Cookie, document.cookie
Cookie 是直接存储在浏览器中的一小串数据。它们是 HTTP 协议的一部分,由 RFC 6265 规范定义。
Cookie 通常是由 Web 服务器使用响应 Set-Cookie HTTP-header 设置的。然后浏览器使用 Cookie HTTP-header 将它们自动添加到(几乎)每个对相同域的请求中。
最常见的用处之一就是身份验证:
- 登录后,服务器在响应中使用
Set-CookieHTTP-header 来设置具有唯一“会话标识符(session identifier)”的 cookie。 - 下次当请求被发送到同一个域时,浏览器会使用
CookieHTTP-header 通过网络发送 cookie。 - 所以服务器知道是谁发起了请求。
我们还可以使用document.cookie属性从浏览器访问 cookie。
关于 cookie 及其选项,有很多棘手的事情。在本章中,我们将详细介绍它们。
从 document.cookie 中读取
你的浏览器是否存储了本网站的任何 cookie?让我们来看看:
// 在 javascript.info,我们使用谷歌分析来进行统计,
// 所以应该存在一些 cookie
alert( document.cookie ); // cookie1=value1; cookie2=value2;...
document.cookie 的值由 name=value 对组成,以 ; 分隔。每一个都是独立的 cookie。
为了找到一个特定的 cookie,我们可以以 ; 作为分隔,将 document.cookie 分开,然后找到对应的名字。我们可以使用正则表达式或者数组函数来实现。
我们把这个留给读者当作练习。此外,在本章的最后,你可以找到一些操作 cookie 的辅助函数。
写入 document.cookie
我们可以写入 document.cookie。但这不是一个数据属性,它是一个 访问器(getter/setter)。对其的赋值操作会被特殊处理。
对 document.cookie 的写入操作只会更新其中提到的 cookie,而不会涉及其他 cookie。
例如,此调用设置了一个名称为 user 且值为 John 的 cookie:
document.cookie = "user=John"; // 只会更新名称为 user 的 cookie
alert(document.cookie); // 展示所有 cookie
如果你运行了上面这段代码,你会看到多个 cookie。这是因为 document.cookie= 操作不是重写整所有 cookie。它只设置代码中提到的 cookie user。
从技术上讲,cookie 的名称和值可以是任何字符。为了保持有效的格式,它们应该使用内建的 encodeURIComponent 函数对其进行转义:
// 特殊字符(空格),需要编码
let name = "my name";
let value = "John Smith"
// 将 cookie 编码为 my%20name=John%20Smith
document.cookie = encodeURIComponent(name) + '=' + encodeURIComponent(value);
alert(document.cookie); // ...; my%20name=John%20Smith
限制
存在一些限制:
encodeURIComponent编码后的name=value对,大小不能超过 4KB。因此,我们不能在一个 cookie 中保存大的东西。- 每个域的 cookie 总数不得超过 20+ 左右,具体限制取决于浏览器。
Cookie 有几个选项,其中很多都很重要,应该设置它。
选项被列在 key=value 之后,以 ; 分隔,像这样:
document.cookie = "user=John; path=/; expires=Tue, 19 Jan 2038 03:14:07 GMT"
path
path=/mypath
url 路径前缀必须是绝对路径。它使得该路径下的页面可以访问该 cookie。默认为当前路径。
如果一个 cookie 带有path=/admin设置,那么该 cookie 在/admin和/admin/something下都是可见的,但是在/home或/adminpage下不可见。
通常,我们应该将path设置为根目录:path=/,以使 cookie 对此网站的所有页面可见。
domain
domain=site.com
domain 控制了可访问 cookie 的域。但是在实际中,有一些限制。我们无法设置任何域。
无法从另一个二级域访问 cookie,因此other.com永远不会收到在site.com设置的 cookie。
这是一项安全限制,为了允许我们将敏感数据存储在应该仅在一个站点上可用的 cookie 中。
默认情况下,cookie 只有在设置的域下才能被访问到。
请注意,默认情况下,cookie 也不会共享给子域,例如forum.site.com。
// 如果我们在 site.com 网站上设置了 cookie……
document.cookie = "user=John"
// ……在 forum.site.com 域下我们无法访问它
alert(document.cookie); // 没有 user
……但这是可以设置的。如果我们想允许像 forum.site.com 这样的子域在 site.com 上设置 cookie,也是可以实现的。
为此,当在 site.com 设置 cookie 时,我们应该明确地将 domain 选项设置为根域:domain=site.com。那么,所有子域都可以访问到这样的 cookie。
例如:
// 在 site.com
// 使 cookie 可以被在任何子域 *.site.com 访问:
document.cookie = "user=John; domain=site.com"
// 之后
// 在 forum.site.com
alert(document.cookie); // 有 cookie user=John
出于历史原因,domain=.site.com(site.com 前面有一个点符号)也以相同的方式工作,允许从子域访问 cookie。这是一个旧的表示方式,如果我们需要支持非常旧的浏览器,那么应该使用它。
总结一下,通过 domain 选项的设置,可以实现允许在子域访问 cookie。
expires, max-age
默认情况下,如果一个 cookie 没有设置这两个参数中的任何一个,那么在关闭浏览器之后,它就会消失。此类 cookie 被称为 "session cookie”。
为了让 cookie 在浏览器关闭后仍然存在,我们可以设置 expires 或 max-age 选项中的一个。
expires=Tue, 19 Jan 2038 03:14:07 GMT
cookie 的过期时间定义了浏览器会自动清除该 cookie 的时间。
日期必须完全采用 GMT 时区的这种格式。我们可以使用date.toUTCString来获取它。例如,我们可以将 cookie 设置为 1 天后过期。
// 当前时间 +1 天
let date = new Date(Date.now() + 86400e3);
date = date.toUTCString();
document.cookie = "user=John; expires=" + date;
如果我们将 expires 设置为过去的时间,则 cookie 会被删除。
max-age=3600
它是expires的替代选项,指明了 cookie 的过期时间距离当前时间的秒数。
如果将其设置为 0 或负数,则 cookie 会被删除:
// cookie 会在一小时后失效
document.cookie = "user=John; max-age=3600";
// 删除 cookie(让它立即过期)
document.cookie = "user=John; max-age=0";
secure
secure
Cookie 应只能被通过 HTTPS 传输。
默认情况下,如果我们在http://site.com上设置了 cookie,那么该 cookie 也会出现在https://site.com上,反之亦然。
也就是说,cookie 是基于域的,它们不区分协议。
使用此选项,如果一个 cookie 是通过https://site.com设置的,那么它不会在相同域的 HTTP 环境下出现,例如http://site.com。所以,如果一个 cookie 包含绝不应该通过未加密的 HTTP 协议发送的敏感内容,那么就应该设置secure标识。
// 假设我们现在在 HTTPS 环境下
// 设置 cookie secure(只在 HTTPS 环境下可访问)
document.cookie = "user=John; secure";
samesite
这是另外一个关于安全的特性。它旨在防止 XSRF(跨网站请求伪造)攻击。
为了了解它是如何工作的,以及何时有用,让我们看一下 XSRF 攻击。
XSRF 攻击
想象一下,你登录了 bank.com 网站。此时:你有了来自该网站的身份验证 cookie。你的浏览器会在每次请求时将其发送到 bank.com,以便识别你,并执行所有敏感的财务上的操作。
现在,在另外一个窗口中浏览网页时,你不小心访问了另一个网站 evil.com。该网站具有向 bank.com 网站提交一个具有启动与黑客账户交易的字段的表单 <form action="https://bank.com/pay"> 的 JavaScript 代码。
你每次访问 bank.com 时,浏览器都会发送 cookie,即使该表单是从 evil.com 提交过来的。因此,银行会识别你的身份,并执行真实的付款。

这就是所谓的“跨网站请求伪造(Cross-Site Request Forgery,简称 XSRF)”攻击。
当然,实际的银行会防止出现这种情况。所有由
bank.com 生成的表单都具有一个特殊的字段,即所谓的 “XSRF 保护 token”,恶意页面既不能生成,也不能从远程页面提取它。它可以在那里提交表单,但是无法获取数据。并且,网站 bank.com 会对收到的每个表单都进行这种 token 的检查。但是,实现这种防护需要花费时间。我们需要确保每个表单都具有所需的 token 字段,并且我们还必须检查所有请求。
输入 cookie samesite 选项
Cookie 的 samesite 选项提供了另一种防止此类攻击的方式,(理论上)不需要要求 “XSRF 保护 token”。
它有两个可能的值:
samesite=strict(和没有值的samesite一样)
如果用户来自同一网站之外,那么设置了samesite=strict的 cookie 永远不会被发送。
换句话说,无论用户是通过邮件链接还是从evil.com提交表单,或者进行了任何来自其他域下的操作,cookie 都不会被发送。
如果身份验证 cookie 具有samesite选项,那么 XSRF 攻击是没有机会成功的,因为来自evil.com的提交没有 cookie。因此,bank.com将无法识别用户,也就不会继续进行付款。
这种保护是相当可靠的。只有来自bank.com的操作才会发送samesitecookie,例如来自bank.com的另一页面的表单提交。
虽然,这样有一些不方便。
当用户通过合法的链接访问bank.com时,例如从他们自己的笔记,他们会感到惊讶,bank.com无法识别他们的身份。实际上,在这种情况下不会发送samesite=strictcookie。
我们可以通过使用两个 cookie 来解决这个问题:一个 cookie 用于“一般识别”,仅用于说 “Hello, John”,另一个带有samesite=strict的 cookie 用于进行数据更改的操作。这样,从网站外部来的用户会看到欢迎信息,但是支付操作必须是从银行网站启动的,这样第二个 cookie 才能被发送。samesite=lax
一种更轻松的方法,该方法还可以防止 XSRF 攻击,并且不会破坏用户体验。
宽松(lax)模式,和strict模式类似,当从外部来到网站,则禁止浏览器发送 cookie,但是增加了一个例外。
如果以下两个条件均成立,则会发送含samesite=lax的 cookie:
- HTTP 方法是“安全的”(例如 GET 方法,而不是 POST)。
所有安全的 HTTP 方法详见 RFC7231 规范。基本上,这些都是用于读取而不是写入数据的方法。它们不得执行任何更改数据的操作。跟随链接始终是 GET,是安全的方法。 - 该操作执行顶级导航(更改浏览器地址栏中的 URL)。
这通常是成立的,但是如果导航是在一个<iframe>中执行的,那么它就不是顶级的。此外,用于网络请求的 JavaScript 方法不会执行任何导航,因此它们不适合。
所以,samesite=lax所做的是基本上允许最常见的“前往 URL”操作携带 cookie。例如,从笔记中打开网站链接就满足这些条件。
但是,任何更复杂的事儿,例如来自另一个网站的网络请求或表单提交都会丢失 cookie。
如果这种情况适合你,那么添加samesite=lax将不会破坏用户体验并且可以增加保护。
总体而言,samesite是一个很好的选项。
但它有个缺点:
samesite会被到 2017 年左右的旧版本浏览器忽略(不兼容)。
因此,如果我们仅依靠samesite提供保护,那么在旧版本的浏览器上将很容易受到攻击。
但是,我们肯定可以将samesite与其他保护措施一起使用,例如 XSRF token,这样可以多增加一层保护,将来,当旧版本的浏览器淘汰时,我们可能就可以删除 xsrf token 这种方式了。
httpOnly
这个选项和 JavaScript 没有关系,但是我们必须为了完整性也提一下它。
Web 服务器使用 Set-Cookie header 来设置 cookie。并且,它可以设置 httpOnly 选项。
这个选项禁止任何 JavaScript 访问 cookie。我们使用 document.cookie 看不到此类 cookie,也无法对此类 cookie 进行操作。
这是一种预防措施,当黑客将自己的 JavaScript 代码注入网页,并等待用户访问该页面时发起攻击,而这个选项可以防止此时的这种攻击。这应该是不可能发生的,黑客应该无法将他们的代码注入我们的网站,但是网站有可能存在 bug,使得黑客能够实现这样的操作。
通常来说,如果发生了这种情况,并且用户访问了带有黑客 JavaScript 代码的页面,黑客代码将执行并通过 document.cookie 获取到包含用户身份验证信息的 cookie。这就很糟糕了。
但是,如果 cookie 设置了 httpOnly,那么 document.cookie 则看不到 cookie,所以它受到了保护。
附录:Cookie 函数
这里有一组有关 cookie 操作的函数,比手动修改 document.cookie 方便得多。
有很多这种 cookie 库,所以这些函数只用于演示。虽然它们都能正常使用。
getCookie(name)
获取 cookie 最简短的方式是使用 正则表达式。
getCookie(name) 函数返回具有给定 name 的 cookie:
// 返回具有给定 name 的 cookie,
// 如果没找到,则返回 undefined
function getCookie(name) {
let matches = document.cookie.match(new RegExp(
"(?:^|; )" + name.replace(/([\.$?*|{}\(\)\[\]\\\/\+^])/g, '\\$1') + "=([^;]*)"
));
return matches ? decodeURIComponent(matches[1]) : undefined;
}
这里的 new RegExp 是动态生成的,以匹配 ; name=<value>。
请注意 cookie 的值是经过编码的,所以 getCookie 使用了内建方法 decodeURIComponent 函数对其进行解码。
setCookie(name, value, options)
将 cookie 的 name 设置为具有默认值 path=/(可以修改以添加其他默认值)和给定值 value:
function setCookie(name, value, options = {}) {
options = {
path: '/',
// 如果需要,可以在这里添加其他默认值
...options
};
if (options.expires instanceof Date) {
options.expires = options.expires.toUTCString();
}
let updatedCookie = encodeURIComponent(name) + "=" + encodeURIComponent(value);
for (let optionKey in options) {
updatedCookie += "; " + optionKey;
let optionValue = options[optionKey];
if (optionValue !== true) {
updatedCookie += "=" + optionValue;
}
}
document.cookie = updatedCookie;
}
// 使用范例:
setCookie('user', 'John', {secure: true, 'max-age': 3600});
deleteCookie(name)
要删除一个 cookie,我们可以给它设置一个负的过期时间来调用它:
function deleteCookie(name) {
setCookie(name, "", {
'max-age': -1
})
}
更新或删除必须使用相同的路径和域
请注意:当我们更新或删除一个 cookie 时,我们应该使用和设置 cookie 时相同的路径和域选项。
附录:第三方 cookie
如果 cookie 是由用户所访问的页面的域以外的域放置的,则称其为第三方 cookie。
例如:
site.com网站的一个页面加载了另外一个网站的 banner:<img src="https://ads.com/banner.png">。- 与 banner 一起,
ads.com的远程服务器可能会设置带有id=1234这样的 cookie 的Set-Cookieheader。此类 cookie 源自ads.com域,并且仅在ads.com中可见:
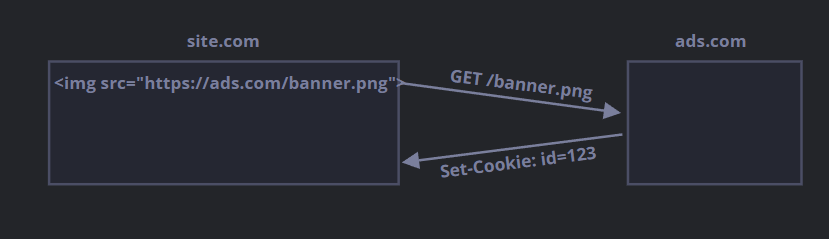
- 下次访问
ads.com网站时,远程服务器获取 cookieid并识别用户:
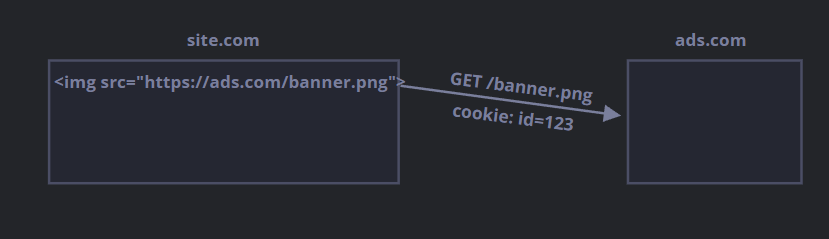
- 更为重要的是,当用户从
site.com网站跳转至另一个也带有 banner 的网站other.com时,ads.com会获得该 cookie,因为它属于ads.com,从而识别用户并在他在网站之间切换时对其进行跟踪:

由于它的性质,第三方 cookie 通常用于跟踪和广告服务。它们被绑定在原始域上,因此ads.com可以在不同网站之间跟踪同一用户,如果这些网站都可以访问ads.com的话。
当然,有些人不喜欢被跟踪,因此浏览器允许禁止此类 cookie。
此外,一些现代浏览器对此类 cookie 采取特殊策略:

- Safari 浏览器完全不允许第三方 cookie。
- Firefox 浏览器附带了一个第三方域的黑名单,它阻止了来自名单内的域的第三方 cookie。
请注意:
如果我们加载了一个来自第三方域的脚本,例如<script src="https://google-analytics.com/analytics.js">,并且该脚本使用document.cookie设置了 cookie,那么此类 cookie 就不是第三方的。
如果一个脚本设置了一个 cookie,那么无论脚本来自何处 —— 这个 cookie 都属于当前网页的域。
附录:GDPR
本主题和 JavaScript 无关,只是设置 cookie 时的一些注意事项。
欧洲有一项名为 GDPR 的立法,该法规针对网站尊重用户实施了一系列规则。其中之一就是需要明确的许可才可以跟踪用户的 cookie。
请注意,这仅与跟踪/识别/授权 cookie 有关。
所以,如果我们设置一个只保存了一些信息的 cookie,但是既不跟踪也不识别用户,那么我们可以自由地设置它。
但是,如果我们要设置带有身份验证会话(session)或跟踪 id 的 cookie,那么必须得到用户的允许。
网站为了遵循 GDPR 通常有两种做法。你一定已经在网站中看到过它们了:
- 如果一个网站想要仅为已经经过身份验证的用户设置跟踪的 cookie。
为此,注册表单中必须要有一个复选框,例如“接受隐私政策”(描述怎么使用 cookie),用户必须勾选它,然后网站就可以自由设置身份验证 cookie 了。 - 如果一个网站想要为所有人设置跟踪的 cookie。
为了合法地这样做,网站为每个新用户显示一个“初始屏幕”弹窗,并要求他们同意设置 cookie。之后网站就可以设置 cookie,并可以让用户看到网站内容了。不过,这可能会使新用户感到反感。没有人喜欢看到“必须点击”的初始屏幕弹窗而不是网站内容。但是 GDPR 要求必须得到用户明确地准许。
GDPR 不仅涉及 cookie,还涉及其他与隐私相关的问题,但这超出了我们的讨论范围。
LocalStorage, sessionStorage
Web 存储对象 localStorage 和 sessionStorage 允许我们在浏览器上保存键/值对。
它们有趣的是,在页面刷新后(对于 sessionStorage)甚至浏览器完全重启(对于 localStorage)后,数据仍然保留在浏览器中。我们很快就会看到。
我们已经有了 cookie。为什么还要其他存储对象呢?
- 与 cookie 不同,Web 存储对象不会随每个请求被发送到服务器。因此,我们可以保存更多数据。大多数现代浏览器都允许保存至少 5MB 的数据(或更多),并且具有用于配置数据的设置。
- 还有一点和 cookie 不同,服务器无法通过 HTTP header 操纵存储对象。一切都是在 JavaScript 中完成的。
- 存储绑定到源(域/协议/端口三者)。也就是说,不同协议或子域对应不同的存储对象,它们之间无法访问彼此数据。
两个存储对象都提供相同的方法和属性: setItem(key, value)—— 存储键/值对。getItem(key)—— 按照键获取值。removeItem(key)—— 删除键及其对应的值。clear()—— 删除所有数据。key(index)—— 获取该索引下的键名。length—— 存储的内容的长度。
正如你所看到的,它就像一个Map集合(setItem/getItem/removeItem),但也允许通过key(index)来按索引访问。
让我们看看它是如何工作的吧。
localStorage 示例
localStorage 最主要的特点是:
- 在同源的所有标签页和窗口之间共享数据。
- 数据不会过期。它在浏览器重启甚至系统重启后仍然存在。
例如,如果你运行此代码……
localStorage.setItem('test', 1);
……然后关闭/重新打开浏览器,或者只是在不同的窗口打开同一页面,然后你可以这样获取它:
alert( localStorage.getItem('test') ); // 1
我们只需要在同一个源(域/端口/协议),URL 路径可以不同。
在所有同源的窗口之间,localStorage 数据可以共享。因此,如果我们在一个窗口中设置了数据,则在另一个窗口中也可以看到数据变化。
类对象形式访问
我们还可以像使用一个普通对象那样,读取/设置键,像这样:
// 设置 key
localStorage.test = 2;
// 获取 key
alert( localStorage.test ); // 2
// 删除 key
delete localStorage.test;
这是历史原因造成的,并且大多数情况下都可行,但通常不建议这样做,因为:
- 如果键是由用户生成的,那么它可以是任何内容,例如
length或toString,也可以是localStorage的另一种内建方法。在这种情况下,getItem/setItem可以正常工作,而类对象访问的方式则会失败:
let key = 'length';
localStorage[key] = 5; // Error,无法对 length 进行赋值
- 有一个
storage事件,在我们更改数据时会触发。但以类对象方式访问时,不会触发该事件。我们将在本章的后面看到。
遍历键
正如我们所看到的,这些方法提供了“按照键获取/设置/删除”的功能。但我们如何获取所有保存的值或键呢?
不幸的是,存储对象是不可迭代的。
一种方法是像遍历数组那样遍历它们:
for(let i = 0; i < localStorage.length; i++) {
let key = localStorage.key(i);
alert(`${key}: ${localStorage.getItem(key)}`);
}
另一个方式是使用 for key in localStorage 循环,就像处理常规对象一样。
它会遍历所有的键,但也会输出一些我们不需要的内建字段。
// 不好的尝试
for(let key in localStorage) {
alert(key); // 显示 getItem,setItem 和其他内建的东西
}
……因此,我们需要使用 hasOwnProperty 检查来过滤掉原型中的字段:
for(let key in localStorage) {
if (!localStorage.hasOwnProperty(key)) {
continue; // 跳过像 "setItem","getItem" 等这样的键
}
alert(`${key}: ${localStorage.getItem(key)}`);
}
……或者,使用 Object.keys 获取只属于“自己”的键,然后如果需要,可以遍历它们:
let keys = Object.keys(localStorage);
for(let key of keys) {
alert(`${key}: ${localStorage.getItem(key)}`);
}
后者有效,因为 Object.keys 只返回属于对象的键,会忽略原型上的。
仅字符串
请注意,键和值都必须是字符串。
如果是任何其他类型,例数字或对象,它会被自动转换为字符串。
localStorage.user = {name: "John"};
alert(localStorage.user); // [object Object]
我们可以使用 JSON 来存储对象:
localStorage.user = JSON.stringify({name: "John"});
// sometime later
let user = JSON.parse( localStorage.user );
alert( user.name ); // John
也可以对整个存储对象进行字符串化处理,例如出于调试目的:
// 为 JSON.stringify 增加了格式设置选项,以使对象看起来更美观
alert( JSON.stringify(localStorage, null, 2) );
sessionStorage
sessionStorage 对象的使用频率比 localStorage 对象低得多。
属性和方法是相同的,但是它有更多的限制:
sessionStorage的数据只存在于当前浏览器标签页。- 具有相同页面的另一个标签页中将会有不同的存储。
- 但是,它在同一标签页下的 iframe 之间是共享的(假如它们来自相同的源)。
- 数据在页面刷新后仍然保留,但在关闭/重新打开浏览器标签页后不会被保留。
让我们看看它的运行效果。
运行此代码……
sessionStorage.setItem('test', 1);
……然后刷新页面。这时你仍然可以获取到数据:
alert( sessionStorage.getItem('test') ); // after refresh: 1
……但是,如果你在另一个新的标签页中打开此页面,然后在新页面中再次运行上面这行代码,则会得到 null,表示“未找到数据”。
这是因为 sessionStorage 不仅绑定到源,还绑定在同一浏览器标签页。因此,sessionStorage 很少被使用。
Storage 事件
当 localStorage 或 sessionStorage 中的数据更新后,storage 事件就会触发,它具有以下属性:
key—— 发生更改的数据的key(如果调用的是.clear()方法,则为null)。oldValue—— 旧值(如果是新增数据,则为null)。newValue—— 新值(如果是删除数据,则为null)。url—— 发生数据更新的文档的 url。storageArea—— 发生数据更新的localStorage或sessionStorage对象。
重要的是:该事件会在所有可访问到存储对象的window对象上触发,导致当前数据改变的window对象除外。
我们来详细解释一下。
想象一下,你有两个窗口,它们具有相同的页面。所以localStorage在它们之间是共享的。
你可以想在浏览器的两个窗口中打开此页面来测试下面的代码。
如果两个窗口都在监听window.onstorage事件,那么每个窗口都会对另一个窗口中发生的更新作出反应。
// 在其他文档对同一存储进行更新时触发
window.onstorage = event => { // 也可以使用 window.addEventListener('storage', event => {
if (event.key != 'now') return;
alert(event.key + ':' + event.newValue + " at " + event.url);
};
localStorage.setItem('now', Date.now());
请注意,该事件还包含:event.url —— 发生数据更新的文档的 url。
并且,event.storageArea 包含存储对象 —— sessionStorage 和 localStorage 具有相同的事件,所以 event.storageArea 引用了被修改的对象。我们可能会想设置一些东西,以“响应”更改。
这允许同源的不同窗口交换消息。
现代浏览器还支持 Broadcast channel API,这是用于同源窗口之间通信的特殊 API,它的功能更全,但被支持的情况不好。有一些库基于 localStorage 来 polyfill 该 API,使其可以用在任何地方。
IndexedDB
IndexedDB 是一个浏览器内建的数据库,它比 localStorage 强大得多。
- 通过支持多种类型的键,来存储几乎可以是任何类型的值。
- 支撑事务的可靠性。
- 支持键值范围查询、索引。
- 和
localStorage相比,它可以存储更大的数据量。
对于传统的 客户端-服务器 应用,这些功能通常是没有必要的。IndexedDB 适用于离线应用,可与 ServiceWorkers 和其他技术相结合使用。
根据规范 https://www.w3.org/TR/IndexedDB 中的描述,IndexedDB 的本机接口是基于事件的。
我们还可以在基于 promise 的包装器(wrapper),如 https://github.com/jakearchibald/idb 的帮助下使用async/await。这要方便的多,但是包装器并不完美,它并不能替代所有情况下的事件。因此,我们先练习事件(events),在理解了 IndexedDB 之后,我们将使用包装器。
数据在哪儿?
从技术上讲,数据通常与浏览器设置、扩展程序等一起存储在访问者的主目录中。
不同的浏览器和操作系统级别的用户都有各自独立的存储。
打开数据库
要想使用 IndexedDB,首先需要 open(连接)一个数据库。
语法:
let openRequest = indexedDB.open(name, version);
name—— 字符串,即数据库名称。version—— 一个正整数版本,默认为1(下面解释)。
数据库可以有许多不同的名称,但是必须存在于当前的源(域/协议/端口)中。不同的网站不能相互访问对方的数据库。
调用之后会返回openRequest对象,我们需要监听该对象上的事件:success:数据库准备就绪,openRequest.result中有了一个数据库对象“Database Object”,我们应该将其用于进一步的调用。error:打开失败。upgradeneeded:数据库已准备就绪,但其版本已过时(见下文)。
IndexedDB 具有内建的“模式(scheme)版本控制”机制,这在服务器端数据库中是不存在的。
与服务器端数据库不同,IndexedDB 存在于客户端,数据存储在浏览器中。因此,开发人员无法随时都能访问它。因此,当我们发布了新版本的应用程序,用户访问我们的网页,我们可能需要更新该数据库。
如果本地数据库版本低于open中指定的版本,会触发一个特殊事件upgradeneeded。我们可以根据需要比较版本并升级数据结构。
当数据库还不存在时(从技术上讲,其版本为0),也会触发upgradeneeded事件。因此,我们可以执行初始化。
假设我们发布了应用程序的第一个版本。
接下来我们就可以打开版本1中的 IndexedDB 数据库,并在一个upgradeneeded的处理程序中执行初始化,如下所示:
let openRequest = indexedDB.open("store", 1);
openRequest.onupgradeneeded = function() {
// 如果客户端没有数据库则触发
// ...执行初始化...
};
openRequest.onerror = function() {
console.error("Error", openRequest.error);
};
openRequest.onsuccess = function() {
let db = openRequest.result;
// 继续使用 db 对象处理数据库
};
之后不久,我们发布了第二个版本。
我们可以打开版本 2 中的 IndexedDB 数据库,并像这样进行升级:
let openRequest = indexedDB.open("store", 2);
openRequest.onupgradeneeded = function(event) {
// 现有的数据库版本小于 2(或不存在)
let db = openRequest.result;
switch(event.oldVersion) { // 现有的 db 版本
case 0:
// 版本 0 表示客户端没有数据库
// 执行初始化
case 1:
// 客户端版本为 1
// 更新
}
};
请注意:虽然我们目前的版本是 2,onupgradeneeded 处理程序有针对版本 0 的代码分支(适用于初次访问,浏览器中没有数据库的用户)和针对版本 1 的代码分支(用于升级)。
接下来,当且仅当 onupgradeneeded 处理程序没有错误地执行完成,openRequest.onsuccess 被触发,数据库才算是成功打开了。
删除数据库:
let deleteRequest = indexedDB.deleteDatabase(name)
// deleteRequest.onsuccess/onerror 追踪(tracks)结果
我们无法使用较旧的 open 调用版本打开数据库
如果当前用户的数据库版本比open调用的版本更高(比如当前的数据库版本为3,我们却尝试运行open(...2),就会产生错误并触发openRequest.onerror)。
这很罕见,但这样的事情可能会在用户加载了一个过时的 JavaScript 代码时发生(例如用户从一个代理缓存中加载 JS)。在这种情况下,代码是过时的,但数据库却是最新的。
为了避免这样的错误产生,我们应当检查db.version并建议用户重新加载页面。使用正确的 HTTP 缓存头(header)来避免之前缓存的旧代码被加载,这样你就永远不会遇到此类问题。
并行更新问题
提到版本控制,有一个相关的小问题。
举个例子:
- 一个用户在一个浏览器标签页中打开了数据库版本为
1的我们的网站。 - 接下来我们发布了一个更新,使得代码更新了。
- 接下来同一个用户在另一个浏览器标签中打开了这个网站。
这时,有一个标签页和版本为1的数据库建立了一个连接,而另一个标签页试图在其upgradeneeded处理程序中将数据库版本升级到2。
问题是,这两个网页是同一个站点,同一个源,共享同一个数据库。而数据库不能同时为版本1和版本2。要执行版本2的更新,必须关闭对版本1的所有连接,包括第一个标签页中的那个。
为了解决这一问题,versionchange事件会在“过时的”数据库对象上触发。我们需要监听这个事件,关闭对旧版本数据库的连接(还应该建议访问者重新加载页面,以加载最新的代码)。
如果我们不监听versionchange事件,也不去关闭旧连接,那么新的连接就不会建立。openRequest对象会产生blocked事件,而不是success事件。因此第二个标签页无法正常工作。
下面是能够正确处理并行升级情况的代码。它安装了onversionchange处理程序,如果当前数据库连接过时(数据库版本在其他位置被更新)并关闭连接,则会触发该处理程序。
let openRequest = indexedDB.open("store", 2);
openRequest.onupgradeneeded = ...;
openRequest.onerror = ...;
openRequest.onsuccess = function() {
let db = openRequest.result;
db.onversionchange = function() {
db.close();
alert("Database is outdated, please reload the page.")
};
// ……数据库已经准备好,请使用它……
};
openRequest.onblocked = function() {
// 如果我们正确处理了 onversionchange 事件,这个事件就不应该触发
// 这意味着还有另一个指向同一数据库的连接
// 并且在 db.onversionchange 被触发后,该连接没有被关闭
};
……换句话说,在这我们做两件事:
- 如果当前数据库版本过时,
db.onversionchange监听器会通知我们并行尝试更新。 openRequest.onblocked监听器通知我们相反的情况:在其他地方有一个与过时的版本的连接未关闭,因此无法建立新的连接。
我们可以在db.onversionchange中更优雅地进行处理,提示访问者在连接关闭之前保存数据等。
或者,另一种方式是不在db.onversionchange中关闭数据库,而是使用onblocked处理程序(在浏览器新 tab 页中)来提醒用户,告诉他新版本无法加载,直到他们关闭浏览器其他 tab 页。
这种更新冲突很少发生,但我们至少应该有一些对其进行处理的程序,至少在onblocked处理程序中进行处理,以防程序默默卡死而影响用户体验。
对象库(object store)
要在 IndexedDB 中存储某些内容,我们需要一个 对象库。
对象库是 IndexedDB 的核心概念,在其他数据库中对应的对象称为“表”或“集合”。它是储存数据的地方。一个数据库可能有多个存储区:一个用于存储用户数据,另一个用于商品,等等。
尽管被命名为“对象库”,但也可以存储原始类型。
几乎可以存储任何值,包括复杂的对象。
IndexedDB 使用 标准序列化算法 来克隆和存储对象。类似于 JSON.stringify,不过功能更加强大,能够存储更多的数据类型。
有一种对象不能被存储:循环引用的对象。此类对象不可序列化,也不能进行 JSON.stringify。
库中的每个值都必须有唯一的键 key。
键的类型必须为数字、日期、字符串、二进制或数组。它是唯一的标识符,所以我们可以通过键来搜索/删除/更新值。

正如我们很快就会看到的,类似于
localStorage,我们向存储区添加值时,可以提供一个键。但当我们存储对象时,IndexedDB 允许将一个对象属性设置为键,这就更加方便了。或者,我们可以自动生成键。但我们需要先创建一个对象库。
创建对象库的语法:
db.createObjectStore(name[, keyOptions]);
请注意,操作是同步的,不需要 await。
name是存储区名称,例如"books"表示书。keyOptions是具有以下两个属性之一的可选对象:keyPath—— 对象属性的路径,IndexedDB 将以此路径作为键,例如id。autoIncrement—— 如果为true,则自动生成新存储的对象的键,键是一个不断递增的数字。
如果我们不提供keyOptions,那么以后需要在存储对象时,显式地提供一个键。
例如,此对象库使用id属性作为键:
db.createObjectStore('books', {keyPath: 'id'});
在 upgradeneeded 处理程序中,只有在创建数据库版本时,对象库被才能被 创建/修改。
这是技术上的限制。在 upgradeneedHandler 之外,可以添加/删除/更新数据,但是只能在版本更新期间创建/删除/更改对象库。
要进行数据库版本升级,主要有两种方法:
- 我们实现每个版本的升级功能:从 1 到 2,从 2 到 3,从 3 到 4,等等。在
upgradeneeded中,可以进行版本比较(例如,老版本是 2,需要升级到 4),并针对每个中间版本(2 到 3,然后 3 到 4)逐步运行每个版本的升级。 - 或者我们可以检查数据库:以
db.objectStoreNames的形式获取现有对象库的列表。该对象是一个 DOMStringList 提供contains(name)方法来检查 name 是否存在,再根据存在和不存在的内容进行更新。
对于小型数据库,第二种方法可能更简单。
下面是第二种方法的演示:
let openRequest = indexedDB.open("db", 2);
// 创建/升级 数据库而无需版本检查
openRequest.onupgradeneeded = function() {
let db = openRequest.result;
if (!db.objectStoreNames.contains('books')) { // 如果没有 “books” 数据
db.createObjectStore('books', {keyPath: 'id'}); // 创造它
}
};
删除对象库:
db.deleteObjectStore('books')
事务(transaction)
术语“事务(transaction)”是通用的,许多数据库中都有用到。
事务是一组操作,要么全部成功,要么全部失败。
例如,当一个人买东西时,我们需要:
- 从他们的账户中扣除这笔钱。
- 将该项目添加到他们的清单中。
如果完成了第一个操作,但是出了问题,比如停电。这时无法完成第二个操作,这非常糟糕。两件时应该要么都成功(购买完成,好!)或同时失败(这个人保留了钱,可以重新尝试)。
事务可以保证同时完成。
所有数据操作都必须在 IndexedDB 中的事务内进行。
启动事务:
db.transaction(store[, type]);
store是事务要访问的库名称,例如"books"。如果我们要访问多个库,则是库名称的数组。type– 事务类型,以下类型之一:readonly—— 只读,默认值。readwrite—— 只能读取和写入数据,而不能 创建/删除/更改 对象库。
还有versionchange事务类型:这种事务可以做任何事情,但不能被手动创建。IndexedDB 在打开数据库时,会自动为upgradeneeded处理程序创建versionchange事务。这就是它为什么可以更新数据库结构、创建/删除 对象库的原因。
为什么会有不同类型的事务?
性能是事务需要标记为readonly和readwrite的原因。
许多readonly事务能够同时访问同一存储区,但readwrite事务不能。因为readwrite事务会“锁定”存储区进行写操作。下一个事务必须等待前一个事务完成,才能访问相同的存储区。
创建事务后,我们可以将项目添加到库,就像这样:
let transaction = db.transaction("books", "readwrite"); // (1)
// 获取对象库进行操作
let books = transaction.objectStore("books"); // (2)
let book = {
id: 'js',
price: 10,
created: new Date()
};
let request = books.add(book); // (3)
request.onsuccess = function() { // (4)
console.log("Book added to the store", request.result);
};
request.onerror = function() {
console.log("Error", request.error);
};
基本有四个步骤:
- 创建一个事务,在(1)表明要访问的所有存储。
- 使用
transaction.objectStore(name),在(2)中获取存储对象。 - 在(3)执行对对象库
books.add(book)的请求。 - ……处理请求 成功/错误(4),还可以根据需要发出其他请求。
对象库支持两种存储值的方法:
- put(value, [key]) 将
value添加到存储区。仅当对象库没有keyPath或autoIncrement时,才提供key。如果已经存在具有相同键的值,则将替换该值。 - add(value, [key]) 与
put相同,但是如果已经有一个值具有相同的键,则请求失败,并生成一个名为"ConstraInterror"的错误。
与打开数据库类似,我们可以发送一个请求:books.add(book),然后等待success/error事件。 add的request.result是新对象的键。- 错误在
request.error(如果有的话)中。
事务的自动提交
在上面的示例中,我们启动了事务并发出了 add 请求。但正如前面提到的,一个事务可能有多个相关的请求,这些请求必须全部成功或全部失败。那么我们如何将事务标记为已完成,并不再请求呢?
简短的回答是:没有。
在下一个版本 3.0 规范中,可能会有一种手动方式来完成事务,但目前在 2.0 中还没有。
当所有事务的请求完成,并且 微任务队列 为空时,它将自动提交。
通常,我们可以假设事务在其所有请求完成时提交,并且当前代码完成。
因此,在上面的示例中,不需要任何特殊调用即可完成事务。
事务自动提交原则有一个重要的副作用。不能在事务中间插入 fetch, setTimeout 等异步操作。IndexedDB 不会让事务等待这些操作完成。
在下面的代码中,request2 中的行 (*) 失败,因为事务已经提交,不能在其中发出任何请求:
let request1 = books.add(book);
request1.onsuccess = function() {
fetch('/').then(response => {
let request2 = books.add(anotherBook); // (*)
request2.onerror = function() {
console.log(request2.error.name); // TransactionInactiveError
};
});
};
这是因为 fetch 是一个异步操作,一个宏任务。事务在浏览器开始执行宏任务之前关闭。
IndexedDB 规范的作者认为事务应该是短期的。主要是性能原因。
值得注意的是,readwrite 事务将存储“锁定”以进行写入。因此,如果应用程序的一部分启动了 books 对象库上的 readwrite 操作,那么希望执行相同操作的另一部分必须等待新事务“挂起”,直到第一个事务完成。如果事务处理需要很长时间,将会导致奇怪的延迟。
那么,该怎么办?
在上面的示例中,我们可以在新请求 (*) 之前创建一个新的 db.transaction。
如果需要在一个事务中把所有操作保持一致,更好的做法是将 IndexedDB 事务和“其他”异步内容分开。
首先,执行 fetch,并根据需要准备数据。然后创建事务并执行所有数据库请求,然后就正常了。
为了检测到成功完成的时刻,我们可以监听 transaction.oncomplete 事件:
let transaction = db.transaction("books", "readwrite");
// ……执行操作……
transaction.oncomplete = function() {
console.log("Transaction is complete"); // 事务执行完成
};
只有 complete 才能保证将事务作为一个整体保存。个别请求可能会成功,但最终的写入操作可能会出错(例如 I/O 错误或其他错误)。
要手动中止事务,请调用:
transaction.abort();
取消请求里所做的所有修改,并触发 transaction.onabort 事件。
错误处理
写入请求可能会失败。
这是意料之中的事,不仅是我们可能会犯的粗心失误,还有与事务本身相关的其他原因。例如超过了存储配额。因此,必须做好请求失败的处理。
失败的请求将自动中止事务,并取消所有的更改。
在一些情况下,我们会想自己去处理失败事务(例如尝试另一个请求)并让它继续执行,而不是取消现有的更改。可以调用 request.onerror 处理程序,在其中调用 event.preventDefault() 防止事务中止。
在下面的示例中,添加了一本新书,键 (id) 与现有的书相同。store.add 方法生成一个 "ConstraInterror"。可以在不取消事务的情况下进行处理:
let transaction = db.transaction("books", "readwrite");
let book = { id: 'js', price: 10 };
let request = transaction.objectStore("books").add(book);
request.onerror = function(event) {
// 有相同 id 的对象存在时,发生 ConstraintError
if (request.error.name == "ConstraintError") {
console.log("Book with such id already exists"); // 处理错误
event.preventDefault(); // 不要中止事务
// 这个 book 用另一个键?
} else {
// 意外错误,无法处理
// 事务将中止
}
};
transaction.onabort = function() {
console.log("Error", transaction.error);
};
事件委托
每个请求都需要调用 onerror/onsuccess ?并不,可以使用事件委托来代替。
IndexedDB 事件冒泡:请求 → 事务 → 数据库。
所有事件都是 DOM 事件,有捕获和冒泡,但通常只使用冒泡阶段。
因此,出于报告或其他原因,我们可以使用 db.onerror 处理程序捕获所有错误:
db.onerror = function(event) {
let request = event.target; // 导致错误的请求
console.log("Error", request.error);
};
……但是错误被完全处理了呢?这种情况不应该被报告。
我们可以通过在 request.onerror 中使用 event.stopPropagation() 来停止冒泡,从而停止 db.onerror 事件。
request.onerror = function(event) {
if (request.error.name == "ConstraintError") {
console.log("Book with such id already exists"); // 处理错误
event.preventDefault(); // 不要中止事务
event.stopPropagation(); // 不要让错误冒泡, 停止它的传播
} else {
// 什么都不做
// 事务将中止
// 我们可以解决 transaction.onabort 中的错误
}
};
搜索
对象库有两种主要的搜索类型:
- 通过键值或键值范围。在我们的 “books” 存储中,将是
book.id的值或值的范围。 - 通过另一个对象字段,例如
book.price。这需要一个额外的数据结构,名为“索引(index)”。
通过 key 搜索
首先,让我们来处理第一种类型的搜索:按键。
支持精确的键值和被称为“值范围”的搜索方法 —— IDBKeyRange 对象,指定一个可接受的“键值范围”。
IDBKeyRange 对象是通过下列调用创建的:
IDBKeyRange.lowerBound(lower, [open])表示:≥lower(如果open是 true,表示>lower)IDBKeyRange.upperBound(upper, [open])表示:≤upper(如果open是 true,表示<upper)IDBKeyRange.bound(lower, upper, [lowerOpen], [upperOpen])表示: 在lower和upper之间。如果 open 为 true,则相应的键不包括在范围中。IDBKeyRange.only(key)—— 仅包含一个键的范围key,很少使用。
我们很快就会看到使用它们的实际示例。
要进行实际的搜索,有以下方法。它们接受一个可以是精确键值或键值范围的query参数:store.get(query)—— 按键或范围搜索第一个值。store.getAll([query], [count])—— 搜索所有值。如果count给定,则按count进行限制。store.getKey(query)—— 搜索满足查询的第一个键,通常是一个范围。store.getAllKeys([query], [count])—— 搜索满足查询的所有键,通常是一个范围。如果count给定,则最多为 count。store.count([query])—— 获取满足查询的键的总数,通常是一个范围。
例如,我们存储区里有很多书。因为id字段是键,因此所有方法都可以按id进行搜索。
请求示例:
// 获取一本书
books.get('js')
// 获取 'css' <= id <= 'html' 的书
books.getAll(IDBKeyRange.bound('css', 'html'))
// 获取 id < 'html' 的书
books.getAll(IDBKeyRange.upperBound('html', true))
// 获取所有书
books.getAll()
// 获取所有 id > 'js' 的键
books.getAllKeys(IDBKeyRange.lowerBound('js', true))
对象中对值的存储始终是有序的
对象内部存储的值是按键对值进行排序的。
因此,请求的返回值,是按照键的顺序排列的。
通过使用索引的字段搜索
要根据其他对象字段进行搜索,我们需要创建一个名为“索引(index)”的附加数据结构。
索引是存储的"附加项",用于跟踪给定的对象字段。对于该字段的每个值,它存储有该值的对象的键列表。下面会有更详细的图片。
语法:
objectStore.createIndex(name, keyPath, [options]);
name—— 索引名称。keyPath—— 索引应该跟踪的对象字段的路径(我们将根据该字段进行搜索)。option—— 具有以下属性的可选对象:unique—— 如果为true,则存储中只有一个对象在keyPath上具有给定值。如果我们尝试添加重复项,索引将生成错误。multiEntry—— 只有keypath上的值是数组时才使用。这时,默认情况下,索引将默认把整个数组视为键。但是如果multiEntry为 true,那么索引将为该数组中的每个值保留一个存储对象的列表。所以数组成员成为了索引键。
在我们的示例中,是按照id键存储图书的。
假设我们想通过price进行搜索。
首先,我们需要创建一个索引。它像对象库一样,必须在upgradeneeded中创建完成:
openRequest.onupgradeneeded = function() {
// 在 versionchange 事务中,我们必须在这里创建索引
let books = db.createObjectStore('books', {keyPath: 'id'});
let index = books.createIndex('price_idx', 'price');
};
- 该索引将跟踪
price字段。 - 价格不是唯一的,可能有多本书价格相同,所以我们不设置唯一
unique选项。 - 价格不是一个数组,因此不适用多入口
multiEntry标志。
假设我们的库存里有4本书。下面的图片显示了该索引index的确切内容:
如上所述,每个 price 值的索引(第二个参数)保存具有该价格的键的列表。
索引自动保持最新,所以我们不必关心它。
现在,当我们想要搜索给定的价格时,只需将相同的搜索方法应用于索引:

let transaction = db.transaction("books"); // 只读
let books = transaction.objectStore("books");
let priceIndex = books.index("price_idx");
let request = priceIndex.getAll(10);
request.onsuccess = function() {
if (request.result !== undefined) {
console.log("Books", request.result); // 价格为 10 的书的数组
} else {
console.log("No such books");
}
};
我们还可以使用 IDBKeyRange 创建范围,并查找 便宜/贵 的书:
// 查找价格 <=5 的书籍
let request = priceIndex.getAll(IDBKeyRange.upperBound(5));
在我们的例子中,索引是按照被跟踪对象字段价格 price 进行内部排序的。所以当我们进行搜索时,搜索结果也会按照价格排序。
从存储中删除
delete 方法查找要由查询删除的值,调用格式类似于 getAll
delete(query)—— 通过查询删除匹配的值。
例如:
// 删除 id='js' 的书
books.delete('js');
如果要基于价格或其他对象字段删除书。首先需要在索引中找到键,然后调用 delete:
// 找到价格 = 5 的钥匙
let request = priceIndex.getKey(5);
request.onsuccess = function() {
let id = request.result;
let deleteRequest = books.delete(id);
};
删除所有内容:
books.clear(); // 清除存储。
光标(Cursors)
像 getAll/getAllKeys 这样的方法,会返回一个 键/值 数组。
但是一个对象库可能很大,比可用的内存还大。这时,getAll 就无法将所有记录作为一个数组获取。
该怎么办呢?
光标提供了解决这一问题的方法。
光标是一种特殊的对象,它在给定查询的情况下遍历对象库,一次返回一个键/值,从而节省内存。
由于对象库是按键在内部排序的,因此光标按键顺序(默认为升序)遍历存储。
语法:
// 类似于 getAll,但带有光标:
let request = store.openCursor(query, [direction]);
// 获取键,而不是值(例如 getAllKeys):store.openKeyCursor
query是一个键值或键值范围,与getAll相同。direction是一个可选参数,使用顺序是:"next"—— 默认值,光标从有最小索引的记录向上移动。"prev"—— 相反的顺序:从有最大的索引的记录开始下降。"nextunique","prevunique"—— 同上,但是跳过键相同的记录 (仅适用于索引上的光标,例如,对于价格为 5 的书,仅返回第一本)。
光标对象的主要区别在于request.onSuccess多次触发:每个结果触发一次。
这有一个如何使用光标的例子:
let transaction = db.transaction("books");
let books = transaction.objectStore("books");
let request = books.openCursor();
// 为光标找到的每本书调用
request.onsuccess = function() {
let cursor = request.result;
if (cursor) {
let key = cursor.key; // 书的键(id字段)
let value = cursor.value; // 书本对象
console.log(key, value);
cursor.continue();
} else {
console.log("No more books");
}
};
主要的光标方法有:
advance(count)—— 将光标向前移动count次,跳过值。continue([key])—— 将光标移至匹配范围中的下一个值(如果给定键,紧接键之后)。
无论是否有更多的值匹配光标 —— 调用onsuccess。结果中,我们可以获得指向下一条记录的光标,或者undefined。
在上面的示例中,光标是为对象库创建的。
也可以在索引上创建一个光标。索引是允许按对象字段进行搜索的。在索引上的光标与在对象存储上的光标完全相同 —— 它们通过一次返回一个值来节省内存。
对于索引上的游标,cursor.key是索引键(例如:价格),我们应该使用cursor.primaryKey属性作为对象的键:
let request = priceIdx.openCursor(IDBKeyRange.upperBound(5));
// 为每条记录调用
request.onsuccess = function() {
let cursor = request.result;
if (cursor) {
let primaryKey = cursor.primaryKey; // 下一个对象存储键(id 字段)
let value = cursor.value; // 下一个对象存储对象(book 对象)
let key = cursor.key; // 下一个索引键(price)
console.log(key, value);
cursor.continue();
} else {
console.log("No more books"); // 没有书了
}
};
Promise 包装器
将 onsuccess/onerror 添加到每个请求是一项相当麻烦的任务。我们可以通过使用事件委托(例如,在整个事务上设置处理程序)来简化我们的工作,但是 async/await 要方便的多。
在本章,我们会进一步使用一个轻便的承诺包装器 https://github.com/jakearchibald/idb 。它使用 promisified IndexedDB 方法创建全局 idb 对象。
然后,我们可以不使用 onsuccess/onerror,而是这样写:
let db = await idb.openDB('store', 1, db => {
if (db.oldVersion == 0) {
// 执行初始化
db.createObjectStore('books', {keyPath: 'id'});
}
});
let transaction = db.transaction('books', 'readwrite');
let books = transaction.objectStore('books');
try {
await books.add(...);
await books.add(...);
await transaction.complete;
console.log('jsbook saved');
} catch(err) {
console.log('error', err.message);
}
现在我们有了可爱的“简单异步代码”和「try…catch」捕获的东西。
错误处理
如果我们没有捕获到错误,那么程序将一直失败,直到外部最近的 try..catch 捕获到为止。
未捕获的错误将成为 window 对象上的“unhandled promise rejection”事件。
我们可以这样处理这种错误:
window.addEventListener('unhandledrejection', event => {
let request = event.target; // IndexedDB 本机请求对象
let error = event.reason; // 未处理的错误对象,与 request.error 相同
// ……报告错误……
});
“非活跃事务”陷阱
我们都知道,浏览器一旦执行完成当前的代码和 微任务 之后,事务就会自动提交。因此,如果我们在事务中间放置一个类似 fetch 的宏任务,事务只是会自动提交,而不会等待它执行完成。因此,下一个请求会失败。
对于 promise 包装器和 async/await,情况是相同的。
这是在事务中间进行 fetch 的示例:
let transaction = db.transaction("inventory", "readwrite");
let inventory = transaction.objectStore("inventory");
await inventory.add({ id: 'js', price: 10, created: new Date() });
await fetch(...); // (*)
await inventory.add({ id: 'js', price: 10, created: new Date() }); // 错误
fetch (*) 后的下一个 inventory.add 失败,出现“非活动事务”错误,因为这时事务已经被提交并且关闭了。
解决方法与使用本机 IndexedDB 时相同:进行新事务,或者将事情分开。
- 准备数据,先获取所有需要的信息。
- 然后保存在数据库中。
获取本机对象
在内部,包装器执行本机 IndexedDB 请求,并添加 onerror/onsuccess 方法,并返回 rejects/resolves 结果的 promise。
在大多数情况下都可以运行, 示例在这 https://github.com/jakearchibald/idb。
极少数情况下,我们需要原始的 request 对象。可以将 promise 的 promise.request 属性,当作原始对象进行访问:
let promise = books.add(book); // 获取 promise 对象(不要 await 结果)
let request = promise.request; // 本地请求对象
let transaction = request.transaction; // 本地事务对象
// ……做些本地的 IndexedDB 的处理……
let result = await promise; // 如果仍然需要