— “CLOSING”:连接关闭中,3—— “CLOSED”:连接已关闭。
聊天示例
让我们来看一个使用浏览器 WebSocket API 和 Node.js 的 WebSocket 模块 https://github.com/websockets/ws 的聊天示例。我们将主要精力放在客户端上,但是服务端也很简单。
HTML:我们需要一个 <form> 来发送消息,并且需要一个 <div> 来接收消息:
<!-- 消息表单 -->
<form name="publish">
<input type="text" name="message">
<input type="submit" value="Send">
</form>
<!-- 带有消息的 div -->
<div id="messages"></div>
在 JavaScript 中,我们想要做三件事:
- 打开连接。
- 在表单提交中 ——
socket.send(message)用于消息。 - 对于传入的消息 —— 将其附加(append)到
div#messages上。
代码如下
let socket = new WebSocket("wss://javascript.info/article/websocket/chat/ws");
// 从表单发送消息
document.forms.publish.onsubmit = function() {
let outgoingMessage = this.message.value;
socket.send(outgoingMessage);
return false;
};
// 收到消息 —— 在 div#messages 中显示消息
socket.onmessage = function(event) {
let message = event.data;
let messageElem = document.createElement('div');
messageElem.textContent = message;
document.getElementById('messages').prepend(messageElem);
}
服务端代码有点超出我们的范围。在这里,我们将使用 Node.js,但你不必这样做。其他平台也有使用 WebSocket 的方法。
服务器端的算法为:
- 创建
clients = new Set()—— 一系列 socket。 - 对于每个被接受的 WebSocket,将其添加到
clients.add(socket),并为其设置message事件侦听器以获取其消息。 - 当接收到消息:遍历客户端,并将消息发送给所有人。
- 当连接被关闭:
clients.delete(socket)。
const ws = new require('ws');
const wss = new ws.Server({noServer: true});
const clients = new Set();
http.createServer((req, res) => {
// 在这里,我们仅处理 WebSocket 连接
// 在实际项目中,我们在这里还会有其他代码,来处理非 WebSocket 请求
wss.handleUpgrade(req, req.socket, Buffer.alloc(0), onSocketConnect);
});
function onSocketConnect(ws) {
clients.add(ws);
ws.on('message', function(message) {
message = message.slice(0, 50); // message 的最大长度为 50
for(let client of clients) {
client.send(message);
}
});
ws.on('close', function() {
clients.delete(ws);
});
}
Server Sent Events
Server-Sent Events 规范描述了一个内建的类 EventSource,它能保持与服务器的连接,并允许从中接收事件。
与 WebSocket 类似,其连接是持久的。
但是两者之间有几个重要的区别:
WebSocket |
EventSource |
|---|---|
| 双向:客户端和服务端都能交换消息 | 单向:仅服务端能发送消息 |
| 二进制和文本数据 | 仅文本数据 |
| WebSocket 协议 | 常规 HTTP 协议 |
与 WebSocket 相比,EventSource 是与服务器通信的一种不那么强大的方式。
我们为什么要使用它?
主要原因:简单。在很多应用中,WebSocket 有点大材小用。
我们需要从服务器接收一个数据流:可能是聊天消息或者市场价格等。这正是 EventSource 所擅长的。它还支持自动重新连接,而在 WebSocket 中这个功能需要我们手动实现。此外,它是一个普通的旧的 HTTP,不是一个新协议。
获取消息
要开始接收消息,我们只需要创建 new EventSource(url) 即可。
浏览器将会连接到 url 并保持连接打开,等待事件。
服务器响应状态码应该为 200,header 为 Content-Type: text/event-stream,然后保持此连接并以一种特殊的格式写入消息,就像这样:
data: Message 1
data: Message 2
data: Message 3
data: of two lines
data:后为消息文本,冒号后面的空格是可选的。- 消息以双换行符
\n\n分隔。 - 要发送一个换行
\n,我们可以在要换行的位置立即再发送一个data:(上面的第三条消息)。
在实际开发中,复杂的消息通常是用 JSON 编码后发送。换行符在其中编码为\n,因此不需要多行data:消息。
例如:
data: {"user":"John","message":"First line\n Second line"}
……因此,我们可以假设一个 data: 只保存了一条消息。
对于每个这样的消息,都会生成 message 事件:
let eventSource = new EventSource("/events/subscribe");
eventSource.onmessage = function(event) {
console.log("New message", event.data);
// 对于上面的数据流将打印三次
};
// 或 eventSource.addEventListener('message', ...)
跨源请求
EventSource 支持跨源请求,就像 fetch 和任何其他网络方法。我们可以使用任何 URL:
let source = new EventSource("https://another-site.com/events");
远程服务器将会获取到 Origin header,并且必须以 Access-Control-Allow-Origin 响应来处理。
要传递凭证(credentials),我们应该设置附加选项 withCredentials,就像这样:
let source = new EventSource("https://another-site.com/events", {
withCredentials: true
});
更多关于跨源 header 的详细内容,请参见 Fetch:跨源请求。
重新连接
创建之后,new EventSource 连接到服务器,如果连接断开 —— 则重新连接。
这非常方便,我们不用去关心重新连接的事情。
每次重新连接之间有一点小的延迟,默认为几秒钟。
服务器可以使用 retry: 来设置需要的延迟响应时间(以毫秒为单位)。
retry: 15000
data: Hello, I set the reconnection delay to 15 seconds
retry: 既可以与某些数据一起出现,也可以作为独立的消息出现。
在重新连接之前,浏览器需要等待那么多毫秒。甚至更长,例如,如果浏览器知道(从操作系统)此时没有网络连接,它会等到连接出现,然后重试。
- 如果服务器想要浏览器停止重新连接,那么它应该使用 HTTP 状态码 204 进行响应。
- 如果浏览器想要关闭连接,则应该调用
eventSource.close():
let eventSource = new EventSource(...);
eventSource.close();
并且,如果响应具有不正确的 Content-Type 或者其 HTTP 状态码不是 301,307,200 和 204,则不会进行重新连接。在这种情况下,将会发出 "error" 事件,并且浏览器不会重新连接。
请注意:
当连接最终被关闭时,就无法“重新打开”它。如果我们想要再次连接,只需要创建一个新的EventSource。
消息 id
当一个连接由于网络问题而中断时,客户端和服务器都无法确定哪些消息已经收到哪些没有收到。
为了正确地恢复连接,每条消息都应该有一个 id 字段,就像这样:
data: Message 1
id: 1
data: Message 2
id: 2
data: Message 3
data: of two lines
id: 3
当收到具有 id 的消息时,浏览器会:
- 将属性
eventSource.lastEventId设置为其值。 - 重新连接后,发送带有
id的 headerLast-Event-ID,以便服务器可以重新发送后面的消息。
把
id:放在data:后
请注意:id被服务器附加到data消息后,以确保在收到消息后lastEventId会被更新。
连接状态 readyState
EventSource 对象有 readyState 属性,该属性具有下列值之一:
EventSource.CONNECTING = 0; // 连接中或者重连中
EventSource.OPEN = 1; // 已连接
EventSource.CLOSED = 2; // 连接已关闭
对象创建完成或者连接断开后,它始终是 EventSource.CONNECTING(等于 0)。
我们可以查询该属性以了解 EventSource 的状态。
Event 类型
默认情况下 EventSource 对象生成三个事件:
message—— 收到消息,可以用event.data访问。open—— 连接已打开。error—— 无法建立连接,例如,服务器返回 HTTP 500 状态码。
服务器可以在事件开始时使用event: ...指定另一种类型事件。
例如:
event: join
data: Bob
data: Hello
event: leave
data: Bob
要处理自定义事件,我们必须使用 addEventListener 而非 onmessage:
eventSource.addEventListener('join', event => {
alert(`Joined ${event.data}`);
});
eventSource.addEventListener('message', event => {
alert(`Said: ${event.data}`);
});
eventSource.addEventListener('leave', event => {
alert(`Left ${event.data}`);
});